
Прокси‑сервер — это приложение, которое действует как посредник запросов между клиентом, который хочет скрыть свой родной IP‑адрес, и сервером назначения, с которого клиент запрашивает определенную услугу (HTTP, SSL и т. д.).
При использовании прокси‑сервера на пути прямого подключения к серверу назначения стоит прокси‑сервер, куда и направляется запрос всего, что хотите получить, где он анализируется, передаётся серверу назначения, далее выполняется, а результат выполнения сервером назначения возвращается клиенту по схеме взятой из Википедии и показанной ниже:
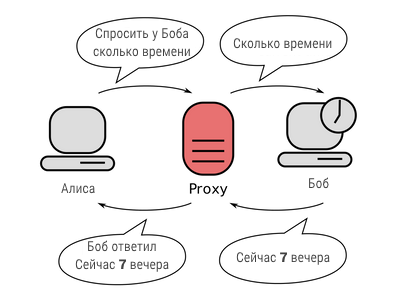
Что-бы избежать блокировки своего IP‑адреса веб‑сервером назначения при парсинге частенько приходится используют несколько прокси. Ещё у прокси‑серверов есть ряд других достоинств, в том числе обход фильтров и цензуры, скрытие своего реального IP‑адреса и т. д., и т. п.
Здесь вы узнаете, как использовать Python для прокси‑подключения с помощью библиотеки , кроме того, я буду использовать библиотеку , которая является библиотекой контроллера Python для Tor. Установим их из своего терминала (в Windows cmd):
pip3 install bs4 requests stem
Использование бесплатных прокси
Во-первых, есть несколько веб‑сайтов, которые предлагают список бесплатных прокси. Вот вам функция для автоматического получения подобного списка:
import requests
import random
from bs4 import BeautifulSoup as bs
def get_free_proxies():
url = "https://free-proxy-list.net/"
# получаем ответ HTTP и создаем объект soup
soup = bs(requests.get(url).content, "html.parser")
proxies = []
for row in soup.find("table", attrs={"id": "proxylisttable"}).find_all("tr")[1:]:
tds = row.find_all("td")
try:
ip = tds[0].text.strip()
port = tds[1].text.strip()
host = f"{ip}:{port}"
proxies.append(host)
except IndexError:
continue
return proxies
free_proxies = get_free_proxies()
print(f'Обнаружено бесплатных прокси - {len(free_proxies)}:')
for i in range(len(free_proxies)):
print(f"{i+1}) {free_proxies[i]}")
Получилось вот это:
Обнаружено бесплатных прокси - 300: 1) 218.253.39.60:80 2) 5.252.161.48:8080 3) 151.232.72.14:80 ˙ ˙ ˙ 298) 87.236.212.97:8080 299) 36.90.164.90:8181 300) 103.227.255.43:80 >>>
Однако, когда вы попытаетесь использовать сервера из списка, большинства из них вылетит по тайм-ауту. На самом деле, подобные списки недолговечны и большинство полученных прокси перестанут работать ещё до того, как вы дочитаете эту статью (поэтому, в реальной жизни приходится применять указанную выше функцию каждый раз, когда понадобятся новые прокси-серверы).
Следующая функция принимает список прокси и создает сеанс запросов, который случайным образом выбирает один из переданных прокси:
def get_session(proxies):
# создать HTTP‑сеанс
session = requests.Session()
# выбираем один случайный прокси
proxy = random.choice(proxies)
session.proxies = {"http": proxy, "https": proxy}
return session
Проверим отправив запрос на веб‑сайт, который возвращает наш IP‑адрес:
for i in range(5):
s = get_session(proxies)
try:
print("Страница запроса с IP:", s.get("http://icanhazip.com", timeout=1.5).text.strip())
except Exception as e:
continue
Вот мой результат:
Страница запроса с IP: 45.64.134.198 Страница запроса с IP: 141.0.70.211 Страница запроса с IP: 94.250.248.230 Страница запроса с IP: 46.173.219.2 Страница запроса с IP: 201.55.164.177
Как видите, это некоторые IP‑адреса рабочих прокси-серверов, а не наш реальный IP‑адрес (попробуйте посетить этот веб‑сайт в своем браузере, и вы увидите свой реальный IP‑адрес).
Бесплатные прокси, как правило, умирают очень быстро, в основном за дни или даже за часы, и часто умирают до того, как закончится наш проект. Чтобы предотвратить такую ситуацию для крупномасштабных проектов по извлечению данных, нужно использовать прокси премиум-класса. Существует множество провайдеров, которые меняют IP‑адреса за вас. Одно из хорошо известных решений — Crawlera. Мы поговорим об этом подробнее в последнем разделе этой статьи.
Использование Tor в качестве прокси
Для смены IP‑адресов можно использовать сеть Tor:
import requests
from stem.control import Controller
from stem import Signal
def get_tor_session():
# инициализировать сеанс запросов
session = requests.Session()
# установка прокси для http и https на localhost: 9050
# для этого требуется запущенная служба Tor на вашем компьютере и прослушивание порта 9050 (по умолчанию)
session.proxies = {"http": "socks5://localhost:9050", "https": "socks5://localhost:9050"}
return session
def renew_connection():
with Controller.from_port(port=9051) as c:
c.authenticate()
# отправить сигнал NEWNYM для установления нового чистого соединения через сеть Tor
c.signal(Signal.NEWNYM)
if __name__ == "__main__":
s = get_tor_session()
ip = s.get("http://icanhazip.com").text
print("IP:", ip)
renew_connection()
s = get_tor_session()
ip = s.get("http://icanhazip.com").text
print("IP:", ip)
Примечание. Приведенный выше код должен работать только в том случае, если на вашем компьютере установлен Tor (перейдите по и правильно его установить) и правильно настроен (ControlPort 9051 включен, см. ).
Таким образом, будет создан сеанс с IP‑адресом Tor и сделан HTTP‑запрос. Затем обновим соединение, отправив сигнал NEWNYM (который сообщает Tor установить новое чистое соединение), чтобы изменить IP‑адрес и сделать еще один запрос, вот результат:
IP: 185.220.101.49 IP: 109.70.100.21
Великолепно! Однако, когда вы попробуете парсить в сети Tor, то скоро поймете, что в подавляющем большинстве случаев скорость оставляет желать лучшего. Поэтому перейдем к более продуктивному методу.
Использование Crawlera
Crawlera от Scrapinghub позволяет сканировать быстро и надежно, сервис по‑умному управляет подключением прокси‑серверов в одном сеансе и, если вас забанят, то он это автоматически обнаружит и изменит за вас IP‑адрес.
Crawlera — это интеллектуальная прокси‑сеть, специально разработанная для парсинга и сканирования веб‑страниц. Его задача ясна: облегчить жизнь парсера, помогает получать успешные запросы и извлекать данные в любом масштабе с любого веб‑сайта с помощью любого инструмента для парсинга.

Благодаря простому API запрос, который делается при парсинге, будет перенаправляться через пул высококачественных прокси. При необходимости он автоматически создаёт задержки между запросами и удаляет/добавляет IP‑адреса для решения различных проблем сканирования.
Вот как можно использовать Crawlera с библиотекой requests в Python:
import requests
url = "http://icanhazip.com"
proxy_host = "proxy.crawlera.com"
proxy_port = "8010"
proxy_auth = "<APIKEY>:"
proxies = {
"https": f"https://{proxy_auth}@{proxy_host}:{proxy_port}/",
"http": f"http://{proxy_auth}@{proxy_host}:{proxy_port}/"
}
r = requests.get(url, proxies=proxies, verify=False)
После регистрации вы получите ключ API, котором подставите в качестве значения для proxy_auth.
Итак, вот что происходит с Crawlera:
- Вы отправляете HTTP‑запрос, используя API единой конечной точки.
- Он автоматически выбирает, подменяет, ограничивает и заносит в черный список IP‑адреса для получения целевых данных.
- Он обрабатывает заголовки запросов и поддерживает сеансы. В результате ваш запрос для конечной точки всегда будет успешным.
Заключение
Существует несколько типов прокси, включая бесплатные прокси, анонимные прокси, элитные прокси. Если ваша цель использования прокси — не дать веб‑сайтам блокировать ваши парсеры, то элитные прокси — оптимальный выбор, для веб‑сайта вы станете похожи на обычного пользователя, который вообще не знает, что такое прокси.
Более того, дополнительная анти-мера очистки — это использование ротационных пользовательских агентов, в которых вы каждый раз отправляете изменяющийся поддельный заголовок, говоря, что вы обычный браузер.
Наконец, Crawlera экономит ваше время и энергию, автоматически управляя прокси-серверами, а также предоставляет 14-дневную бесплатную пробную версию, так что вы можете просто попробовать ее без какого-либо риска. Если вам нужно прокси-решение, то настоятельно рекомендую вам попробовать .
Рекомендую для полного понимания вопроса: Как с помощью в Python извлечь все ссылки на веб‑сайты.
По мотивам

![]() Как в Python использовать прокси для подмены IP‑адресов, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Как в Python использовать прокси для подмены IP‑адресов, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Респект и уважуха
