
Перевод статьи , выполнен в
InfluxDB, база данных временных рядов (TSDBએ), разработанная InfluxData, в последние несколько месяцев демонстрирует всё большую популярность. Она стала одной из справочников для разработчиков и инженеров, желающих внедрить мониторинг в реальном времени в свою собственную инфраструктуру. Но что именно из себя представляет InfluxDB? Зачем она нужна? Какую ценность вы можете привнести, внедрив InfluxDBએ в свою среду?
Эта статья — отправная точка для разработчиков, инженеров и ИТ-специалистов, которые хотят изучить InfluxDB, его концепции, случаи использования и реальные приложения.
Цель в том, чтобы помочь вам освоить InfluxDB. Для начала получить общее представление о базах данных временных рядов. О том, что они из себя представляют и чем они отличаются от традиционных (РБД). Также полезно будет узнать подробное объяснение концепций, которые определяют InfluxDB. Не знакомы с измерениями, тегами или полями? Всё будет объяснено.
Не лишним будет увидеть примеры использования InfluxDB и её применение в различных отраслях. Реальные примеры, которые вы можете эмулировать, чтобы повысить ценность вашей компании или проекта.
Что такое база данных временных рядов?
БД временных рядов, исходя из названия, представляют собой системы баз данных, специально предназначенные для обработки информации, связанной со временем.
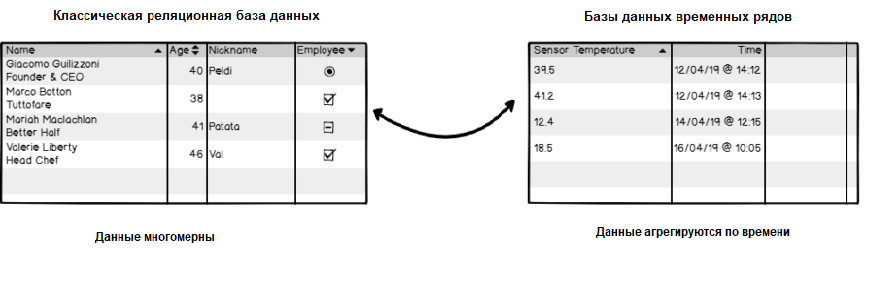
В основном все имеют дело с реляционными базами данных (MySQLએ или SQL Serverએ). Возможно, вы также имели дело с базами данных NoSQLએ (MongoDBએ или DynamoDBએ).
Все они основаны на том, что у вас есть таблицы. Эти таблицы содержат столбцы и строки, каждая из которых определяет запись в вашей таблице. Часто эти таблицы специально предназначены для определённой цели. Одна может быть предназначена для хранения пользователей, другая — для фотографий или видео. Такие системы эффективны, масштабируемы и используются множеством гигантских компаний, имеющих миллионы запросов на своих серверах.
Базы данных временных рядов работают по-разному. Данные по-прежнему хранятся в «коллекциях», но эти коллекции имеют общий знаменатель: они агрегируются со временем.
Это означает, что для каждой точки, которую вы можете сохранить, у вас есть связанная с ней временная метка.
Нельзя ли использовать реляционную базу данных и просто включить в неё столбец с именем «время»? Например, Oracle включает тип данных TIMESTAMP, который можно было бы использовать для этой цели.
Конечно, такое возможно, но это неэффективно.
Зачем нужны базы данных временных рядов?
Три слова: быстрый приём данных.
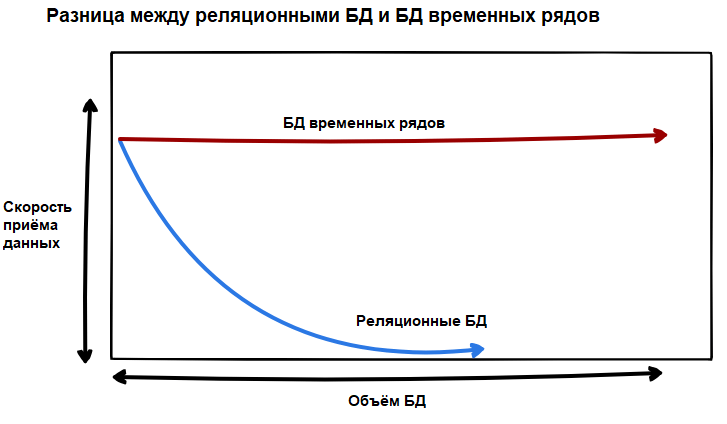
Системы баз данных временных рядов построены на принципе, что им нужно быстро и эффективно принимать данные.
Реляционные базы данных имеют большую скорость загрузки данных (от 20 000 до 100 000 строк в секунду). Тем не менее, приём не постоянен во времени. У реляционных баз данных есть один ключевой аспект, который делает их медленными при росте данных — индексы.
При добавлении новых записей в реляционную БД и при наличии в таблице индексов СУБД будет многократно переиндексировать данные для быстрого и эффективного доступа к ним. Как следствие, производительность со временем снижается. Нагрузка также увеличивается, что приводит к трудностям при чтении данных.
База данных временных рядов оптимизирована для быстрого приёма данных. Это означает, что такие системы оптимизированы для индексации данных, которые агрегируются во времени. Как следствие, скорость загрузки не уменьшается со временем и остается достаточно стабильной (от 50 до 100 тыс. строк в секунду на одном узле).
Специфичные концепции баз данных временных рядов
Кроме высокой скорости приёма, базы данных временных рядов вводят концепции, очень специфичные для этих технологий.
Одной из них является организация хранения данных. В традиционной РБД данные хранятся постоянно до тех пор, пока вы не решите их удалить. Учитывая сценарии использования БД временных рядов, вы можете не хранить ваши данные слишком долго: это или слишком дорого, или данные со временем теряют актуальность.
Системы вроде InfluxDB могут позаботиться об удалении данных через определённое время, используя концепцию, называемую политикой хранения (подробно описанной во второй части). Вы можете выполнять непрерывные запросы к оперативным данным для выполнения определённых операций.
В реляционной БД можно найти эквивалентные операции (например «задания» в SQL), которые могут выполняться по заданному расписанию.
Совершенно другая экосистема
БД временных рядов сильно различаются, когда речь заходит об их экосистемах. Как правило, реляционные базы данных окружены приложениями, которые подключаются к ним для получения информации или добавления новых записей.
Часто база данных ассоциируется с одной системой. Клиенты подключаются к веб-сайту, который обращается к базе данных для получения информации. БД временных рядов созданы под множество клиентов (программ). Здесь нет простого сервера, обращающегося к БД, но есть куча разных сенсоров (к примеру), выполняющих вставку данных одновременно.
Как следствие, инструменты были разработаны для того, чтобы иметь эффективные способы выработки данных или их использования.
Потребление данных
Потребление данных часто осуществляется с помощью инструментов мониторинга вроде или . Эти клиенты имеют встроенные решения для визуализации данных и даже создания пользовательских предупреждений.

Эти инструменты часто используются для создания живых панелей мониторинга, которые могут быть показаны графиками, гистограммами, датчиками или картами окружающего мира.
Производство данных
Производство данных осуществляется агентами, которые нацеливаются на специальные элементы в инфраструктуре и извлекают из них метрики. Такие агенты называются «агентами мониторинга». Вы можете легко настроить их для запроса данных за определённый промежуток времени. Примерами являются (который является официальным агентом мониторинга), или .

Теперь вы лучше понимаете, что такое базы данных временных рядов и чем они отличаются от реляционных. Пришло время углубиться в конкретные концепции InfluxDB.
Концепции InfluxDB
В этом разделе будут объяснены ключевые концепции InfluxDB и ключевой запрос, связанный с этим. InfluxDB встраивает свой собственный язык запросов и это заслуживает отдельного пояснения.
Язык запросов InfluxDB
Прежде чем начать, важно знать, какую версию InfluxDB вы используете в настоящее время. По состоянию на апрель 2019 года InfluxDB выпускается в двух версиях: v1.7+ и v2.0.
InfluxDB v2.0 в настоящее время (на октябрь 2019 года) является альфа-версией и воздвигает язык Flux в центр платформы. InfluxDB v1.7 оснащён языком InfluxQL (а также Flux, если его активировать).

Для начала можно по-прежнему использовать InfluxQL, так как Flux не полностью установлен в текущей версии платформы.
InfluxQL — это язык запросов, который очень похож на SQL, и позволяет любому пользователю запрашивать свои данные и фильтровать их. Вот пример запроса InfluxQL:
SELECT * FROM cpu_metrics WHERE time < now() - 10ms
Дальше будут рассмотрены ключевые концепции InfluxDB, предоставляемые с соответствующими запросами IQL (InfluxQL).
Ключевые концепты InfluxDB
Рассмотрим список основных терминов, которые необходимо знать для работы с InfluxDB в 2019 году.
База данных
База данных — само по себе простое для понимания понятие, потому что вы привыкли использовать этот термин в реляционных базах данных. В SQL-среде БД будет содержать набор таблиц и схем и будет представлять один экземпляр самостоятельно.
В InfluxDB БД содержит набор измерений. Однако один экземпляр InfluxDB может содержать несколько баз данных. В этом его отличие от традиционных систем. Эта логика подробно представлена на графике ниже:
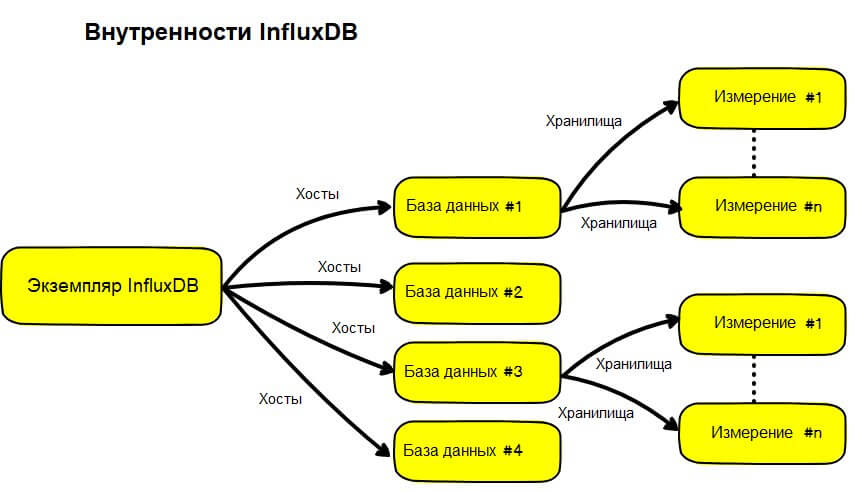
Наиболее распространённые способы взаимодействия с базами данных — это либо их создание (CREATE DATABASE “devconnected”;), либо переход в них (USE devconnected;) для просмотра коллекций (вы должны быть «в базе данных», чтобы запрашивать коллекции, иначе это не сработает).
Измерение
Как показано выше, база данных хранит несколько измерений (measurement). Для простоты восприятия думайте об измерении как о таблице SQL. Она хранит данные и даже метаданные в разные моменты времени. Данные, которые должны сосуществовать вместе, должны храниться в одном измерении.
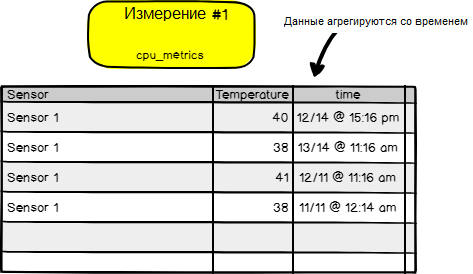
SELECT * FROM cpu_metrics WHERE temperature=’40’;
Теги и поля
Обратите внимание, есть тонкая разница между тегами и полями.
Для тех, кто впервые начинает работать с InfluxDB, будет трудно понять, почему теги и поля различаются. Они похожи на «столбцы», где вы можете хранить точно такие же данные. Определяя новый «столбец» в InfluxDB, вы можете либо объявить его как тег, либо как значение, и между ними есть различия.
Самая большая разница между ними заключается в том, что теги индексируются, а значения — нет. Теги можно рассматривать как метаданные, определяющие данные в измерении. Это подсказки, дающие дополнительную информацию о данных, но не сами данные. Поля — это сами данные. В прошлом примере столбец «температура» был бы полем.
Вернёмся к примеру cpu_metrics. Допустим, вы хотели добавить столбец с именем «location», определяющий местоположение датчика.
Должны ли вы добавить его в качестве тега или поля?
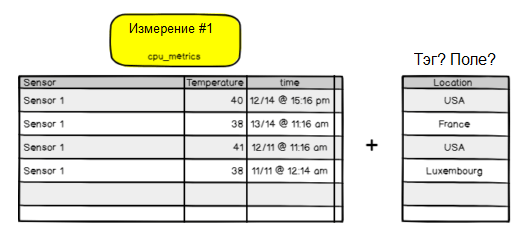
В данном случае это будет добавлено как тег. Необходимо, чтобы столбец «местоположение» индексировался и учитывался при выполнении запроса к местоположению.
Хорошим советом будет держать ваши измерения относительно небольшими, когда речь идёт о количестве полей. Всё большее количество полей часто связано с меньшей производительностью. Вы можете создать другие измерения, чтобы сохранить другое поле и правильно его проиндексировать.
Теперь, когда мы добавили метку местоположения в измерение, немного углубимся в таксономию.
Набор тега называется «tag-set». Имя столбца в теге называется «tag key». Значения тега называются «tag values». Та же систематика повторяется для полей. Вернёмся к чертежам.
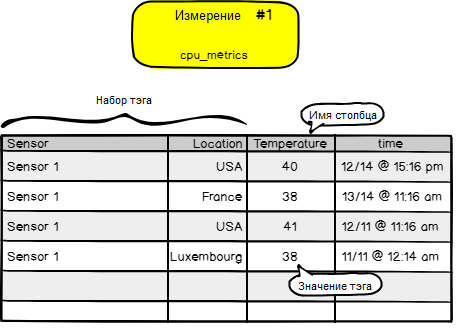
Временная метка
Временная метка (timestamp) — наверное, самое простое для определения ключевое слово. В InfluxDB — это дата и время, определённые в формате RFC3339. При использовании InfluxDB очень часто определяют ваш столбец времени как метку в Unix-времени, выраженную в наносекундах.
Вы можете выбрать формат наносекунд для временного столбца и позже снизить точность, добавляя нули в конец значения, чтобы оно соответствовало формату наносекунд.
Политика хранения
Политика хранения определяет, как долго вы собираетесь хранить ваши данные. Политики хранения определяются для каждой базы данных и их может быть несколько. По умолчанию политика хранения будет autogen и хранит ваши данные вечно. Как правило, базы данных имеют несколько политик хранения, которые используются для разных целей.
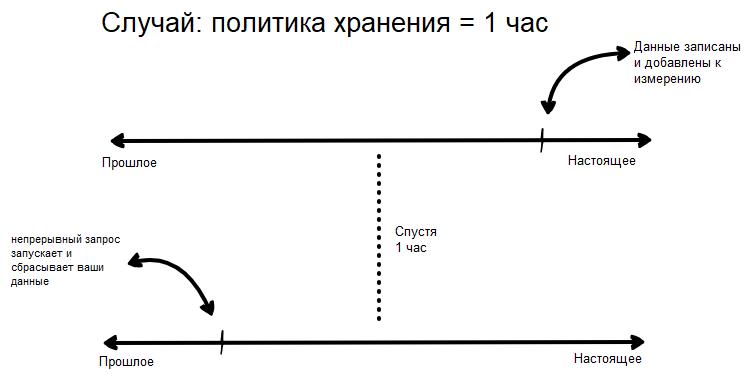
Представим, что вы используете InfluxDB для оперативного мониторинга всей инфраструктуры.
Например, вы хотите знать, когда сервер отключается. В этом случае вас интересуют данные, поступающие с этого сервера в настоящий момент или за несколько минут до этого. Вы не заинтересованы в хранении данных в течение нескольких месяцев, поэтому хотите определить небольшую политику хранения: например один или два часа.
Предположим, вы используете InfluxDB для IoT, например для сбора данных, поступающих из резервуара для воды. Позже вы захотите поделиться своими данными с группой научных специалистов, чтобы они могли их проанализировать. В этом случае вы можете хранить данные дольше: например пять лет.
Точка
Точка (point) — это просто набор полей с одинаковой отметкой времени. В SQL это будет выглядеть как строка или как уникальная запись в таблице. Здесь нет ничего особенного.
Случаи использования InfluxDB
Мониторинг DevOps — очень большая тема. Всё больше команд вкладывают средства в создание быстрой и надёжной архитектуры, основанной на мониторинге. Начиная от сервисов и заканчивая кластерами серверов, инженеры часто создают стек мониторинга, который обеспечивает интеллектуальные оповещения.
Чтобы узнать больше о мониторинге DevOps, ознакомьтесь со статьёй «».
С помощью инструментов в начале статьи вы можете создать собственную инфраструктуру мониторинга и принести прямую пользу вашей компании или начинающему предприятию.
IoT
IoT, вероятно, будет следующей большой революцией, которая произойдёт в ближайшие несколько лет. Предполагается, что к 2020 году более 30 миллиардов устройств будут считаться устройствами IoT. Независимо от того, осуществляете ли вы мониторинг одного устройства или гигантской сети таких девайсов, вам необходимо иметь точные и мгновенные показатели, чтобы вы могли принимать наилучшие решения.
Реальные компании уже работают с InfluxDB для IoT. Одним из примеров может быть , компания, которая нацелена на расширение умных городов с помощью индивидуальных концепций, таких как интеллектуальная парковка или система мониторинга трафика.
Промышленные и умные заводы
Заводы становятся всё более и более связанными. Задачи более автоматизированы, чем когда-либо. Как следствие, возникает очевидная необходимость иметь возможность контролировать каждый элемент производственной цепочки для обеспечения максимальной производительности. Но даже когда машины не выполняют всю работу и задействованы люди, мониторинг временных рядов даёт уникальную возможность донести соответствующие показатели до менеджеров.
Помимо повышения производительности, они могут способствовать созданию более безопасных рабочих мест, поскольку они способны быстрее обнаруживать проблемы.
Ваше собственное воображение
Приведённые выше примеры являются лишь примерами. Ваше воображение — это единственное ограничение для приложений, которые вы можете применить для баз данных временных рядов. Временные ряды могут даже использоваться в .
Идём дальше
В этой статье было рассмотрено, что такое базы данных временных рядов и как они используются в реальном мире. А также много технических терминов, стоящих за InfluxDB.
Хороший совет — создайте что-то сами. InfluxDB, поиграйте с инструментами. Создайте информационную панель, поиграйтесь с запросами, настройте некоторые оповещения. Только так вы сможете сами «пощупать» эту технологию и составить о ней своё мнение.

![]() База данных временных рядов компании InfluxData, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
База данных временных рядов компании InfluxData, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Респект и уважуха
