
Даже у опытных пользователей WordPress иногда возникают вопросы по грамотной настройке файла robots.txt Для вас сегодня ультимативное руководство от компании Yoast которая наверняка известна многим по самому популярному SEO плагину — . Ну кому же еще как не им рассказать нам об этом пресловутом файлике. Перед вами полный перевод авторской статьи. Вникайте, друзья!
Файл robots.txt — это один из главных способов, сказать поисковым системам, куда им можно заходить на вашем сайте, а куда нет. Все основные поисковики поддерживают главную функциональность, которую он предлагает. Также есть несколько дополнительных правил, которые используются поисковиками и могут вам пригодиться. Этот гайд поможет вам научиться с robots.txt.
Что такое robots.txt?
Robots.txt – это текстовый файл, который следует строгому синтаксису, благодаря которому поисковые роботы могут читать его. Синтаксис строгий, так как его должен понимать компьютер. Никого чтения между строк — либо, 1, либо 0. Называемый также «протоколом исключений для роботов» файл robots.txt — это результат договоренности между первыми разработчиками поисковых ботов. Хоть и не существует никакого официального стандарта, предложенного какой-либо организацией, крупнейшие поисковые системы соблюдают этот протокол.
Что делает файл robots.txt?
Поисковые системы индексируют страницы, существующие в интернете, сканируя их своими ботами. Они следуют ссылкам, чтоб переходить с одного сайта на другой. Перед тем, как просканировать какую-либо страницу с помощью бота, на домене, с которым поисковая система никогда не сталкивалась ранее, открывается файл robots.txt, принадлежащий домену. Файл robots.txt говорит поисковикам, какие URL сайта можно индексировать. Поисковая система будет не только кэшировать контент robots.txt, но и освежать его множество раз в день. Так что изменения будут отражаться очень быстро.
Куда мне положить мой файл robots.txt?
Файл robots.txt всегда должен находиться в «корне» вашего домена. Если ваш домен www.example.com, то файл должен находиться по адресу http://www.example.com/robots.txt. Предупреждаем: если домен не содержит www, то убедитесь в том, что то же самое происходит и с файлом robots.txt. Это правило должно соблюдаться и для http и https. Когда поисковик хочет прощупать URL http://example.com/test, он захватывает http://example.com/robots.txt. Когда же он хочет прощупать тот же URL , но с https, он захватывает robots.txt с https-версии вашего сайта, которая должна выглядеть так https://example.com/robots.txt. Также важно, чтоб ваш файл назывался именно robots.txt, так как это название очень чувствительное, и нельзя делать в нем ошибки, в противном случае не будет работать.
Плюсы и минусы использования robots.txt
Плюс: бюджет сканирования
Каждый сайт имеет «разрешение» на определенное количество страниц, которое бот может просканировать на этом ресурсе, SEO называет этот показатель бюджетом сканирования. Если вы блокируете какую-то часть сайта, не позволяя ее сканировать, вы сохраняете этот бюджет для других областей сайта. Особенно это ценно для сайтов, где много работы по SEO-оптимизации.
Минус: страница не удаляется из результатов поисковой выдачи
Используя файл robots.txt, вы можете сказать боту, куда ему не стоит лезть на вашем сайте. Но вы не можете указать поисковику, какие URL нельзя показывать в поисковой выдаче. Это значит, что, не позволяя поисковику сканировать «заблокированный» URL, вы не исключаете URL из результатов поиска. Если поисковик находит достаточно ссылок на какой-то URL, то он включит его в результаты поиска. При это он не будет знать, что на этой странице.
Если вы хотите гарантировано убрать страницу из результатов поиска, вам нужно использовать мета тег noindex. Это значит, когда поисковик наткнется на тег — noindex, то он поймет, что страницу не нужно блокировать, используя robots.txt.
Минусы: не распространяется ценность ссылки
Так как поисковая система не может просканировать страницу, то она не может и распространить ссылочную ценность на ссылки ваших блокированных страниц. Если поисковик может просканировать страницы без их индексации, то ссылочная ценность может распространиться на все ссылки, найденные на этих страницах. Когда страница заблокирована с помощью robots.txt, ссылочная ценность просто пропадает.
Синтаксис robots.txt
Файл robots.txt состоит из одного или более блоков директив, каждый из которых начинается строчкой, в начале которой стоит user-agent. “User-agent” – это название определенного поискового робота, которому адресована директива. Вы также можете создать только один блок для всех поисковиков, используя шаблон для user-agent, или же специфические блоки для определенных поисковых систем. Бот поисковой системы всегда подцепит этот специфический блок, который ему адресован. Блоки выглядят вот так:
User-agent: * Disallow: / User-agent: Googlebot Disallow: User-agent: bingbot Disallow: /not-for-bing/
Директивы, типа Allow и Disallow не особо чувствительны к изменению регистра, так что не важно, как писать – капсом или строчными буквами. Но значения – чувствительны, так что /photo/ — это не то же самое, что /Photo/. Нам нравится писать директивы с большой буквы, чтоб они лучше читались.
Директивы User-agent
Первое звено каждого блока директив — это user-agent. User-agent идентифицирует определенного бота. Поле user-agent находится напротив user-agent специфического бота. Например, самый распространенный бот от Google имеет следующий user-agent:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Сравнительно простая строка User-agent: Googlebot сделает за вас всю работу, если вы хотите, рассказать данному «пауку», что тот должен делать.
Заметим, что у большинства поисковых систем есть множество ботов, которые используются для обычной индексации, индексации рекламных объявлений, картинок, видео и т. д.
Поисковые системы всегда выбирают самый подходящий блок директив, из всех предложенных. Допустим, у вас есть три блока директив: один для *, другой для Googlebot и третий для Googlebot-News. Если у бота указан user-agent Googlebot-Video, то он выберет ограничения Googlebot. Бот с user-agent Googlebot-News будет использовать директивы Googlebot-News
Вот вам список самых распространенных user agent для ботов поисковых систем:
| Search engine | Field | User-agent |
|---|---|---|
| Baidu | General | baiduspider |
| Baidu | Images | baiduspider-image |
| Baidu | Mobile | baiduspider-mobile |
| Baidu | News | baiduspider-news |
| Baidu | Video | baiduspider-video |
| Bing | General | bingbot |
| Bing | General | msnbot |
| Bing | Images & Video | msnbot-media |
| Bing | Ads | adidxbot |
| General | Googlebot |
|
| Images | Googlebot-Image |
|
| Mobile | Googlebot-Mobile |
|
| News | Googlebot-News |
|
| Video | Googlebot-Video |
|
| AdSense | Mediapartners-Google |
|
| AdWords | AdsBot-Google |
|
| Yahoo! | General | slurp |
| Yandex | General | yandex |
Директива Disallow
Вторая строчка каждого блока директив – это строка Disallow. Вы можете использовать одну или несколько таких строк, указывая какие области сайта не могут сканировать определенные боты. Пустая строка Disallow значит, что вы не запретили ничего, и бот может сканировать весь сайт.
User-agent: * Disallow: /
Пример, приведенный ниже способен заблокировать все поисковики, которые «прислушиваются» к robots.txt
User-agent: * Disallow:
Пример выше, в котором убран всего лишь один символ, позволит поисковикам сканировать весь сайт
User-agent: googlebot Disallow: /Photo
Пример выше запретит Google сканировать папку с картинками и все, что в ней есть. Это значит, что все подкатегории также будут заблокированы. Нужно писать именно /Photo, а не просто photo, так как здесь регистр имеет значение.
Как использовать шаблоны/регулярные выражения
«Официально» стандарт robots.txt не поддерживает регулярные выражения или шаблоны. Но как бы то ни было, все поисковики понимают их. Это значит, вы можете иметь подобные строки для блокировки групп файлов:
Disallow: /*.php Disallow: /copyrighted-images/*.jpg
В примере выше * позволяет захватить все то, что соответствует имени файла. Заметим, что остаток строки все еще чувствителен к выбранному регистру, так что строка выше не будет блокировать файл, который называется /copyrighted-images/example.JPG
Некоторые поисковики, например, Google, позволяют еще больше усложнить регулярные выражения, но все ж не все поисковые системы улавливают данную логику. Самая полезная функция – это добавление $, что означает окончание URL. Данный пример иллюстрирует применение этой функции:
Disallow: /*.php$
Это значит, что /index.php не будет индексироваться, а /index.php?p=1 как раз будет индексироваться. Естественно, это может пригодиться только в определенных обстоятельствах, и несет в себе определенную опасность: просто разблокировать то, что вы, в общем, не хотите что было разблокировано.
Не стандартизированные директивы сканирования robots.txt
Кроме директив Disallow и User-agent есть еще парочка директив, которые вы можете использовать. Эти директивы не поддерживаются ботами всех поисковиков, так что имейте это в виду.
Директива Allow
Кажется, что большинство поисковиков понимают данную директиву, не смотря на то, что ее нет в оригинальной «спецификации». Кроме того она позволяет создавать очень простые и читабельные команды типа этой:
Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Единственный способ добиться того же самого без использования директивы allow – это отключить от индексации каждый файл в папке wp-admin по отдельности.
Директива noindex
Это одна из тех менее известных директив, которую поддерживает Google. Мы думаем, что это довольно опасная штука. Если вы хотите извлечь какую-либо страницу из результатов поиска, то у вас, должно быть, есть на это веские причины. Данные метод позволяет исключить какую-либо страницу только из поля зрения поисковика Google, в то время как она все еще открыта другим поисковым машинам. Заметим, что Google поддерживает noindex неофициально, так что если это работает сейчас, то не факт что будет работать потом.
Директива host
Директива поддерживается Yandex, но не поддерживается Google. Она позволяет вам решить, какую версию сайта должен выдавать поиск: example.com или www.example.com. Вот как выглядит этот трюк:
host: example.com
Так как только Yandex поддерживает эту директиву, то не стоит на нее особо полагаться. Лучшее решение, которое будет работать для всех поисковиков – это использование 301 редиректа. В нашем случае мы используем данный редирект для перенаправления с www.yoast.com на yoast.com.
Директива crawl-delay
Так как данная директива поддерживается Yahoo!, Bing и Yandex, она может быть очень полезна для того, чтоб придержать эту троицу, часто слишком голодную до сканирования всего подряд на вашем сайте.
Столкнувшись с данной строкой Yahoo! и Bing будут ждать 10 секунд после проведенного сканирования. Yandex будет получать доступ к вашему сайту один раз в 10 секунд. Вот пример, такой строки с директивой crawl-delay:
crawl-delay: 10
Стоит заметить, что если вы установите 10-ти секундную задержку сканирования, то вы позволите поисковым системам индексировать 8,640 страниц в день. Казалось бы это очень много для небольшого сайта, но в тоже время это мелочь для крупного ресурса.
Директива sitemap для XML карт сайта
Используя данную директиву, вы можете сказать определенным поисковикам — Bing, Yandex и Google – где находится ваша XML карта сайта. Также вы можете послать ваши XML карты каждому поисковику, используя инструменты веб-мастера каждой поисковой системы. Если же вы не хотите использовать инструменты веб-мастера, то просто добавьте соответствующую строку в ваш robots.txt
Валидация вашего robots.txt
Существует множество различных инструментов, которые позволят вам валидировать ваш robots.txt, но когда дело касается валидации директив сканирования, мы используем инструмент для тестирования robots.txt от Google, который находится в Google Search Console (под Crawl menu):
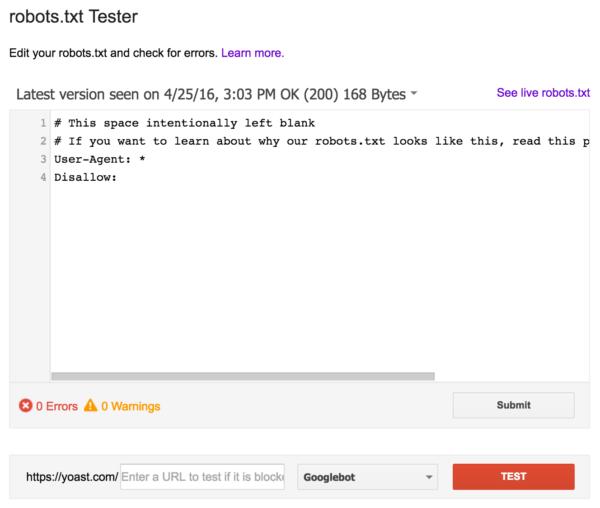
Перед тем, как пустить в ход свой обновленный robots.txt, обязательно протестируйте все изменения, чтоб не закрыть от индексации весь сайт.
Источник:

![]() Robots.txt — как с ним бороться?, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Robots.txt — как с ним бороться?, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Респект и уважуха
