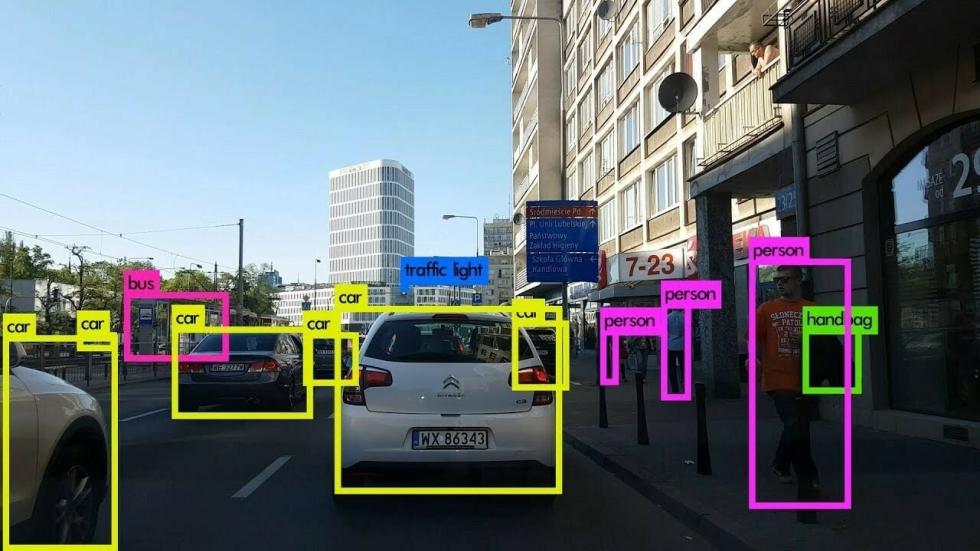
— это задача компьютерного зрения и обработки изображений, которая связана с обнаружением объектов на изображениях или видео. Сейчас решения подобного рода задач актуальны в самых разных реальных приложениях, включая видеонаблюдение, беспилотные автомобили, отслеживание объектов и т. д.
Например, для того, чтобы автомобиль был действительно автономным, он должен понимать и отслеживать окружающие его объекты (такие как автомобили, пешеходы и светофоры), и основным источником информации для этого является камера. Более того, чтобы автомобиль мог безопасно перемещаться по улице, очень важно, обнаруживать объекты в режиме реального времени.
В этом уроке вы узнаете, как найти и обнаружить объекты с помощью современной техники YOLO v3 с OpenCV или PyTorch в Python.
Содержание
YOLO (You Only Look Once, что в нашем контексте на русском означает с единственного взгляда) — это алгоритм обнаружения объектов в реальном времени, который представляет собой одну глубокую сверточную нейронную сеть, которая разбивает входное изображение на набор ячеек, образующих сетку, поэтому, в отличие от классификации изображений или обнаружения лиц, каждая ячейка сетки в алгоритме YOLO в выходных данных будет иметь связанный вектор, который сообщает нам:
- Присутствует ли объект в ячейке сетки.
- Класс объекта (т.е. метка).
- Предполагаемые геометрические характеристики объекта (местоположения).
Существуют и другие подходы, такие как , , которые используют скользящие по изображению окна, что требует тысячи прогнозов для одного изображения (в каждом окне), как вы можете догадаться, это делает YOLO v3 примерно в 1000 раз быстрее, чем R‑CNN, и в 100 раз быстрее, чем Fast R‑CNN.
YOLO v3 — последняя версия YOLO, в которой используется несколько приемов для улучшения обучаемости и повышения производительности. Подробные сведения см. в статье .
Начало без проблем ↑
Прежде чем мы погрузимся в код, давайте установим необходимые библиотеки для наших упражнений (если вы хотите использовать код PyTorch, ознакомьтесь с ):
pip3 install opencv-python numpy matplotlib
Довольно сложно строить всю систему YOLO v3 (модель и используемые методы) с нуля. Библиотеки с открытым исходным кодом, такие как Darknet или OpenCV значительно упрощают этот процесс и уже многое сделали для вас. Так, что даже некоторые простые человеки уже реализовали свои проекты для YOLO v3 (посмотрите, как сделано для TensorFlow. 2 реализация)
Импорт необходимых модулей:
import cv2 import numpy as np import time import sys import os
Давайте определим некоторые переменные и параметры, которые нам понадобятся:
CONFIDENCE = 0.5
SCORE_THRESHOLD = 0.5
IOU_THRESHOLD = 0.5
# конфигурация нейронной сети
config_path = "cfg/yolov3.cfg"
# файл весов сети YOLO
weights_path = "weights/yolov3.weights"
# weights_path = "weights/yolov3-tiny.weights"
# загрузка всех меток классов (объектов)
labels = open("data/coco.names").read().strip().split("\n")
# генерируем цвета для каждого объекта и последующего построения
colors = np.random.randint(0, 255, size=(len(LABELS), 3), dtype="uint8")
Мы инициализировали наши параметры, но поговорим о них позже. config_path и weights_path представляют собой соответственно конфигурацию модели (это YOLO v3) и соответствующие предварительно обученные веса модели. labels — это список всех меток классов для различных объектов. Каждый класс объекта при обнаружении нарисуем уникальным цветом, для чего генерируем случайные цвета.
За необходимыми файлами, пожалуйста, обратитесь к этому , а поскольку файл весов очень большой (около 240 МБ) и в репозитории его нет, загрузите его .
Приведенный ниже код загружает модель:
# загружаем сеть YOLO net = cv2.dnn.readNetFromDarknet(config_path, weights_path)
Подготовка изображения ↑
Загрузим пример изображения (изображение есть в ):
path_name = "images/street.jpg"
image = cv2.imread(path_name)
file_name = os.path.basename(path_name)
filename, ext = file_name.split(".")
Затем нам нужно нормализовать, масштабировать и изменить это изображение, чтобы оно подходило в качестве входных данных для нейронной сети:
h, w = image.shape[:2] # создать 4D blob blob = cv2.dnn.blobFromImage(image, 1/255.0, (416, 416), swapRB=True, crop=False)
Здесь происходит нормализация значения пикселей в диапазоне от 0 до 1 и изменяется размер изображения до (416, 416) с изменит его формы, давайте посмотрим:
print("image.shape:", image.shape)
print("blob.shape:", blob.shape)
Результат:
image.shape: (1200, 1800, 3) blob.shape: (1, 3, 416, 416)
Прогнозирование ↑
Теперь загрузим изображение в нейронную сеть и получим прогноз на выходе:
# устанавливает blob как вход сети
net.setInput(blob)
# получаем имена всех слоев
ln = net.getLayerNames()
ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]
# прямая связь (вывод) и получение выхода сети
# измерение времени для обработки в секундах
start = time.perf_counter()
layer_outputs = net.forward(ln)
time_took = time.perf_counter() - start
print(f"Потребовалось: {time_took:.2f}s")
У меня получилось, что для извлечения выходных данных нейронной сети потребовалось:
Потребовалось: 1.54s
Возникает резонный вопрос, почему всё не так быстро? 1,5 секунды — это довольно медленно? Что ж, мы использовали наш ЦП только для вывода, а для реальных задач это совсем не идеально. Поэтому немного позже перейдем к PyTorch. С другой стороны, 1,5 секунды — это относительно хорошо по сравнению с другими методами, такими как R‑CNN. Вы также можете использовать крохотную версию YOLO v3, которая работает намного быстрее, но менее точна. Её можно скачать .
Теперь нам нужно перебрать выходные данные нейронной сети и отбросить все объекты, уровень достоверности идентификации которых меньше, чем параметр CONFIDENCE, указанный нами ранее (т.е. 0,5 или 50%).
font_scale = 1
thickness = 1
boxes, confidences, class_ids = [], [], []
# перебираем каждый из выходов слоя
for output in layer_outputs:
# перебираем каждое обнаружение объекта
for detection in output:
# извлекаем идентификатор класса (метку) и достоверность (как вероятность)
# обнаружение текущего объекта
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
# отбросьте слабые прогнозы, убедившись, что обнаруженные
# вероятность больше минимальной вероятности
if confidence > CONFIDENCE:
# масштабируем координаты ограничивающего прямоугольника относительно
# размер изображения, учитывая, что YOLO на самом деле
# возвращает центральные координаты (x, y) ограничивающего
# поля, за которым следуют ширина и высота поля
box = detection[:4] * np.array([w, h, w, h])
(centerX, centerY, width, height) = box.astype("int")
# используем центральные координаты (x, y) для получения вершины и
# и левый угол ограничительной рамки
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# обновить наш список координат ограничивающего прямоугольника, достоверности,
# и идентификаторы класса
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
class_ids.append(class_id)
Здесь перебираются все прогнозы и сохраняются объекты с высокой степенью достоверности, давайте посмотрим, что представляет собой вектор обнаружения:
print(detection.shape)
Результат:
(85,)
В каждом прогнозе объекта есть вектор из 85 элементов. Первые 4 значения представляют местоположение объекта, координаты (x, y) для центральной точки, а также ширину и высоту ограничивающего прямоугольника, остальные числа соответствуют меткам объектов. Поскольку это набор данных , он имеет 80 меток классов.
Например, если обнаруженный объект — человек, первое значение в векторе длины 80 должно быть 1, а все остальные значения должны быть 0, число 2 для велосипеда, 3 для автомобиля, вплоть до 80-го объекта. Вот почему мы используем функцию np.argmax() для получения идентификатора класса, поскольку она возвращает индекс максимального значения из этого вектора длиной 80.
Отрисовываем обнаруженные объекты ↑
Теперь у нас есть все, что нужно и мы сможем нарисовать прямоугольники объектов и метки. Посмотрим на результат:
# перебираем сохраняемые индексы
for i in range(len(boxes)):
# извлекаем координаты ограничивающего прямоугольника
x, y = boxes[i][0], boxes[i][1]
w, h = boxes[i][2], boxes[i][3]
# рисуем прямоугольник ограничивающей рамки и подписываем на изображении
color = [int(c) for c in colors[class_ids[i]]]
cv2.rectangle(image, (x, y), (x + w, y + h), color=color, thickness=thickness)
text = f"{labels[class_ids[i]]}: {confidences[i]:.2f}"
# вычисляем ширину и высоту текста, чтобы рисовать прозрачные поля в качестве фона текста
(text_width, text_height) = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, fontScale=font_scale, thickness=thickness)[0]
text_offset_x = x
text_offset_y = y - 5
box_coords = ((text_offset_x, text_offset_y), (text_offset_x + text_width + 2, text_offset_y - text_height))
overlay = image.copy()
cv2.rectangle(overlay, box_coords[0], box_coords[1], color=color, thickness=cv2.FILLED)
# добавить непрозрачность (прозрачность поля)
image = cv2.addWeighted(overlay, 0.6, image, 0.4, 0)
# теперь поместите текст (метка: доверие%)
cv2.putText(image, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX,
fontScale=font_scale, color=(0, 0, 0), thickness=thickness)
Подпишем изображение:
cv2.imwrite(filename + "_yolo3." + ext, image)
В текущем каталоге появится новое изображение, которое уверенно маркирует каждый обнаруженный объект. Однако посмотрите на эту часть изображения:

Как вы уже догадались, две ограничивающие рамки для одного объекта, это проблема, не так ли? Что ж, создатели YOLO для её решения использовали технику под названием Non-maximal Suppression (Немаксимальное подавление).
Non-maximal Suppression ↑
Non-maximal Suppression — метод, который подавляет перекрывающиеся ограничивающие прямоугольники, у которых вероятности для обнаружения объекта меньше максимальной. В основном это достигается в два этапа:
- Выбираем ограничивающую рамку с наибольшей достоверностью (то есть вероятностью).
- Затем сравниваем её с вероятностями всех других ограничивающих прямоугольников и удаляем те, которые имеют высокий IoU.
Что такое IoU ↑
IoU (Intersection over Union или пересечение над объединением) — это метод, используемый в Non-maximal Suppression для сравнения того, насколько близки два разных ограничивающих прямоугольника. Это просто показано на следующем рисунке:
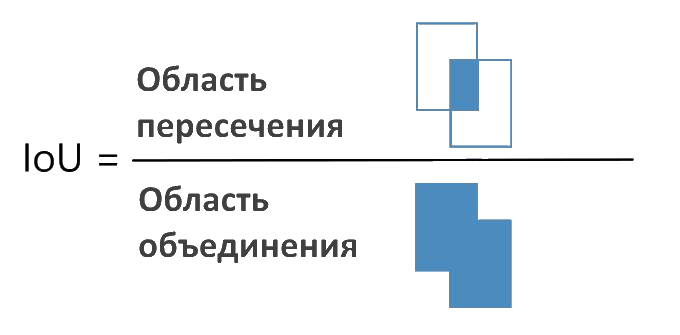
Чем выше IoU, тем ближе ограничивающие рамки. IoU, равное 1, означает, что две ограничивающие рамки совпали, а IoU, равное 0, означает, что они даже не пересекаются.
В результате мы будем использовать пороговое значение IoU 0,5 (которое задано в начале урока) и это означает, что будет удалятся любая ограничивающая рамка со значением ниже значения ограничивающей рамки с максимальной вероятностью.
SCORE_THRESHOLD удалит любую ограничивающую рамку, которая имеет достоверность ниже этого значения:
# выполнить не максимальное подавление с учетом оценок, определенных ранее idxs = cv2.dnn.NMSBoxes(boxes, confidences, SCORE_THRESHOLD, IOU_THRESHOLD)
Теперь давайте снова нарисуем рамки:
# убедитесь, что обнаружен хотя бы один объект
if len(idxs) > 0:
# перебираем сохраняемые индексы
for i in idxs.flatten():
# извлекаем координаты ограничивающего прямоугольника
x, y = boxes[i][0], boxes[i][1]
w, h = boxes[i][2], boxes[i][3]
# рисуем прямоугольник ограничивающей рамки и подписываем на изображении
color = [int(c) for c in colors[class_ids[i]]]
cv2.rectangle(image, (x, y), (x + w, y + h), color=color, thickness=thickness)
text = f"{labels[class_ids[i]]}: {confidences[i]:.2f}"
# вычисляем ширину и высоту текста, чтобы определить прозрачные поля в качестве фона текста
(text_width, text_height) = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, fontScale=font_scale, thickness=thickness)[0]
text_offset_x = x
text_offset_y = y - 5
box_coords = ((text_offset_x, text_offset_y), (text_offset_x + text_width + 2, text_offset_y - text_height))
overlay = image.copy()
cv2.rectangle(overlay, box_coords[0], box_coords[1], color=color, thickness=cv2.FILLED)
# добавить непрозрачность (прозрачность поля)
image = cv2.addWeighted(overlay, 0.6, image, 0.4, 0)
# теперь поместим текст (метка: доверие%)
cv2.putText(image, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX,
fontScale=font_scale, color=(0, 0, 0), thickness=thickness)
Вы можете использовать cv2.imshow("image", image) и показать изображение, но мы просто сохраним его на диск:
cv2.imwrite(filename + "_yolo3." + ext, image)
Получите, распишитесь:

Вот еще один пример изображения:

Или это:

Потрясающие! Теперь используйте свои собственные изображения, настройте параметры и посмотрите, что лучше всего работает!
Кроме того, если изображение имеет высокое разрешение, убедитесь, что вы увеличили параметр font_scale, чтобы увидеть ограничивающие прямоугольники и соответствующие им метки.
Код PyTorch ↑
Как упоминалось ранее, если вы хотите использовать графический процессор для вывода (который намного быстрее, чем центральный процессор), то можете попробовать библиотеку PyTorchએ, которая поддерживает вычисления CUDA, вот код для этого (получите и из репозитория):
import cv2
import matplotlib.pyplot as plt
from utils import *
from darknet import Darknet
# Установить порог NMS
nms_threshold = 0.6
# Установить порог IoU
iou_threshold = 0.4
cfg_file = "cfg/yolov3.cfg"
weight_file = "weights/yolov3.weights"
namesfile = "data/coco.names"
m = Darknet(cfg_file)
m.load_weights(weight_file)
class_names = load_class_names(namesfile)
# m.print_network()
original_image = cv2.imread("images/city_scene.jpg")
original_image = cv2.cvtColor(original_image, cv2.COLOR_BGR2RGB)
img = cv2.resize(original_image, (m.width, m.height))
# обнаруживаем объекты
boxes = detect_objects(m, img, iou_threshold, nms_threshold)
# вычерчиваем изображение с ограничивающими рамками и соответствующими метками классов объектов
plot_boxes(original_image, boxes, class_names, plot_labels=True)
Примечание. Для приведенного выше кода требуются файлы darknet.py и utils.py в текущем каталоге. Также должен быть установлен PyTorch (рекомендуется ускорение на GPU).
Заключение ↑
Я подготовил для вас код использования видеокамеры для обнаружения объектов в реальном времени, посмотрите файл live_yolo_opencv.py.
Кроме того, если вы хотите прочитать видеофайл и выполнить обнаружение объекта на нем, то код из файла read_video.py вам поможет.
Вот пример работы этого скрипта, для которого я взял заставку с сайта группы . Результатом я не очень доволен, но это объясняется тем, что использован рисованный мультик и у искусственного интеллекта просто сносит крышу от человечьего художественного творчества — конфликт, понимаешь, интеллекта искусственного с естественным. Судите сами:
Обратите внимание, что есть некоторые недостатки детектора объектов YOLO, один из основных недостатков заключается в том, что YOLO изо всех сил пытается обнаружить объекты, сгруппированные близко друг к другу, особенно более мелкие. Существуют также , где часто наблюдается компромисс между скоростью и точностью.
Для этого урока использованы коды из следующих источников:
Есть несколько проектов и репозиториев с решениями подобных задач, и если вы хотите использовать TensorFlow 2 вместо показанного здесь, то я рекомендую вам .
Ознакомьтесь с официальным руководством по YOLO .
Использованы материалы

![]() Как обнаруживать объекты, используя YOLO, OpenCV и PyTorch в Python, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Как обнаруживать объекты, используя YOLO, OpenCV и PyTorch в Python, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
1 нравится это
