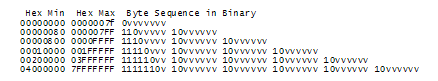Позабытый, безработный после мерзостей известных
По-над площадью Болотной распластался Буревестник.
Покрывает телом пыльным всё болотное пространство.
Рядом пляшет глупый пингвин: «Обосрался! Обосрался!»
А какие были страсти. Вождь Немцов, Навальный-витязь
Обещали смену власти. Получите, распишитесь!
Где там «Марши миллионов», те что летом предрекали?
«Слили всё! — вопит Лимонов. — Надо было баррикады».
«Власть падёт в течение года», революцией пугали.
«Вы не знаете народа, — стонут вещие гагары. —
Наподдать ему, нахалу! Он же с левыми в союзе».
Это наше ноу-хау — бить за крах своих иллюзий.
Гордой птице нет пощады. Топот, выкрики, кровища.
Как-то все ужасно рады, что на этот раз не вышло.
Не надеемся, не ропщем, смотрим под ноги уныло.
Можно гнить, как будто, в общем, ничего и не летало.
Оперение седое, кучка рваных сухожилий.
Да, такая наша доля. Мы другой не заслужили.
Чем надёжней, тем бескрылей, как ведётся на Востоке.
Мы же сами говорили, что не выйдет, — мы в восторге.
Ничего не весит Слово — ни прозренья, ни цитаты.
И теперь надолго снова мы ни в чём не виноваты.
Вот и всё, как говорится. Только сумрак и ухабы.
Буревестник — горе-птица, но ведь он летал хотя бы.
Да, давайте вытрем ноги о загадочную птицу,
Обманувшую в итоге и Москву и заграницу.
Всё отечество привыкнет жить во злобе, брови хмуря.
И никто уже не вскрикнет: «Буря! Скоро грянет буря!»
День предсказанный настанет. Всех оделит и осудит.
Просто буря. Просто грянет. Буревестника не будет.
Не поможет ни юродство, ни мольба, ни смена галса.
Только пингвин обосрётся. Не поняв, что обосрался.
Праздник каждый день — это выражение вряд ли относится к ИТ-сообществу. Однако, у людей, связавших себя с высокими технологиями, тоже есть дни в году, в которые они могут с гордостью сказать — «Я программист, сисадмин, тестировщик и т.д.».
Кстати, праздников, как выяснилось, так или иначе относящихся к ИТ, не так уж и мало. Среди них есть летние, весенние, зимние, и, конечно же — осенние. К последним относится и День программиста, который не так давно был признан в России официальным. Итак, по порядку.
Международный день без интернета
Данный праздник придумали в 2002 году организаторы британского некоммерческого онлайнового проекта DoBe.org, которые объявили последнее воскресенье января Международным днем без интернета. В этом году он отмечался 25 января. По их замыслу этот день люди должны провести в оффлайн, то есть без выхода во всемирную сеть и без компьютера. Пользователи сети, вместо онлайн-общения, должны выйти на прогулку, выехать за город, навестить родственников и друзей. Для того чтобы выбрать способ проведения времени без интернета, DoBe.org предлагает на листе бумаги написать шесть вариантов проведения досуга, а затем бросить игральную кость, чтобы определить, какой из них осуществить в первую очередь. Таких дней без интернета уже 25.
День безопасного интернета
Этот праздник был учрежден по инициативе Европейской комиссии в 2004 году. Он отмечается в первый вторник февраля. В 2009 году празднование пришлось на 2-е число месяца. Целью дня безопасности в интернете является информирование пользователей сети о рисках и опасностях, связанных со всемирной паутиной. Праздник отмечается по всему миру. Праздник отмечают 17 раз.
День компьютерщика
Праздник отмечается 14 февраля. Это день всех влюбленных в компьютеры людей. А если серьезно, то 14 февраля 1946 года был запущен первый электронный цифровой компьютер ENIAC, который реально работал и даже совершал вычисления (обсчет баллистических таблиц армии США). В честь этого события и задумали праздник, отмечать который теперь могут миллионы пользователей компьютеров во всем мире.
День оверклокера
Это праздник для компьютерных энтузиастов, которые «разгоняют» процессоры своих ЭВМ до неведомых скоростей. По легенде впервые упоминание об этом празднике было зафиксировано в форуме российского оверклокерского портала в 2004 году. Некто под ником «зЁма с чернозЁма» предложил: «…давайте назначим себе дату — День оверклокеров (а то день танкиста есть, у лесной промышленности тоже… абыдно жить без праздника)». C тех пор «День оверклокера» отмечается в обычный год 28 февраля, а в високосный — «разогнанный год» — 29 февраля. Причем этот праздник, зародившийся в России, отмечается теперь по всему миру.
День ИТ-специалистов
Является неофициальным праздником. Отмечается 28 февраля в день изобретения сетевого кабеля. В основном — это еще один повод выпить с коллегами.
День свободы слова в интернете
Этот праздник создан по инициативе международной организации «Репортеры без границ» и проходит под патронатом ЮНЕСКО. День свободы слова в интернете — мероприятие сравнительно молодое — впервые он отмечался 12 марта 2008 года. Его целью является поддержка интернет-диссидентов, которые отбывают тюремное заключение по всему миру. В прошлом году в застенках находилось 63 человека, чья свобода слова не понравилась властям.
Организаторы мероприятия призывают в этот день выразить в виртуальном пространстве протест против цензуры, которой злоупотребляют правительства некоторых стран. К таким относятся Бирма, Китай, Северная Корея, Куба, Египет, Эритрея, Тунис, Туркменистан, Вьетнам и другие.
День выключения (Shutdown Day)
Впервые этот праздник отмечался 24 марта 2007 года. Тогда в Сети появился призыв отключить в один день как можно больше компьютеров по всему миру. Цель акции заключается в том, чтобы узнать, сколько же людей может продержаться в течение суток без компьютера, и что может произойти в результате такого флешмоба. Авторами идеи стали программисты, проживающие в Монреале (Канада), Denis Bystrov (родился в Белоруссии) и Ashutosh Rajekar (родился в Индии).
День вэб-мастера
4 апреля отмечается День веб-мастера (или Вебмастера). Дата этого праздника выбрана неслучайно: если присмотреться, можно заметить, что цифры 4.04 очень напоминают по своему написанию ошибку 404 («Страница не найдена»), имеющую прямое отношение к работе веб-мастеров. К тому же эта дата совпадает с Международным днем интернета. Веб-мастер — профессия довольно новая, она появилась совсем недавно, в век развития интернета. Веб-мастер, или «управляющий» сайтом, — это человек, занимающийся разработкой веб-сайта или корпоративного приложения в интернете.
Впервые термин «веб-мастер» ввел в обращение «праотец» Интернета Тим Бернерс-Ли в документе «Руководство по стилю гипертекста в онлайне» в 1992 году. В начале 1990-х, когда «общедоступный» Интернет еще только начинал развиваться, функционал первых веб-мастеров был очень разнообразным: он включал в себя обязанности веб-дизайнера, автора и модератора сайта, программиста, системного администратора, контент-менеджера (ответственного за смысловое наполнение сайта), сотрудника технической поддержки сайта
С развитием Интернета и появлением более крупных сайтов технологии их разработки усовершенствовались, что привело к выделению специализаций веб-мастеров в разные профессии. Кстати, оказывается, что в отличие от русского языка, где не существует женской формы названия этой профессии, в английском языке веб-мастеров женского пола иногда называют «веб-мистресс» (англ. webmistress), однако широкого распространения эта форма не получила.
День рождения Рунета
Отмечается 7 апреля. Именно в этот день в 1994 году международная организация ICANN (The Internet Corporation for Assigned Names and Numbers), которая занимается вопросами регламентирования отношений в мировом доменном пространстве, зарегистрировала для России домен .Ru. Кроме того, 7 апреля было подписано Соглашение «О порядке администрирования зоны RU». В этом году Рунету исполняется 32 года.
День Криптографической службы России
Свой профессиональный праздник отечественные шифровальщики отмечают 5 мая. По информации Центра общественных связей ФСБ, служба, созданная постановлением Совета народных комиссаров РСФСР от 5 мая 1921 года, обеспечивает с помощью шифровальных (криптографических) средств защиту информации в информационно-телекоммуникационных системах и системах специальной связи в РФ и ее учреждениях за рубежом, в том числе в системах, использующих современные информационные технологии.
Всемирный день информационного сообщества
ООН считает этот день праздником для всех представителей ИТ-сообщества. Генеральная Ассамблея ООН в 2006 году приняла резолюцию, в которой провозгласила 17 мая профессиональным праздником всех программистов, системных администраторов, интернет-провайдеров, веб-дизайнеров, редакторов интернет-изданий и всех остальных людей, занятых в сфере информационных технологий. До 2006 года этот праздник отмечался как Международный день электросвязи или Всемирный день телекоммуникаций. Дело в том, что 17 мая 1865 года в Париже был основан международный Телеграфный Союз.
День оптимизатора Рунета (День SEO-оптимизатора)
В этот день, 28 мая, свой профессиональный праздник отмечают оптимизаторы Рунета, или SEO-администраторы. Правда, праздник пока не имеет официального статуса, а о его существовании знают, в основном, специалисты данной сферы. Аббревиатура SEO (Search Engine Optimization) обозначает различные методы работы с поисковыми системами — с целью роста позиций ресурса в поисковой выдаче по определенным запросам пользователей. Профессия SEO-оптимизатора возникла в России еще в середине 90-х годов прошлого века. Именно тогда появились первые поисковые системы, позиции сайта в которых напрямую коррелировали с доходами от ресурса. С тех пор прошло много лет. Поисковики не раз меняли свои алгоритмы, параллельно с этим развивалось и SEO. Сегодня SEO — это мощная индустрия с многомиллионными оборотами.
День краудфандинга
7 июня 2015 года в России отметили новый праздник – День краудфандинга. Дата праздника была выбрана не случайно, именно 7 июня в 2012 году официально начал работу один из первых российских краудфандинговых сервисов – сайт . Напомним, что краудфандинг (от англ. сrowd funding, сrowd – «толпа», funding – «финансирование») – это народное финансирование, или коллективное сотрудничество людей, которые добровольно жертвуют/вкладывают свои деньги, как правило через Интернет, чтобы оказать финансовую поддержку какому-либо проекту или организации. На русский же манер краудфандинг можно дословно перевести как – «с миру по нитке».
День системного администратора
Идея праздника пришла в голову сисадмина из Чикаго Теда Кекатоса (Ted Kekatos). Впервые он отмечался 28 июля 2000 года. Кстати, в 2000 году Папа Римский Иоанн Павел II официально назвал Святого Исидора покровителем пользователей компьютеров и интернета. Празднуется День сисадмина в последнюю пятницу июля. В этом году он отмечался 30 числа. Например, в России с 2006 года под Калугой ежегодно проходит Всероссийский слет системных администраторов, с каждым годом собирающий все больше и больше участников. Так, если первый слет посетило около 350 человек, то в 2009 году его участниками стали более 4000 человек из 174 городов России, Украины, Белоруссии и Казахстана.
День тестировщика
Отмечается 9 сентября. В этот день в 1945 году ученые Гарвардского университета, тестировавшие вычислительную машину Mark II Aiken Relay Calculator, нашли мотылька, застрявшего между контактами электромеханического реле. С тех пор именно эта дата считается профессиональным праздником людей, которые все свое время проводят в поисках багов, уязвимостей, «глюков» и прочих неполадок в ПО.
День программиста
Профессиональный праздник программистов, отмечаемый на 256-й день года (для программиста это 255-й день года или 0xFF-ный в 16-ричной системе счисления, так как счет начинается с нуля). Число 256 (28) выбрано потому, что это количество чисел, которое можно выразить с помощью восьмиразрядного байта. Отмечается праздник по предложению российского программиста Валентина Балта, сотрудника веб-студии «Параллельные Технологии», который еще в 2002 году собирал подписи под обращением к правительству РФ в поддержку признания этого дня официальным праздником.
В России праздник стал официальным только 11 сентября 2009 года, когда президент Дмитрий Медведев подписал Указ, подготовленный Министерством связи и массовых коммуникаций Российской Федерации, который устанавливает в стране новый официальный праздник — День программиста.
День рождения «смайла»
Это произошло 19 сентября 1982 года, когда профессор Университета Карнеги-Меллона Скотт Фалман (Scott E. Fahlman) впервые предложил использовать три символа, идущие подряд двоеточие, дефис и закрывающую скобку для обозначения «улыбающегося лица». Теперь это сочетание символов используется при онлайн-общении во всем мире, причем «отправить смайлик» могут друг другу не только друзья или знакомые, но и коллеги, а иногда улыбающееся лицо можно увидеть в диалогах между подчиненным и начальником.
Международный День интернета
Этот праздник предлагали сделать официальным несколько раз в разное время. Однако ни одна из предложенных дат так и не стала традиционной. Что касается России, то на неофициальном уровне Днем интернета считается 30 сентября. Дело в том, что с такой инициативой выступила компания из Москвы «IT Infoart Stars», которая разослала фирмам и организациям предложение поддержать их инициативу, состоящую из двух пунктов: назначить 30 сентября «Днем интернета», ежегодно его праздновать и провести «перепись населения русскоязычного интернета». На тот момент количество пользователей Рунета достигло 1 млн. человек.
Всемирный день юзабилити (World Usability Day)
был учрежден в 2005 году по инициативе Ассоциации Профессионалов Юзабилити. В этом же году он был впервые отпразднован и с тех пор отмечается ежегодно во второй четверг ноября. Юзабилити (Usability) можно дословно перевести с английского языка как «практичность, удобство и простота использования». Разумеется, существуют более подробные и точные определения. Например, Джейкоб Нильсен определяет юзабилити как: «… качество работы пользователя в некоторой интерактивной среде (web-сайт, программа и пр.)». Сегодня же термин «юзабилити» всё чаще используется как синоним слова «эргономичность» в контексте таких продуктов, как бытовая электроника или средства связи. В более широком значении он может также употребляться для определения степени эффективности выполнения механическими объектами и инструментами — такими, например, как дверная ручка или молоток — предписанных им функций. Таким образом, наиболее адекватным переводом слова «usability» будет «удобство и простота использования, применения» и даже «практичность». Одна из тем Дня прошлых лет была посвящена транспорту, которым мы пользуемся. Миссия этого праздника — повышение общественного сознания о необходимости упрощения доступа и повышения простоты использования продуктов и услуг, имеющих особо важное значения для человечества.
Всемирный день информации
Отмечается 26 ноября по инициативе Международной академии информатизации (МАИ), имеющей генеральный консультативный статус в Экономическом и Социальном советах ООН. Любой человек постоянно имеет дело с информацией, поэтому этот день по праву можно считать профессиональным праздником всех ИТ-специалистов.
Международный день защиты информации
Данный праздник отмечается с 30 ноября 1988 года по инициативе американской Ассоциации компьютерного оборудования. Цель праздника заключается в напоминании всем о необходимости защиты компьютерной информации, обратив внимание производителей и пользователей аппаратных и программных средств на проблему безопасности. Именно в 1988 году была зафиксирована первая массовая эпидемия компьютерного вируса. Это был червь, получивший название в честь своего автора Морриса.
День рождения отечественной информатики
В августе 1948 года член-корреспондент АН СССР Исаак Брук совместно с инженером Баширом Рамеевым представил проект автоматической вычислительной машины. А 4 декабря 1948 года Государственный комитет Совета Министров СССР по внедрению передовой техники в народное хозяйство зарегистрировал это изобретение за номером 10475 под названием «Цифровая электронная вычислительная машина»
Вот, пожалуй, и весь список. Хотя уже в следующем году какой-нибудь «айтишник» может придумать еще один необычный праздник, который, возможно, даже сделают официальным. Например, день блогера. А пока этого не произошло, можно выбрать из представленных выше самый подходящий и отметить его по полной программе.
Специально студентам неблизким к информационным технологиям, экономистам, юристам и прочим нетехнарям-гуманитариям, желающим знать немного больше, чем слово «браузер» …
By Jouel Spolski
Источник:
Абсолютно для каждого программиста абсолютный минимум знаний о наборах символов и Unicode, без которых решительно не обойтись. (Без возражений!)
Джоэл Спольски, Среда, 8 октября 2003
Вы никогда не задумывались о таинственном теге Content-Type? Того самого, который неизвестно как выглядит, если его надо вставить в HTML документ? Вы когда-нибудь получали электронную почту от своих друзей из Болгарии с темой «???? ???????? ????»?
Осознав, что множество разработчиков программного обеспечения абсолютно не компетентны во всем, что касается наборов символов, кодировкой, Unicode, считая все это таинственным миром, я был разочарован. Пару лет назад, при бета-тестировании , стало любопытно, а справиться ли он с входящей почтой на японском языке. Японский? Электропочта на японском? Об этом я и мечтать не смел. При тщательной отладке коммерческого ActiveX компонента, который мы использовали для анализа MIME сообщений электронной почты, мы обнаружили, что при работе с текстом он делает что-то совсем непотребное и были вынуждены героически править код для исключения неправильных преобразований, что бы заставить его работать так, как надо. Когда я присматривался к другой коммерческой библиотеке, да к тому же еще в объектном коде, то в переписке с разработчиком этого пакета узнал, что он «ничего не сможет с этим поделать». Как и большинство программистов, он просто понадеялся, что все и так сойдет. Не получилось. А когда я обнаружил, что для популярнейшего средства Web-разработки PHP демонстрируется , а для представления символов беспечно использует 8 бит, что делает практически невозможной любую «языковую примочку» в хороших международных Web-приложений, то понял — довольно, пора что-то делать.
Сегодня я официально заявляю, что если Вы программист и в 2003 году не знаете основ кодировки символов, Unicode и я Вас на этом поймаю — накажу, заставлю полгода чистить лук на подводной лодке. Клянусь — я это сделаю.
Кроме того,
ИТ не так уж сложны
В этой заметке я попытаюсь объяснить то, что должен знать каждый реальный программер. Выражение «Текст = ASCII символ = 8 бит» — не просто ошибка, а воинствующее и вопиющее незнание. Если, занимаясь программированием, Вы все еще так думаете, то Вы не намного лучше врача, который верит в бессмертие. Остановитесь, пожалуйста, не торопитесь писать еще одну строчку кода до тех пор, пока не прочитаете эту заметку.
Прежде чем я начну, должен сразу предупредить — если вы один из тех редких людей, которые знают об интернационализации, то, скорее всего, найдёте все мои рассуждения немного упрощёнными. Действительно, здесь я просто пытаюсь показать тот минимальный порог, который каждый должен перешагнуть для понимания происходящего и, возможно, написать код, только сулящий надежду на обработку текста с любым языком, кроме английского. И ещё должен предупредить, что принципы обработки — это только малая часть того, что необходимо для создания программного обеспечения международного уровня. Но одновременно писать я могу только об одном, а сегодня это наборы символов.
Историческая справка
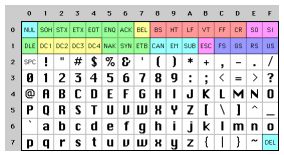
Понять это проще всего, если заглянуть в историю. Не думаете, что сейчас я расскажу об очень старых наборах символов, например, EBCDICએ. Не буду, нет. EBCDICએ не имеет никакого отношения к нашей жизни. Так далеко углубляться в прошлое не надо. Вернёмся в лишь в недалёкое прошлое. Когда был придуман Unixએ и K&R писали о , все было очень просто. EBCDICએ был единственным выходом из положения. Символы, имеющие значение, — это только добрые старые безударные английские буквы, а код это, так называемый, -код, в котором для представления каждого символа используется число от 32 до 127. А до 32 все было свободно, буква «А» — это 65 и т.д. Все это удобно и можно хранить в 7 битах.
Большинство компьютеров тех дней использовали 8-битные байты, что позволяло особо прижимистым, скаредно экономить, использовав резерв в собственных целях — тусклая луковица WordStarએ фактически превратила свободный бит в индикатор последней буквы слова и это обрекло WordStar к обработке только английских текстов.
Все, что меньше 32 считалось нецензурными, предназначенным исключительно для ругательств. Шутка такая. На самом деле — это символы управления, например, 7 — это звуковой сигнал, которые должен изрекать компьютер, а 12 выбрасывает текущую страницу бумаги из принтера и на прокорм забирает новую.
И все бы было ничего, если бы был только английский. Постольку поскольку в байт помещалось восемь бит, то многим пришло в голову — «черт возьми, для себя любимого можно использовать коды диапазона 128-255». Но всё дело в том, что эта мысль пришла одновременно ко многим, а у каждого свои собственные идеи по использованию пространства от 128 до 255. У IBM-PC это выродилось в наборы OEMએ символов, где представлены нетрадиционные для английского символы европейских языков, а так же — горизонтальные и вертикальные полосы, горизонтальные полосы с небольшими галтелями, оборванными по краям и т.д. С помощью таких графических символов можно нарисовать на экране элегантный бокс, который Вы еще сможете подсмотреть на компьютере 8088 своей химчистки. В действительности, как только ПК стали покупать за пределами Америки, каждый стал выдумывать свои наборы OEM символов, использующие верхние 128 кодов для своих собственных нужд. Например, на некоторых ПК код 130 будет отображать как символ é, а на компьютерах, продаваемых в Израиле, на иврите, будет написано гимел (λ). Поэтому, когда американцы посылают свои résumés в Израиль то, там читают rλsumλs . Частенько, например у русских, было множество различных реализаций верхних 128 кодов. Так, что надежно обмениваться русскими документами было невозможно.
В итоге по либеральному принципу «свободно для всех» OEM стало стандартом ANSIએ кодировок. Согласно стандарту ANSIએ коды до 128 полностью соответствуют ASCIIએ, а символы с кодами от 128 и выше зависят от Вашего местожительства с полной свободой реализации. Такие различия операционных систем назвали . Так, например, в Израиле DOS использует 862 кодовую страницу, в то же время греки предпочитают 737. Они одинаковы до 128 и отличаются после 128, где живут все эти смешные буковки. В национальных версиях MS-DOS были десятки кодовых страниц для обработки всего не английского, а может быть исландского. Было даже несколько «многоязычных» кодовых страниц, что позволяло работать на одном компьютере одновременно и на эсперанто, и на галисийском! Вот так! Однако, написать свою собственную программу, использующую для отображения растровую графику так, чтобы на одном компьютере работали одновременно и евреи, и греки принципиально невозможно — иврит и греческий слишком различны в интерпретации кодов и требуют абсолютно разных кодовых страниц.
А тем временем в Азии творится вообще полное безумие с учетом того факта, что азиатские алфавиты содержат тысячи символов, т.е. все их, ну никак, не вписать в 8 бит. Как правило, использовались «грязные» методы типа DBCSએ, «Double Byte Character Set», где часть букв кодируются одним байтом, а другая — двумя. В такой строке легко перемещаться вперед, но, чёрт возьми, совершенно не возможно назад. Для движения по строке назад и вперед программистам рекомендовалось не использовать *S++ и *S—, а вместо этого применять функции типа AnsiNext и AnsiPrev в Windows, которые научили бороться со всем этим кошмаром.
И все же до сих пор большинство просто делает вид, что байт — это все ещё 8 бит потому, что это всегда работает, если не переносить строки с компьютера на компьютер и говорить только на одном английском. Конечно, с появлением Интернета, когда передача текстов между компьютерами стала просто вынужденной необходимостью, весь этот порядок рухнул. Но к счастью изобрели Unicode.
Unicode
Unicodeએ — это смелая попытка создания единого набора символов, включающего все разумные системы письма на планете и даже некоторые, искусственно созданные такие, например, как «клингонский языкએ». Многие заблуждаются, считая Unicode просто 16-разрядным кодом, где каждому символу отводится 16 бит, т.е. 65 536 возможных комбинаций. На самом деле все не так. Это самый распространенный миф о Unicode, а если вы так думаете, то пусть же Вам будет хуже.
Фактически, в Unicode несколько иное представление о персонажах и Вы должны понимать мотивы, иначе все остальное теряет смысл. До сих пор мы предполагали, что образ символ соответствует некоему набору бит, который хранится на диске или в памяти:
А -> 0100 0001
В Unicodeએ символом называют код местоположения в таблице, а не битовый образ, — это теоретическая концепция. Именно, код места хранится в памяти или на диске. Образ А в Unicode — это платонический идеал. Это просто, парящий в небе символ A.
Этот платонический А отличается от B, точно так же, как а отличается А, но А не отличается от A, хотя отличается от а. Идея того, что «А» шрифта Times New Roman то же самое, что и «А» шрифта Helvetica, но отличается от «а» в нижнем регистре, не кажется очень уж спорной. Однако, выясняется, что в некоторых языках графический образ может быть сомнительным. Немецкий символ β – это действительно символ или причудливый способ написания ss? Если символ изменен в конце слова, является ли он другой буквой? Евреи говорят «да», а арабы «нет». Но по любому, Вам не придется об этом беспокоиться потому, что умные люди из консорциума Unicode на протяжении последнего десятилетия или около того только тем и занимались, что выясняли всё это, проводя большие и высокопарные политические споры для всеобщей ясности и понимания.
Всякому платоническому символу всякого алфавита консорциумом Unicode присвоено магическое число, которое записывается в виде U+0639. Это магическое число называется кодом места. U+ означает «Unicode», далее шестнадцатеричное число. U+0639 — это арабское Айн. Английская буква А — U+0041. Вы можете найти их все с помощью утилиты отображении символов вWindows 2000/XP или посетив .
В действительности в Unicode нет никаких ограничений на количество мест, даже если его надо больше чем 65 536 и символу надо сопоставить код размером большим чем два байта. Вот так и ни как иначе рушатся мифы.
Итак, у нас есть строка:
Hello,
что в Unicode соответствует пяти кодам:
U+0048 U+0065 U+006C U+006C U+006F.
Просто куча кодов. В действительности — это номера. Мы еще ничего не говорил о том, как эта куча хранится в памяти или представлена в электронной почте.
Кодировка
Вот, где введение в кодировку. Первая мысль о Unicode, которая и стала источником мифа о двух байтах, — Эй, давайте хранить эти цифры просто в двух байтах. Так Hello превращается в
00 48 00 65 00 6C 00 6C 00 6F
Верно? Но, не спешите! А не то же ли самое:
48 00 65 00 6C 00 6C 00 6F 00?
Ну, на самом деле, по технике это одно и то же и я уверен, что первые разработчики были в сомнениях — для какого конкретного режима работы процессора естественней хранить номера Unicode в старших байтах, а для какого в младших, но был вечер, и было утро, и вот уже два способа хранения Unicode. Так люди вынуждены придумать странные соглашения о записи FE FF в начале каждой строки Unicode. Это называется , и если вы смените свои старшие байты на младшие, то это будет выглядеть, как FF FE, а человек, читающий вашу строку, будет знать, что необходимо поменять местами все оставшиеся байты. Уф … Однако, в дикой природе не каждая строка Unicode содержит в начале метку порядка байтов.
Какое-то время всем всё казалось довольно удобным, но заворчали программисты. «Посмотрите на все эти нули!» — говорили они потому, что были американцами и смотрели только на английский текст, где редко используются номера более U+00FF. Более того, все эти либеральные Калифорнийские хиппи не хотели расти над собой. Техасцы даже не думали бы о двукратном поглощении байтов (прикол). Но эти калифорнийские слабаки не смогли переварить идею удвоения памяти для хранения текстов. Так или иначе, но уже есть масса ANSI и DBCS документов и, черт возьми, кто будет их конвертировать? Мы? Вот только по этой причине на протяжении нескольких лет большинство решительно игнорировало Unicode, а за это время всё стало совсем плохо.
В итоге, появилась блестящая концепция . UTF-8એ – это другая системы хранения кодов, этих волшебных U+номеров строки Unicode в памяти с помощью 8 битного байта. В UTF-8 каждый код от 0 до 127 хранится в одном байте. И только для хранения некоторых кодов от 128 и больше используются 2, 3, а на самом деле, до 6 байтов.
Английский текст выглядит в UTF-8 точно так же, как в ASCII, в чем нет ничего плохого. Но американцы даже не замечают этого галантного побочного эффекта. А весь остальной мир вынужден подпрыгивать в кольце. В частности, Hello, U+0048 U+0065 U+006C U+006C U+006F, будет храниться в виде 48 65 6C 6C 6F, вот! Точно так же как он хранится в ASCII, ANSI и любом OEM наборе планеты. Теперь, если вы возьмете на себя смелость использовать нестандартные или греческие буквы, клингонский язык, и должны будете использовать несколько байт для хранения одного номера символа, то американцы этого просто не заметят. (Кроме того, UTF-8 обладает хорошим свойством не обрезать строки в косолапой старой строке, где байт со значение NULL используется как нуль-терминатор).
До сих пор я говорил о трёх способах кодирования Unicode. Традиционные store-it-in-two-byte методы называются UCS-2એ (потому что два байта) или UTF-16 (потому что 16 бит) и вы поняли, что такое UCS-2 старшего байта и UCS-2 младшего байта. Новый популярный UTF-8એ, обладает еще одним замечательным свойством — счастливым совпадением текстов на английском языке в различных кодировках, что позволяет прилично работать брендовым программам, которые даже не подозревают, что существует нечто кроме ASCII.
На самом деле есть масса других способов кодирования Unicode. Например, так называемый, UTF-7એ, который очень похож на UTF-8એ, но с гарантией нулевого значения старшего бита, что дает ему возможность, при необходимости, пробиться через всякие драконовские ограничения системы электронной полиции. Думается, что 7 битов Unicode вполне достаточно, что бы пролезть там без искажений.
Есть UCS-4એ, где каждый код места хранится в 4 байтах, обладающий замечательным свойством, хранения кода в фиксированном количестве байт, но, ей-богу, в самом деле, даже техасцы не настолько решительны, что бы жертвовать под отходы такую уйму памяти.
Надеюсь теперь, Вы думаете о сущности с точки зрения платонического идеала буквы, представленной номером в Unicode, которое может быть закодировано по схеме любой не слишком древней школы кодирования! Например, вы можете кодировать Unicode строку Hello (U+0048 U+0065 U +006C U+006C U+006F) в ASCII или старом OEM греческой кодировки, или иврите ANSI кодировки, или любой другой из нескольких сотен кодировок, изобретённых до сих пор с пониманием того, что некоторые буквы могут просто не отображаться! Если номер Unicode не заполнен, а Вы пытаетесь показать этот символ, то, обычно, получаете небольшой знак вопроса «?», а если Вы действительно хороши, то вопрос в коробке �. У Вас какой?
Есть сотни традиционных кодировок, где верно хранятся только некоторые номера, а все остальные места Unicode заменяются вопросительным знаком. Наиболее популярными кодировками текста для английского являются Windows-1252એ (Windows 9x стандарт западноевропейских языков) и , также известный как Latin-1 (полезен для любого западноевропейского языка). Но попробуйте в них сохранить буквы русского или иврита и вы получите кучу вопросительных знаков. А вот UTF, 7, 8, 16 и 32 — все обладают хорошими свойствами и позволяют правильно хранить любой номер.
Самое важное в кодировках
Если вы полностью забудите все, что я только что сейчас объяснил, помните одно чрезвычайно важное обстоятельство — строка не имеет смысла, если не известна её кодировка. И Вы больше не можете прятать голову в песок и делать вид, что «просто текст» — это ASCII.
Нет такого понятия «просто текст».
Если у вас есть строка, в памяти, в файле или в сообщении электронной почты, то необходимо точно знать в какой она кодировке, иначе Вы не сможете её правильно интерпретировать и показать пользователям.
Почти каждый брюзжал — «мой сайт выглядит бредом» или «она не может прочитать мои письма не на английском». А проблему создал один наивный программист, который не понимает простого факта — если ему не сказали, что конкретная строка закодирована UTF-8, ASCII, ISO 8859-1 (Latin 1) или Windows 1252 (западноевропейская), то просто невозможно правильно её отобразить, более того, даже выяснить, где же она заканчивается.
Существует более ста кодировок, где номера более 127 полностью отсутствуют.
Как сохранить информацию о кодировке строки? Для этого есть несколько стандартных способов. Для сообщений электронной почты, вам потребуется строка в заголовке формы
Content-Type: text/plain; charset=»UTF-8″
Для веб-страниц была оригинальная идея — веб-сервер в заголовке http возвращает аналогичный Content-Type, т.е. не в HTMLએ странице, а в заголовке, который отправляются до передачи самой HTML страницы.
Однако, в этом есть проблема. Допустим, у вас большой веб-сервер с огромным количеством сайтов и миллионами страниц, размещенных множеством людей на самых разных языках с использованием любых возможных кодировок, которые по своему усмотрению генерирует MS FrontPageએ. Веб-сервер сам по себе не может знать кодировку каждого файла и поэтому не может отправить соответствующий Content-Type заголовка.
Было бы удобно получить возможность размещать Content-Type в самом файле HTML, используя какой-то специальный тег. Конечно, пуристы сочтут Вас за сумасшедшего … Как вы можете прочитать HTML файл, если не знаете в какой он кодировке?! К счастью, почти у всех кодировок коды всех символов от 32 до 127 одинаковы, так что вы всегда можете прочитать страницу HTML без использования смешанных записей до:
Этот мета тег действительно должен быть самым первым, прочитав его, веб-браузер останавливает дальнейшую обработку страницы и заново начинает все переосмысливать, применяя полученную от Вас кодировку.
Что делают веб-браузеры, если не находят Content-Type в HTTPએ заголовке или в мета-теге? Internet Explorer на деле предпринимает что-то довольно интересное — по частоте появления характерных байт в характерных местах текста он пытается угадать язык и кодировку. По-столько по-скольку, старых 8 битовых страниц мало, а национальные буквы, из диапазона между 128 и 255, имеют характерные частоты распределения в текстах различных человечьих языков, то это, скорее всего, имеет шансы работать. По настоящему странно то, что это работает довольно часто потому, что веб-страницы наивных писателей, которые никогда не знали о Content-Type в заголовке, выглядят в web-браузере нормально, пока в один прекрасный день, они не начнут писать тексты с отличным от их родного языка частотным распределение букв. Тогда Internet Explorer решит, что это корейский и соответствующим образом отобразит, доказывая, как думается, закон Постела «Будь требователен к тому, что отсылаешь, и либерален к тому, что принимаешь», откровенно неважный принцип для инженера. Во всяком случае, что делает бедный читатель болгарского сайта, который показан на корейском (и даже фрагментарно на корейском)? В главном меню «Просмотр» пункт «Кодировка» он пытается перебирать кучу разных кодировок (по крайней мере дюжину для восточн-европейских языков), пока страница не прояснится. Если он знает, что делать, но большинство об этом не знает.
В программном обеспечении последней версии — системы управления контентом сайта , мы решили всю внутреннюю кодировку сделать в UCS-2 (два байта) Unicode, которая по жизни была родной в Visual Basic, COM, и Windows NT/2000/XP. В кодах на C++ мы просто объявили строки как wchar_t («широкий символ»), а не char и использовать wcs_функции вместо str_функций (например, wcscat и wcslen вместо strcat и strlen). Для записи литеральной константы UCS-2 в коде на C достаточно перед ней просто написать символ L, вот так: L»Hello».
Когда CityDesk публикуется, то веб-страницы преобразуются в UTF-8, который на протяжении многих лет замечательно поддерживается большинством веб-браузеров. Вот так кодируются все программного обеспечения от Joel и еще ни от одного человека я не слышал жалоб на какие-либо проблемы при просмотре.
Заметка становится довольно нудной, хотя, все еще не охватила всего того, что надо знать о кодировках и Unicode. Однако, надеюсь, что ежели Вы дочитали до сюда, то знаете достаточно и можете вернуться к программированию без пиявок и заклинаний, применив прописанные здесь антибиотики.
Обдумывая проблемы, великие мыслители во всем находят общность. Глядя на людей посылающих друг другу файлы текстовых процессоров или файлы электронных таблиц, они понимают, что существует общность — отправка файлов. Уже готов первый уровень абстракции. Тогда они идут дальше — люди «отправляют» файлы, а веб-браузеры «отправляют» запросы на веб-страницы. А если немного подумать, то вызов метода объекта схож с отправкой сообщения объекту! Следующее обобщение, все это — операции отправки. Позднее наш умный мыслитель изобретает новую, более высокую, более всеобъемлющую абстракцию, которую называет messaging. И все становится настолько расплывчатым, что уже никто не понимает, о чем речь. Бла-бла-бла.
Наполненные великими абстракциями, Вы поднимаетесь столь высоко, что оказываетесь в безвоздушном пространстве. Иногда умные мыслители просто не знают, когда пора остановиться. Они создают свои нелепые, всеохватывающие фотографии вселенной наивысшего уровня абстракции, где все хорошо и прекрасно, а на самом деле уже ничего не рассмотреть. Читать далее «Не позволяйте космонавтам архитектуры запугивать себя»
Несмотря на то, что всего лишь год или два назад я плакался по поводу богатого Windows GUI [1], который захлестнет всех прочие интерфейсы, студенты колледжей, тем не менее, все-таки иногда по электронной почте спрашивают советов относительно карьеры, тем более, что начался сезон приема на работу. Я подумал, а не написать ли мне свои стандартные советы, которые они смогут прочитать, посмеяться и проигнорировать.
Большинство студентов, к счастью, достаточно дерзки и не стесняются задавать вопросы старейшинам компьютерных наук, и это правильно, несмотря на то, что старики склонны говорить странные допотопные вещи типа: «спрос на операторов перфоратора превысит 100 млн. к 2010 году» или «lisp-карьера — круто именно сейчас». Читать далее «Советы студентам Computer Science»
Впервые пытаясь заполнить вакансию Вы, как и большинство людей, разместив соответствующие объявления и, возможно, заявки на ближайших крупных онлайн биржах труда, получите тонны резюме.
По мере их изучения Вы отмечаете — «Хм-м-м-м, это может сработать», «Нет! Ни за что!» или «Интересно, смогу ли я убедить его переехать в Буффало». Но то, что точно никогда не случится, гарантирую, просто потому, что этого не может быть никогда, Вы не скажете себе — «Восхитительно! Он великолепен! Этот бриллиант мы обязаны заполучить!». На самом деле, Вы можете просмотреть тысячи резюме, если, конечно, знаете, как их читать, а это не так просто, и я к этому вернусь в пятницу. Вы можете изучить тысячи заявлений на работу и никогда не встретить великого девелопера [1]. Ни одного.
И вот почему. Великие девелоперы — это действительно лучшие люди в своем деле, и их попросту нет на рынке труда. В среднем, великий девелопер за все свою карьеру, возможно, раза четыре и сменит место работы. Читать далее «В поисках великих девелоперов»
В связи с новыми веяниями в системе ВПО и СПО медленно, но верно происходит переход к компетентносному подходу и внедрению балльно-рейтинговых систем (БРС) различного уровня. Но во всех БРС обязательно присутствует один показатель, который требует очень много усилий и времени при измерении и потому не пользуется популярностью не только среди студентов по понятным причинам, но и среди преподавателей, вынужденным выделять время учебных занятий на эту процедуру. Этот показатель называется «ПОСЕЩАЕМОСТЬ ЗАНЯТИЙ». При выставлении итоговой оценки по учебному курсу этот показатель учитывается весовым коэффициентом, определяющим его значимость. В связи с прохладным отношением участников бизнес-процесса валидность сырых данных вызывает большие сомнения. Надо бы как-то автоматизировать учет посещаемости, тем самым, сделать его более объективным. Но пока все известные предложения требуют значительных умственных и материальных затрат. Было-бы, конечно, неплохо сделать это с помощью системы распознавания образов с помощью видеокамеры, установленной в аудитории, да больно дорого и трудоёмко при реализации. Читать далее «Автоматизация измерения показателя «ПОСЕЩАЕМОСТЬ» в БРС факультета»

 В итоге по либеральному принципу «свободно для всех» OEM стало стандартом
В итоге по либеральному принципу «свободно для всех» OEM стало стандартом