
Получение всех ссылок на веб-странице — обычная задача для веб-парсеров, полезно создавать продвинутые парсеры, которые сканируют каждую страницу определенного веб-сайта для извлечения данных, его также можно использовать для процесса диагностики SEO или даже на этапе сбора информации для проникновения. тестеры. Здесь узнаете, как создать инструмент для извлечения ссылок на Python с нуля, используя только библиотеки и .
Установим зависимости:
pip3 install requests bs4 colorama
Мы будем использовать для удобного выполнения HTTP-запросов, для синтаксического анализа HTML и для изменения цвета текста.
Откройте новый файл, назовем его link_extractor.py и следуйте инструкциям, импортируем необходимые нам модули:
import requests from urllib.parse import urlparse, urljoin from bs4 import BeautifulSoup import colorama
Мы собираемся использовать colorama только для раскраски текста при печати, чтобы различать внутренние и внешние ссылки:
# инициализация модуля colorama colorama.init() GREEN = colorama.Fore.GREEN GRAY = colorama.Fore.LIGHTBLACK_EX RESET = colorama.Fore.RESET YELLOW = colorama.Fore.YELLOW
Нам понадобятся две глобальные переменные, одна для всех внутренних ссылок сайта, а другая для всех внешних ссылок:
# инициализация наборов для ссылок (обеспечивается уникальность ссылок) internal_urls = set() external_urls = set()
internal_urls— URL-адреса, которые ведут на другие страницы того же веб-сайта.external_urls— URL-адреса, которые ведут на другие веб-сайты.
Поскольку не все ссылки в тегах привязки (теги) действительны, я это проверял, некоторые из них являются ссылками на части веб-сайта, некоторые — javascript, поэтому напишем функцию для проверки URL-адресов:
def is_valid(url):
"""
Проверяет, является ли 'url' действительным URL
"""
parsed = urlparse(url)
return bool(parsed.netloc) and bool(parsed.scheme)
Признаком истинности ссылки являются наличие в URL-адресе правильной scheme (протокола, например http или https) и имени домена netloc.
Теперь создадим функцию для возврата всех действительных URL-адресов веб-страницы:
def get_all_website_links(url):
"""
Возвращает все URL-адреса, найденные на `url`, в котором он принадлежит тому же веб-сайту.
"""
# все URL-адреса `url`
urls = set()
# доменное имя URL без протокола
domain_name = urlparse(url).netloc
soup = BeautifulSoup(requests.get(url).content, "html.parser")
Во-первых, я инициализировал переменную набора URL-адресов, здесь я использовал set Python, потому как нам не нужны повторяющиеся ссылки.
Во-вторых, я извлек доменное имя из URL-адреса, которое нам понадобится, для проверки, является ли полученная ссылка внешней или внутренней.
В третьих, я загрузил HTML-содержимое веб-страницы и обернул его объектом soup для облегчения синтаксического анализа HTML.
Получим все HTML-теги a (теги привязки, содержащие все ссылки веб-страницы):
for a_tag in soup.findAll("a"):
href = a_tag.attrs.get("href")
if href == "" or href is None:
# href пустой тег
continue
Поскольку не все ссылки являются абсолютными, нам нужно объединить относительные URL-адреса с их доменными именами (например, когда href равно «/search», а url — «google.com», результатом будет «google.com/search»):
# присоединяемся к URL, если он относительный (не абсолютная ссылка)
href = urljoin(url, href)
Теперь нам нужно удалить GET-параметры HTTP из URL-адресов, поскольку это приведет к избыточности в наборе, приведенный ниже код обрабатывает это:
parsed_href = urlparse(href)
# удалить GET-параметры URL, фрагменты URL и т. д.
href = parsed_href.scheme + "://" + parsed_href.netloc + parsed_href.path
Завершим функцию:
if not is_valid(href):
# недействительный URL
continue
if href in internal_urls:
# уже в наборе
continue
if domain_name not in href:
# внешняя ссылка
if href not in external_urls:
print(f"{GRAY}[!] Внешняя ссылка: {href}{RESET}")
external_urls.add(href)
continue
print(f"{GREEN}[*] Внутренняя ссылка: {href}{RESET}")
urls.add(href)
internal_urls.add(href)
return urls
Все, что мы здесь сделали, это проверили:
- Если URL-адрес недействителен, перейдите к следующей ссылке.
- Если URL-адрес уже находится в
internal_urls, нам это тоже не нужно. - Если URL-адрес является внешней ссылкой, распечатайте ее серым цветом и добавьте в наш глобальный набор
external_urlsи перейдите к следующей ссылке.
Наконец, после всех проверок URL будет внутренней ссылкой, мы распечатываем его и добавляем в наши наборы urls и internal_urls.
Вышеупомянутая функция будет захватывать только ссылки одной конкретной страницы, что, если мы хотим извлечь все ссылки всего веб-сайта? Давай сделаем это:
# number of urls visited so far will be stored here
total_urls_visited = 0
def crawl(url, max_urls=30):
"""
Сканирует веб-страницу и извлекает все ссылки.
Вы найдете все ссылки в глобальных переменных набора external_urls и internal_urls.
параметры:
max_urls (int): максимальное количество URL-адресов для сканирования, по умолчанию - 30.
"""
global total_urls_visited
total_urls_visited += 1
print(f"{YELLOW}[*] Проверено: {url}{RESET}")
links = get_all_website_links(url)
for link in links:
if total_urls_visited > max_urls:
break
crawl(link, max_urls=max_urls)
Эта функция сканирует веб-сайт, что означает, что она получает все ссылки первой страницы, а затем рекурсивно вызывает себя, чтобы перейти по всем ранее извлеченным ссылкам. Однако это может вызвать некоторые проблемы, программа будет зависать на крупных веб-сайтах (на которых есть много ссылок), таких как google.com, в результате, был добавлен параметр max_urls для выхода, когда мы достигаем определенного количества проверенных URL.
Хорошо, давайте проверим это, используя известный вам url:
if __name__ == "__main__":
crawl('https://waksoft.susu.ru')
print("[+] Итого внутренних ссылок:", len(internal_urls))
print("[+] Итого внешних ссылок:", len(external_urls))
print("[+] Итого URL:", len(external_urls) + len(internal_urls))
print("[+] Всего просканировано URL:", max_urls)
Тестирую на этом сайте. Однако я настоятельно рекомендую вам не делать этого, так как это вызовет много запросов и приведет к переполнению кэша веб-сервера, что может заблокировать ваш IP-адрес.
Вот часть вывода:
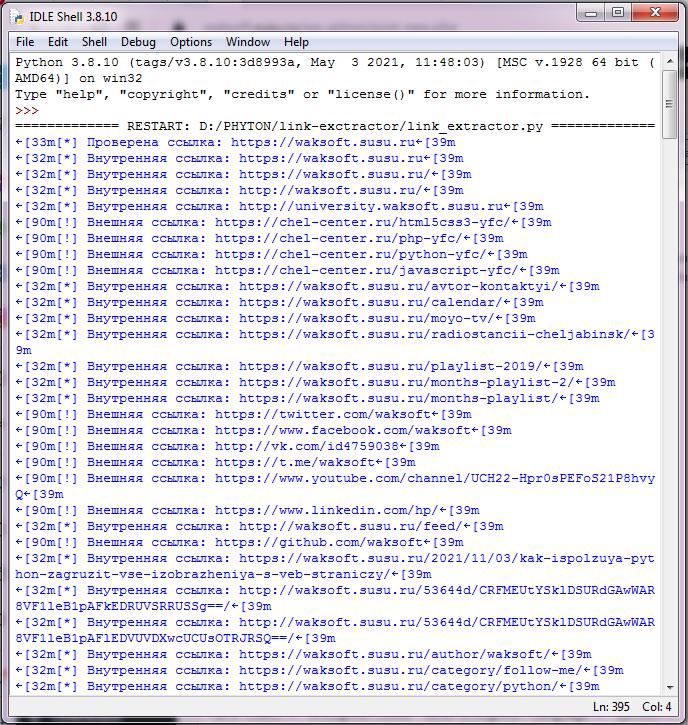
После завершения сканирования будет выведено общее количество извлеченных и просканированных ссылок:
[+] Итого внутренних ссылок: 211 [+] Итого внешних ссылок: 144 [+] Итого URL: 355 [+] Всего проверено URL: 30
Классно, правда? Я надеюсь, что это руководство было для вас полезным и вдохновило вас на создание таких инструментов с использованием Python.
Вот полный код утилиты для автономной работы:
import requests
from urllib.parse import urlparse, urljoin
from bs4 import BeautifulSoup
import colorama
# запускаем модуль colorama
colorama.init()
GREEN = colorama.Fore.GREEN
GRAY = colorama.Fore.LIGHTBLACK_EX
RESET = colorama.Fore.RESET
YELLOW = colorama.Fore.YELLOW
# инициализировать набор ссылок (уникальные ссылки)
internal_urls = set()
external_urls = set()
total_urls_visited = 0
def is_valid(url):
"""
Проверяет, является ли url действительным URL
"""
parsed = urlparse(url)
return bool(parsed.netloc) and bool(parsed.scheme)
def get_all_website_links(url):
"""
Возвращает все URL-адреса, найденные на `url`, в котором он принадлежит тому же веб-сайту.
"""
# все URL-адреса `url`
urls = set()
# доменное имя URL без протокола
domain_name = urlparse(url).netloc
soup = BeautifulSoup(requests.get(url).content, "html.parser")
for a_tag in soup.findAll("a"):
href = a_tag.attrs.get("href")
if href == "" or href is None:
# href пустой тег
continue
# присоединяемся к URL, если он относительный (не абсолютная ссылка)
href = urljoin(url, href)
parsed_href = urlparse(href)
# удалить GET-параметры URL, фрагменты URL и т. д.
href = parsed_href.scheme + "://" + parsed_href.netloc + parsed_href.path
if not is_valid(href):
# недействительный URL
continue
if href in internal_urls:
# уже в наборе
continue
if domain_name not in href:
# внешняя ссылка
if href not in external_urls:
print(f"{GRAY}[!] Внешняя ссылка: {href}{RESET}")
external_urls.add(href)
continue
print(f"{GREEN}[*] Внутренняя ссылка: {href}{RESET}")
urls.add(href)
internal_urls.add(href)
return urls
def crawl(url, max_urls=30):
"""
Сканирует веб-страницу и извлекает все ссылки.
Вы найдете все ссылки в глобальных переменных набора external_urls и internal_urls.
параметры:
max_urls (int): максимальное количество URL-адресов для сканирования, по умолчанию - 30.
"""
global total_urls_visited
total_urls_visited += 1
print(f"{YELLOW}[*] Проверена ссылка: {url}{RESET}")
links = get_all_website_links(url)
for link in links:
if total_urls_visited > max_urls:
break
crawl(link, max_urls=max_urls)
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="Инструмент получения ссылок на web-странице")
parser.add_argument("url", help="URL, по которому надо получить все ссылки")
parser.add_argument("-m", "--max-urls", help="Максимальное количество получаемых ссылок URL, по умолчанию 30.", default=30, type=int)
args = parser.parse_args()
url = args.url
max_urls = args.max_urls
crawl(url, max_urls=max_urls)
print("[+] Итого внутренних ссылок:", len(internal_urls))
print("[+] Итого внешних ссылок:", len(external_urls))
print("[+] Итого URL:", len(external_urls) + len(internal_urls))
print("[+] Всего проверено URL:", max_urls)
domain_name = urlparse(url).netloc
# сохраняем внутренние ссылки в файл
with open(f"{domain_name}_internal_links.txt", "w") as f:
for internal_link in internal_urls:
print(internal_link.strip(), file=f)
# сохраняем внешние ссылки в файл
with open(f"{domain_name}_external_links.txt", "w") as f:
for external_link in external_urls:
print(external_link.strip(), file=f)
Есть некоторые веб-сайты, которые загружают большую часть своего контента с помощью JavaScript, в результате нам нужно вместо этого использовать библиотеку request_html, которая позволяет нам выполнять Javascript с помощью Chromium. Я уже написал для этого сценарий, добавив всего несколько строк (поскольку request_html очень похож на requests), посмотрите.
from requests_html import HTMLSession
from urllib.parse import urlparse, urljoin
from bs4 import BeautifulSoup
import colorama
# init the colorama module
colorama.init()
GREEN = colorama.Fore.GREEN
GRAY = colorama.Fore.LIGHTBLACK_EX
RESET = colorama.Fore.RESET
YELLOW = colorama.Fore.YELLOW
# initialize the set of links (unique links)
internal_urls = set()
external_urls = set()
total_urls_visited = 0
def is_valid(url):
"""
Checks whether `url` is a valid URL.
"""
parsed = urlparse(url)
return bool(parsed.netloc) and bool(parsed.scheme)
def get_all_website_links(url):
"""
Returns all URLs that is found on `url` in which it belongs to the same website
"""
# all URLs of `url`
urls = set()
# domain name of the URL without the protocol
domain_name = urlparse(url).netloc
# initialize an HTTP session
session = HTMLSession()
# make HTTP request & retrieve response
response = session.get(url)
# execute Javascript
try:
response.html.render()
except:
pass
soup = BeautifulSoup(response.html.html, "html.parser")
for a_tag in soup.findAll("a"):
href = a_tag.attrs.get("href")
if href == "" or href is None:
# href empty tag
continue
# join the URL if it's relative (not absolute link)
href = urljoin(url, href)
parsed_href = urlparse(href)
# remove URL GET parameters, URL fragments, etc.
href = parsed_href.scheme + "://" + parsed_href.netloc + parsed_href.path
if not is_valid(href):
# not a valid URL
continue
if href in internal_urls:
# already in the set
continue
if domain_name not in href:
# external link
if href not in external_urls:
print(f"{GRAY}[!] External link: {href}{RESET}")
external_urls.add(href)
continue
print(f"{GREEN}[*] Internal link: {href}{RESET}")
urls.add(href)
internal_urls.add(href)
return urls
def crawl(url, max_urls=30):
"""
Crawls a web page and extracts all links.
You'll find all links in `external_urls` and `internal_urls` global set variables.
params:
max_urls (int): number of max urls to crawl, default is 30.
"""
global total_urls_visited
total_urls_visited += 1
print(f"{YELLOW}[*] Crawling: {url}{RESET}")
links = get_all_website_links(url)
for link in links:
if total_urls_visited > max_urls:
break
crawl(link, max_urls=max_urls)
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="Link Extractor Tool with Python")
parser.add_argument("url", help="The URL to extract links from.")
parser.add_argument("-m", "--max-urls", help="Number of max URLs to crawl, default is 30.", default=30, type=int)
args = parser.parse_args()
url = args.url
max_urls = args.max_urls
crawl(url, max_urls=max_urls)
print("[+] Total Internal links:", len(internal_urls))
print("[+] Total External links:", len(external_urls))
print("[+] Total URLs:", len(external_urls) + len(internal_urls))
print("[+] Total crawled URLs:", max_urls)
domain_name = urlparse(url).netloc
# save the internal links to a file
with open(f"{domain_name}_internal_links.txt", "w") as f:
for internal_link in internal_urls:
print(internal_link.strip(), file=f)
# save the external links to a file
with open(f"{domain_name}_external_links.txt", "w") as f:
for external_link in external_urls:
print(external_link.strip(), file=f)
Многократный запрос одного и того же веб-сайта за короткий промежуток времени может привести к тому, что веб-сайт заблокирует ваш IP-адрес. В этом случае вам необходимо использовать прокси-сервер для таких целей.

![]() Как в Python извлечь все ссылки на веб‑странице, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Как в Python извлечь все ссылки на веб‑странице, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Респект и уважуха
