
Классификация изображений относится к процессу компьютерного зрения, который может классифицировать изображение в соответствии с его визуальным содержанием. Например, алгоритм классификации изображений может быть разработан, чтобы определить, содержит ли изображение кошку или собаку. Хотя обнаружение объекта для человека тривиально, надежная классификация изображений по-прежнему является проблемой в приложениях компьютерного зрения.
В этом уроке вы узнаете, как успешно классифицировать изображения в наборе данных CIFAR-10 (который состоит из самолетов, собак, кошек и других 7 объектов) с помощью Tensorflow в Python.
Обратите внимание, что существует разница между классификацией изображений и обнаружением объектов, классификация изображений — это отнесение изображения к какой-либо категории, например, в этом примере входом является изображение, а выходом — метка одного класса (10 классов). Обнаружение объектов — это обнаружение, классификация и локализация объектов в реальных изображениях, одним из основных алгоритмов является обнаружение объектов YOLO.
Мы предварительно обработаем изображения и метки, а затем обучим сверточную нейронную сеть на всех обучающих выборках. Изображения должны быть нормализованы, а метки должны быть закодированы в горячем режиме.
Для начала установим пакеты для этого проекта:
pip3 install numpy matplotlib tensorflow==2.0.0 tensorflow_datasets
Например, откройте пустой файл Python, назовите его train.py и запишите код для импорта Tensorflow:
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Dropout, Activation, Flatten from tensorflow.keras.layers import Conv2D, MaxPooling2D from tensorflow.keras.callbacks import TensorBoard import tensorflow as tf import tensorflow_datasets as tfds import os
Как и следовало ожидать, будем использовать API tf.data для загрузки набора данных CIFAR-10.
Гиперпараметры
Я экспериментировал с различными параметрами и эти параметры считаю оптимальными:
# Гиперпараметры batch_size = 64 # 10 категорий для изображений (CIFAR-10) num_classes = 10 # количество эпох для обучения epochs = 30
num_classes просто количество категорий для классификации, в нашем случае CIFAR-10 имеет только 10 категорий изображений.
- Набор данных состоит из 10 классов изображений, чьи метки находятся в диапазоне от 0 до 9::
- 0: airplane (самолет) ().
- 1: automobile (автомобиль) ().
- 2: bird (птица).
- 3: cat (кошка).
- 4: deer (олень).
- 5: dog (собака).
- 6: frog (лягушка).
- 7: horse (лошадь).
- 8: ship (корабль).
- 9: truck (грузовик).
- 50000 образцов для обучающих данных и 10000 образцов для тестовых данных.
- Каждый образец представляет собой изображение размером 32x32x3 пикселя (ширина и высота 32 и 3 глубины, которые являются значениями RGB).
Загрузим всё это:
def load_data():
"""
Эта функция загружает набор данных CIFAR-10 dataset и делает предварительную обработку
"""
def preprocess_image(image, label):
# преобразуем целочисленный диапазон [0, 255] в диапазон действительных чисел [0, 1]
image = tf.image.convert_image_dtype(image, tf.float32)
return image, label
# загружаем набор данных CIFAR-10, разделяем его на обучающий и тестовый
ds_train, info = tfds.load("cifar10", with_info=True, split="train", as_supervised=True)
ds_test = tfds.load("cifar10", split="test", as_supervised=True)
# повторять набор данных, перемешивая, предварительно обрабатывая, разделяем по пакетам
ds_train = ds_train.repeat().shuffle(1024).map(preprocess_image).batch(batch_size)
ds_test = ds_test.repeat().shuffle(1024).map(preprocess_image).batch(batch_size)
return ds_train, ds_test, info
Эта функция загружает набор данных с помощью модуля . Мы установили для параметра with_info значение True для просмотра некоторой информации об этом наборе данных, поэтому можно распечатать его и посмотреть названия полей и их значения. мы будем использовать информацию для получения количества образцов в тренировочных и тестовых наборах.
После этого мы:
- Бесконечно повторяем набор данных, используя метод
repeat(), что позволит нам многократно генерировать образцы данных (мы укажем условие остановки на этапе обучения). - Перемешиваем.
- Нормализуем изображения до значений от 0 до 1, это поможет нейронной сети обучаться намного быстрее, для чего используем метод
map(), который принимает функцию обратного вызова, изображение и метку в качестве аргументов, просто используя встроенный в Tensorflowconvert_image_dtype(), который и занимается всем этим. - Наконец, группируем наш набор данных по 64 образцам с помощью функции
batch(), поэтому каждый раз, когда мы генерируем новые точки данных, он будет возвращать 64 изображения и их 64 метки.
Построение модели
Будет использована следующая модель:
def create_model(input_shape):
# построение модели
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding="same", input_shape=input_shape))
model.add(Activation("relu"))
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# сглаживание неровностей
model.add(Flatten())
# полносвязный слой
model.add(Dense(1024))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation="softmax"))
# печатаем итоговую архитектуру модели
model.summary()
# обучение модели с помощью оптимизатора Адама
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
return model
3 уровня из 2 ConvNet с максимальным объединением и функцией активации ReLU, а затем полностью подключенным к 1024 единицам. Это относительно небольшая модель по сравнению с самыми современными моделями или . Если вы хотите использовать модели, созданные экспертами по глубокому обучению, вам необходимо использовать .
Обучение модели
Теперь давайте обучим модель:
if __name__ == "__main__":
# загружаем данные
ds_train, ds_test, info = load_data()
# конструируем модель
model = create_model(input_shape=info.features["image"].shape)
# несколько хороших обратных вызовов
logdir = os.path.join("logs", "cifar10-model-v1")
tensorboard = TensorBoard(log_dir=logdir)
# убедимся, что папка с результатами существует
if not os.path.isdir("results"):
os.mkdir("results")
# обучаем
model.fit(ds_train, epochs=epochs, validation_data=ds_test, verbose=1,
steps_per_epoch=info.splits["train"].num_examples // batch_size,
validation_steps=info.splits["test"].num_examples // batch_size,
callbacks=[tensorboard])
# сохраняем модель на диске
model.save("results/cifar10-model-v1.h5")
После загрузки данных и создания модели я использовал Tensorboard, который будет отслеживать точность и потери в каждой эпохе и предоставлять нам хорошую визуализацию.
Будем использовать папку results для сохранения наших моделей. Обязательно проверьте, что можете работать с файлами и каталогами в Python.
Поскольку ds_train и ds_test будут многократно генерировать выборки данных в пакетах, нам нужно указать количество шагов на эпоху и количество выборок, разделенное на размер пакета, то же самое и для validation_steps.
Запустите. В зависимости от вашего процессора/графического процессора это займет несколько минут.
Результат будет примерно таким:
Epoch 1/30 781/781 [==============================] - 20s 26ms/step - loss: 1.6503 - accuracy: 0.3905 - val_loss: 1.2835 - val_accuracy: 0.5238 Epoch 2/30 781/781 [==============================] - 16s 21ms/step - loss: 1.1847 - accuracy: 0.5750 - val_loss: 0.9773 - val_accuracy: 0.6542
Вплоть до последней эпохи:
Epoch 29/30 781/781 [==============================] - 16s 21ms/step - loss: 0.4094 - accuracy: 0.8570 - val_loss: 0.5954 - val_accuracy: 0.8089 Epoch 30/30 781/781 [==============================] - 16s 21ms/step - loss: 0.4130 - accuracy: 0.8563 - val_loss: 0.6128 - val_accuracy: 0.8060
Теперь, чтобы открыть tensorboard, все, что вам нужно сделать, это ввести команду в терминале или в командной строке в текущем каталоге:
tensorboard --logdir="logs"
Откройте вкладку браузера и введите localhost: 6006, вы будете перенаправлены на tensorboard, вот мой результат:
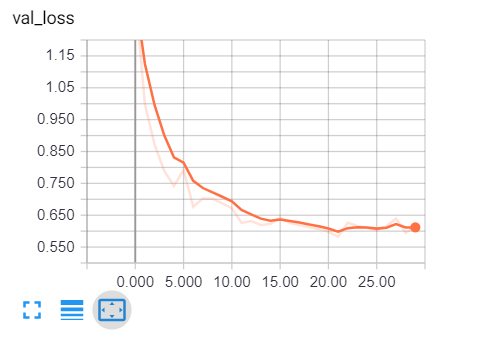
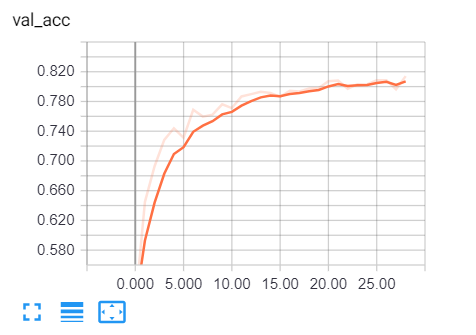
Очевидно, что мы на правильном пути, потери при проверке снижаются, а точность возрастает примерно до 81%. И это просто замечательно!
Проверка модели
После завершения обучения окончательная модель и веса нейронной сети будут сохранены в папке результатов, таким образом, научив её один раз мы сможем делать прогнозы, когда захотим.
Откройте новый файл python с именем test.py и следуйте инструкциям.
Импортируем необходимые утилиты:
from train import load_data, batch_size from tensorflow.keras.models import load_model import matplotlib.pyplot as plt import numpy as np
Создадим словарь Python, который сопоставляет каждое целочисленное значение с соответствующей меткой в наборе данных:
# CIFAR-10 classes
categories = {
0: "airplane",
1: "automobile",
2: "bird",
3: "cat",
4: "deer",
5: "dog",
6: "frog",
7: "horse",
8: "ship",
9: "truck"
}
Загрузим тестовые данные и модели:
# загрузим тестовый набор
ds_train, ds_test, info = load_data()
# загрузим итоговую модель с весовыми коэффициентами
model = load_model("results/cifar10-model-v1.h5")
Оценка:
# оценка
loss, accuracy = model.evaluate(X_test, y_test)
print("Тестовая оценка:", accuracy*100, "%")
Возьмем случайное изображение и сделаем прогноз:
# получить прогноз для этого изображения
data_sample = next(iter(ds_test))
sample_image = data_sample[0].numpy()[0]
sample_label = categories[data_sample[1].numpy()[0]]
prediction = np.argmax(model.predict(sample_image.reshape(-1, *sample_image.shape))[0])
print("Predicted label:", categories[prediction])
print("True label:", sample_label)
Мы использовали next(iter(ds_test)) для получения следующего пакета тестирования, а затем извлекли первое изображение и метку в этом пакете и сделали прогнозы для модели, вот результат:
156/156 [==============================] - 3s 20ms/step - loss: 0.6119 - accuracy: 0.8063 Test accuracy: 80.62900900840759 % Predicted label: frog True label: frog
Модель говорит, что это лягушка, проверим:
# show the image
plt.axis('off')
plt.imshow(sample_image)
plt.show()
 И это действительно так!
И это действительно так!
Заключение
Хорошо, мы закончили с этим уроком, 81% неплохо для этой маленькой . Я настоятельно рекомендую вам повернуть модель или проверить , или другие современные модели, чтобы получить более высокую производительность!
Требуется регистрация для доступа к контенту. Регистрация, если Вы уже зарегистрированы — подключитесь
Вы можете удивиться, что эти изображения такие простые, сетка 32×32 — это не то, что есть в реальном мире, изображения не такие простые, они часто содержат много объектов, сложных узоров и так далее. В результате, перед переходом к каким-либо методам классификации часто обычной практикой является использование методов сегментации изображений, таких как обнаружение контуров или сегментация кластеризации K-средних.
Наконец, если вы хотите расширить свои навыки в области машинного обучения (или даже если вы новичок), я бы посоветовал вам поступать в Высшую школу экономики и управления на образовательное направление 38.03.05 Бизнес-информатика. Удачи!
По мотивам

![]() Как создать классификатор изображений на Python с помощью Tensorflow 2 и Keras, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Как создать классификатор изображений на Python с помощью Tensorflow 2 и Keras, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Респект и уважуха
