
Мне часто приходится говорить, что для понимания проще нарисовать, лучше всего нарисовать. В подавляющем большинстве случаев, после того, как всё стало понятно, остальное не так и сложно, становится делом техники. То же самое и в науке о данных, и этап, на котором всё «понимается» называется Exploratory Data Analysis (EDA) или разведочный анализ данныхએ. EDA играет важнейшую роль после получения набора данных и ставит своей целью выяснить, как с ним работать и получить требуемый результат.
Итак, в этой статье познакомлю новичков с EDA. Не волнуйтесь, всё когда-то впервые и если вы только что узнали, что EDA существует, то к концу статьи вы будете иметь четкое представление обо всех основных моментах, связанных с EDA и вместе с тем увидите пошаговые практические примеры кодирования. Давайте разбираться!
Что такое разведочный анализ данных?
Разведочный анализ данных, Exploratory Data Analysis (EDA) — один из первых и определяющих шагов проекта науки о данных, который приводит в движение весь проект. Он придает проекту конкретное направление и формирует план его реализации.
Разведочный анализ данных означает изучение данных до самых глубин для получения из них практической информации. Он включает в себя анализ и обобщение массивных наборов данных, часто в форме диаграмм и графиков.
Следовательно и бесспорно это самый важный этап в проекте науки о данных, по собственному опыту знаю, что он всегда занимает 70-80% времени всего проекта. Чем лучше вы знаете свой набор данных, тем лучше вы сможете его использовать! Чтобы лучше понять, какое место EDA занимает во всем процессе анализа данных, вот вам иллюстрация:

Думается, что теперь у вас появилось чёткое представление о месте, занимаемое EDA и вы готовы погрузиться в подробности!
EDA — краткий обзор
Кратко определим этапы, которые включает EDA, после приведу практические примеры, в которых используем различные методы EDA на реальном наборе данных.
Хотя методы EDA следует применять в соответствии с ситуацией и доступными типами данных, я постараюсь сделать это, используя основные приемы, которые вам нужно знать как новичку и которые являются фундаментом в анализе данных. Посмотрим:
Что такое одномерный анализ?
Как следует из названия, одномерный анализ — это когда анализ переменных выполняется по отдельности. Независимо от того, является ли переменная категориальной или непрерывной, если мы анализируем ее независимо от других переменных, то это называется одномерным анализом.
Вот некоторые из основных методов одномерного анализа:
- ;
- Дисперсия;
Что такое двумерный анализ
Двумерный анализ относится к изучению взаимосвязи между любыми двумя переменными в наборе данных. Это может быть связь между любыми двумя переменными‑предикторами или с целевой переменной. Такие отношения, если они существуют, могут вызвать проблемы во время разработки модели, например, шум.
Некоторые из методов, используемых для двумерного анализа:
- ;
- ;
- .
Практический пример кодирования
Хватит разговоров, пора перейти к реальному примеру, где можно увидеть, чего стоит EDA при разработке практической модели машинного обучения. Я буду использовать набор данных StudentsPerformane, который вы можете найти вместе с кодами всех примеров из этой статьи на Яндекс.Диск . Задача состоит в том, чтобы предсказать успеваемость учащихся на основе определенных факторов, определяющих их опыт. Однако цель этого урока — выполнить EDA с учетом набора данных и модели.
Начнём с импорта необходимых библиотек и чтения данных.
Импорт библиотек
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import matplotlib as mpl mpl.rcParams.update(mpl.rcParamsDefault)
Загрузка набора данных
data = pd.read_csv("StudentsPerformance-ru.csv")
Можно использовать функцию df.head в Pandas для просмотра фрейма данных следующим образом:
# Выведем первые 10 строк # Наш фрейм данных называется data, поэтому мы вызываем data.head(10) и # печатаем результат print(data.head(10))
Вот как выглядит наш результат:
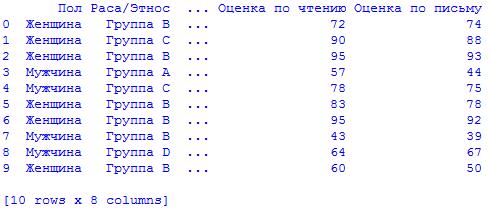
Оценка столбцов/поиск недостающих значений
Как видим, в прочитанном наборе всего 8 столбцов. Чтобы получить более подробное представление, давайте воспользуемся функцией df.info и узнаем больше о столбцах, с которыми мы имеем дело:
data.info()
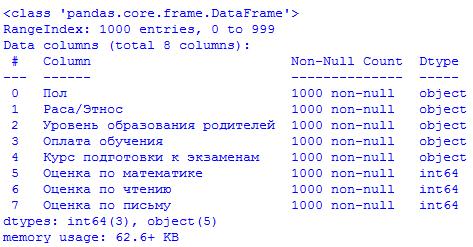
Итак, у нас есть три поля типа int, а остальные поля типа object. Приведенная выше информация очень помогает, когда мы применяем различные вычисления на уровне столбца.
Следующим по важности шагом является обнаружение недостающих значений, которые обязаны у нас быть. Если мы это сделаем, то нужно будет соответствующим образом действовать на дальнейших этапах разработки. На этом этапе EDA нам не обязательно иметь дело с пропущенными значениями, но нам нужно понять их, чтобы мы могли побороться с ними позже.
data.isnull().sum()

Нам повезло и в нашем наборе данных нет пропущенных значений. Это случается очень нечасто, но когда это случается, то действительно повезло!
Однако, если бы были пропущенные значения, что бы вы сделали? Поступить можно по-разному и либо отбросить отсутствующие значения, если их немного, либо заполнить их средними или медианными значениями с помощью функции Pandas data.fillna().
Одномерный анализ
Теперь пришло время для быстрой визуализации, чтобы увидеть, какие группы и категории входят в наши данные.
Сначала мы исследуем соотношение мужчин и женщин в наборе данных.
sns.set_style('darkgrid')
sns.countplot(y='Пол',data=data,palette='colorblind')
plt.xlabel('Количество')
plt.ylabel('Пол')
plt.show()
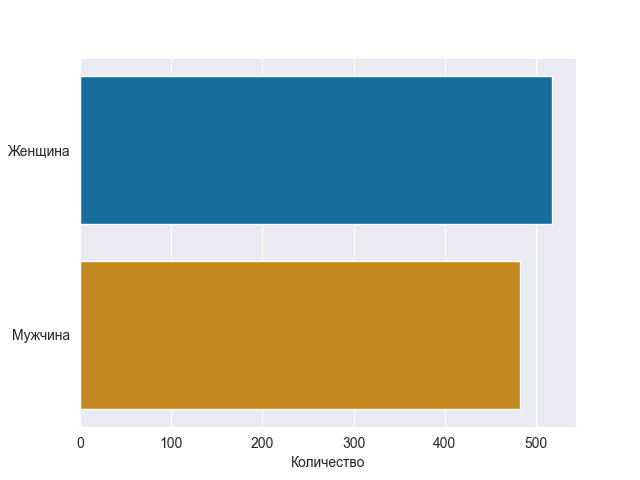
График seaborn довольно точно отражает разделение данных на мужчин и женщин. Вот более точная версия подсчета:
female_count = len(data[data['Пол']=='Женщина'])
male_count = len(data) - female_count
print("\n Всего женщин:",female_count,"\n","Всего мужчин:",male_count)
![]()
Вот и не знаю теперь, зачем нам так интересно знать соотношение полов? Важно одно — в нашем наборе данных почти одинаково встречаются представители обоих полов, в модели, которую мы разрабатываем с использованием этого набора данных, не нужно беспокоиться о каких-либо гендерных предподчтениях.
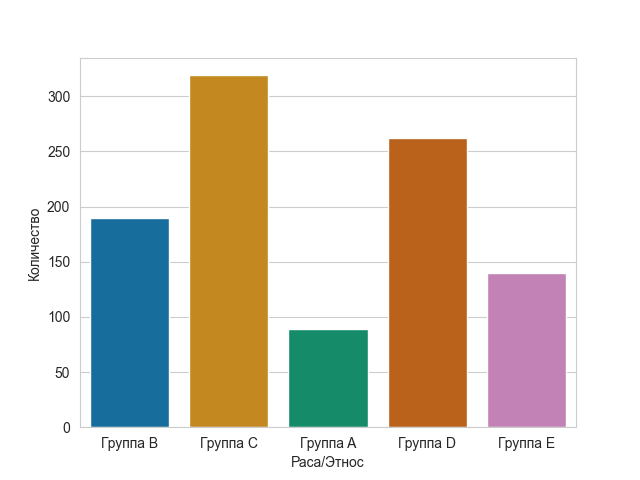
Теперь давайте посмотрим, как данные делят учащихся на разные расы или этнические группы. Будем следовать той же процедуре, что и на предыдущем шаге. График можно построить с помощью следующего кода:
sns.set_style('whitegrid')
sns.countplot(x='Раса/Этнос',data=data,palette='colorblind')
plt.xlabel("Раса/Этнос")
plt.ylabel("Количество")
plt.show()
Вот как он выглядит:
Затем мы сделаем то же самое, чтобы изучить распределение для 'Уровень образования родителей'. Посмотрим, что у нас там есть.
sns.set_style('whitegrid')
sns.countplot(y='Уровень образования родителей',data=data,palette='colorblind')
plt.xlabel('Количество')
plt.ylabel('Раса/Этнос')
plt.show()
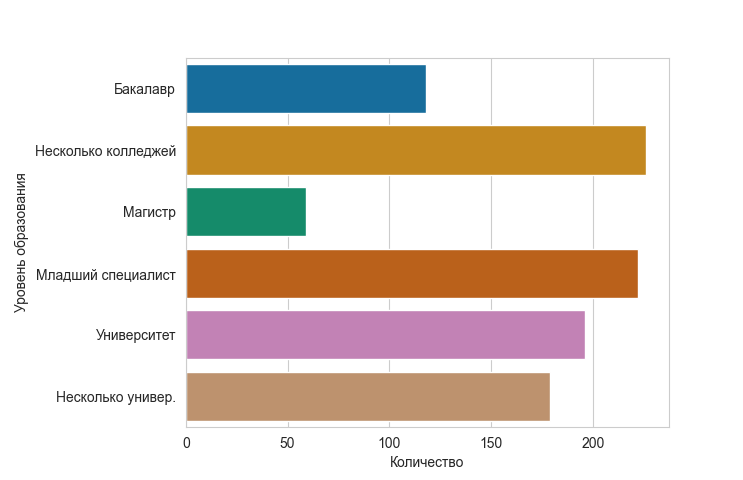
Это говорит нам о том, что у большинства родителей есть как минимум степень младшего специалиста.
Двумерный анализ
Далее мы исследуем, есть ли какая-либо корреляция (зависимость) между отдельными функциями (столбцами), которые нам необходимо учитывать. Некоторые модели, такие как Наи́вный ба́йесовский классифика́торએ, используют допущение об отсутствии корреляции между отдельными характеристиками, поэтому этот шаг имеет решающее значение.
Итак, давайте построим диаграммы рассеяния для различных комбинаций предметов.
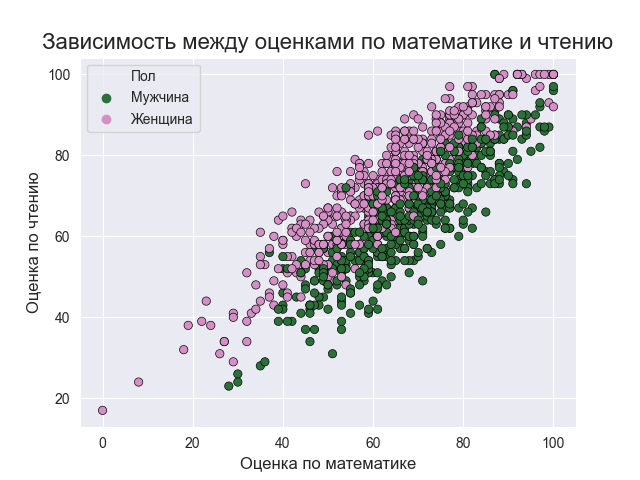
Вот код:
sns.set_style('darkgrid')
plt.title('Зависимость между оценками по математике и чтению',size=16)
plt.xlabel('Оценка по математике',size=12)
plt.ylabel('Оценка по чтению',size=12)
sns.scatterplot(x='Оценка по математике', y='Оценка по чтению', data=data, hue='Пол', edgecolor='black', palette='cubehelix', hue_order=['Мужчина','Женщина'])
plt.show()
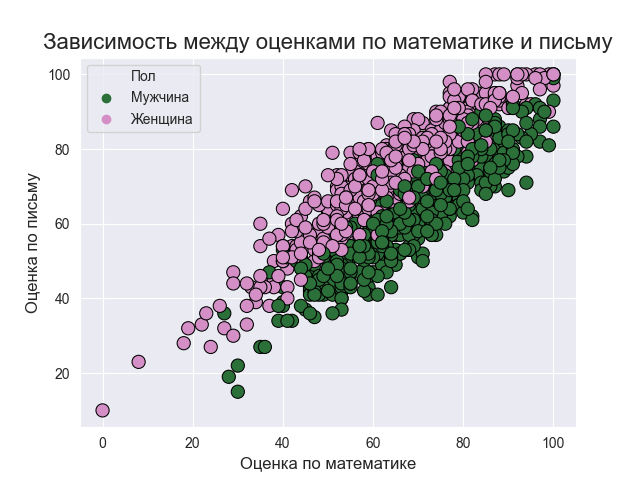
Вот код:
plt.title('Зависимость между оценками по математике и письму',size=16)
plt.xlabel('Оценка по математике',size=12)
plt.ylabel('Оценка по письму',size=12)
sns.scatterplot(x='Оценка по математике', y='Оценка по письму', data=data, hue='Пол', s=90, edgecolor='black', palette='cubehelix', hue_order=['Мужчина','Женщина'])
plt.show()
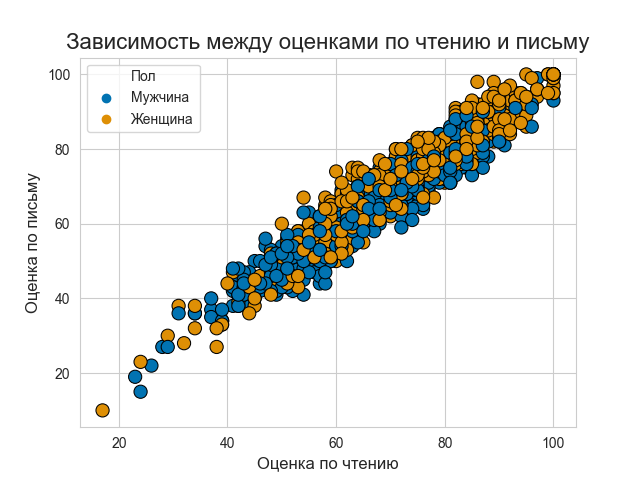
Вот код:
sns.set_style('whitegrid')
plt.title('Зависимость между оценками по чтению и письму',size=16)
plt.xlabel('Оценка по чтению',size=12)
plt.ylabel('Оценка по письму',size=12)
sns.scatterplot(x='Оценка по чтению', y='Оценка по письму', data=data, hue='Пол', s=90, edgecolor='black', palette='colorblind',hue_order=['Мужчина','Женщина'])
plt.show()
Итак, диаграмма рассеянияએ предполагает высокую степень корреляции между оценками учащихся по разным предметам. Оценки учащихся по математике и (чтению, письму) мало разбросаны, но, как правило, они показывают рост, поэтому, если ученик набирает больше по математике, то он или она также обычно набирает больше по другим предметам. С другой стороны, зависимость оценок по чтению и письму более сгруппирована вдоль прямой линии.
Подобный анализ многое говорит нам о важности EDA, ведь если бы не EDA на получение такого результата ушли бы часы.
Мы знаем, что «интегральная оценка» — это обобщенный показатель, рассчитанный на основе значений измерений и характеризующий конкретный набор данных. Поэтому, с технической точки зрения, она всегда вызывает особый интерес: какое из измерений больше всего влияет на её значение.
Чтобы это выяснить, построим еще один график, :
total_marks = ((data['Оценка по математике'] + data['Оценка по чтению'] + data['Оценка по письму'])/300)*100
data['Интегральная оценка'] = total_marks
kde_data = data[ ['Оценка по математике','Оценка по чтению','Оценка по письму','Интегральная оценка'] ]
sns.set_style("darkgrid")
sns.kdeplot(data=kde_data,shade=True, palette='colorblind')
plt.show()
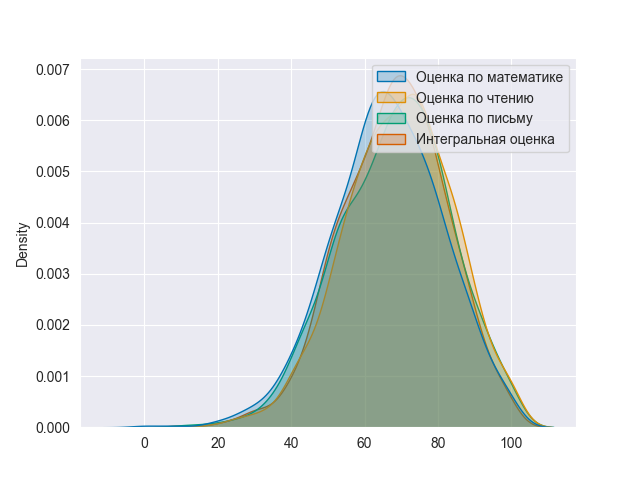
Совершенно очевидно, что почти все предметы в одинаковой степени влияют на общий балл. Таким образом, нам не нужно рассматривать какую-либо конкретную функцию, влияющую на Интегральную оценку больше, чем другие.
На сегодня все, ребята! Хотя EDA на этом не заканчивается и есть еще много чего, что надо знать, но это уже другая история. А теперь пора убедиться, что вы сможете реализовать это самостоятельно для понимания истинной сущности EDA. Архив с набором данных и код, использованные в это статье находятся .
В заключение
EDA, Exploratory Data Analysis или разведочный анализ данных — один из важнейших этапов проекта в области науки о данных. Он не только помогает определить направление проекта, но также помогает использовать набор данных наилучшим образом.
На протяжении всей статьи мы видели все основные концепции, задействованные в типичном процессе EDA. Кроме того, мы прошли пошаговую реализацию некоторых основных практик EDA с использованием практического набора данных.
Однако, это только начало. По мере продвижения вы обнаружите, что мир EDA гораздо более разнообразен и детализирован. Лучший способ научиться — попробовать выполнить собственный EDA на некоторых из .
По мотивам

![]() Разведочный анализ данных в Python: руководство для новичков на 2021 год, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Разведочный анализ данных в Python: руководство для новичков на 2021 год, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Респект и уважуха
