
Еще в 2012 году нейронная сеть впервые победила в конкурсе . Алекс Крижевский, Илья Суцкевер и Джеффри Хинтон произвели революцию в области классификации изображений.
В настоящее время задача присвоения отдельной метки изображению (или классификации изображения) хорошо известна. Однако практические сценарии не ограничиваются задачей «одна метка на одно изображение» — иногда нам нужно больше!
В этом посте мы рассмотрим одну из модификаций задачи классификации — так называемую классификацию с несколькими метками или получение тегов для изображений.
Что есть классификация с несколькими метками?
В области классификации изображений вы можете столкнуться со сценариями, в которых вам нужно определить несколько свойств объекта. Например, это могут быть такие категории, как цвет, размер и многое другое. В отличие от обычной классификации изображений, результат этой задачи будет содержать 2 или более свойств.
В этом уроке мы сосредоточимся на проблеме, где заранее знаем количество свойств. Такая задача называется классификацией мульти-выход. Фактически, это особый случай классификации мульти-меток, когда вы также можете предсказать несколько свойств, но их количество может варьироваться от образца к образцу.
Dataset
Мы будем практиковаться на наборе данных «Fashion Product Images» с низким разрешением, доступного на веб-сайте Kaggle:
В этом уроке мы будем использовать , который содержит более 44 000 изображений одежды и аксессуаров с 9 метками для каждого изображения.
Чтобы освоить урок, необходимо скачать этот набор и поместить в папку с кодом. Структура вашей папки должна выглядеть так:
├── fashion-product-images │ ├── images │ └── styles.csv ├── dataset.py ├── model.py ├── requirements.txt ├── split_data.py ├── test.py └── train.py
Файл fashion-product-images/styles.csv содержит метки данных. Для простоты в уроке будут использованы только три метки: gender, articleType и baseColour.
Давайте посмотрим на некоторые примеры из набора данных:

Давайте также извлечем все уникальные метки для наших категорий из аннотации данных. Всего у нас будет:
- 5 значений gender (
Boys,Girls,Men,Unisex,Women), - 47 цветов,
- и 143 описания (например,
Sports Sandals,Wallets or Sweaters).
Нашей целью будет создание и обучение нейронной сети для прогнозирования трех меток (gender, article, color) для изображений из нашего набора данных.
Настройки
Прежде всего, вы можете создать новую и установить необходимые библиотеки.
Библиотеки, которые нам нужны
- matplotlib
- numpy
- pillow
- scikit-learn
- torch
- torchvision
- tqdm
Все эти библиотеки могут быть установлены из файла requirements.txt:
python3 -m pip install -r requirements.txt
Этот код был протестирован с использованием Python 3.6, PyTorch 1.4, Ubuntu 18.04 и графического процессора Nvidia.
Хотя приведенный ниже код не зависит от устройства и может быть запущен на CPUએ, я рекомендую использовать GPUએ, чтобы значительно сократить время обучения. GPUએ в скрипте указан по умолчанию.
Dataset
В общей сложности мы собираемся использовать 40 000 изображений. Мы поместим 32 000 из них в тренировочный набор, а остальные 8 000 мы будем использовать для проверки. Разделим данные, запустив скрипт split_data.py:
all_data = []
# open annotation file
with open(annotation) as csv_file:
# parse it as CSV
reader = csv.DictReader(csv_file)
# tqdm shows pretty progress bar
# each row in the CSV file corresponds to the image
for row in tqdm(reader, total=reader.line_num):
# we need image ID to build the path to the image file
img_id = row['id']
# we're going to use only 3 attributes
gender = row['gender']
articleType = row['articleType']
baseColour = row['baseColour']
img_name = os.path.join(input_folder, 'images', str(img_id) + '.jpg')
# check if file is in place
if os.path.exists(img_name):
# check if the image has 80*60 pixels with 3 channels
img = Image.open(img_name)
if img.size == (60, 80) and img.mode == "RGB":
all_data.append([img_name, gender, articleType, baseColour])
else:
print("Something went wrong: there is no file ", img_name)
# set the seed of the random numbers generator, so we can reproduce the results later
np.random.seed(42)
# construct a Numpy array from the list
all_data = np.asarray(all_data)
# Take 40000 samples in random order
inds = np.random.choice(40000, 40000, replace=False)
# split the data into train/val and save them as csv files
save_csv(all_data[inds][:32000], os.path.join(output_folder, 'train.csv'))
save_csv(all_data[inds][32000:40000], os.path.join(output_folder, 'val.csv'))
В этом коде создаются файлы train.csv и val.csv. Эти файлы хранят список изображений и их метки в соответствующем разделе.
Загрузка Dataset
Поскольку в нашей аннотации данных имеется более одной метки, нам нужно настроить способ чтения данных и загрузить их в память. Для этого мы создадим класс, который наследует набор данных PyTorch. Он сможет анализировать наши аннотации данных и извлекать только те метки, которые нас интересуют. Основное различие между классификацией с несколькими выходными данными и классификацией для одного класса состоит в том, что мы будем возвращать несколько меток для каждого образца из набора данных.
class FashionDataset(Dataset):
def __init__(...):
...
# инициализировать массивы для хранения меток истинности и путей к изображениям
self.data = []
self.color_labels = []
self.gender_labels = []
self.article_labels = []
# читать аннотации из файла CSV
with open(annotation_path) as f:
reader = csv.DictReader(f)
for row in reader:
self.data.append(row['image_path'])
self.color_labels.append(self.attr.color_name_to_id[row['baseColour']])
self.gender_labels.append(self.attr.gender_name_to_id[row['gender']])
self.article_labels.append(self.attr.article_name_to_id[row['articleType']])
Функция __getitem__() нашего класса набора данных извлекает изображение и три соответствующие метки. Затем он увеличивает изображение для обучения и возвращает его с метками в виде словаря:
def __getitem__(self, idx):
# взять образец данных по его индексу
img_path = self.data[idx]
# читать изображение
img = Image.open(img_path)
# применить аугментации изображения при необходимости
if self.transform:
img = self.transform(img)
# вернуть изображение и все связанные ярлыки
dict_data = {
'img': img,
'labels': {
'color_labels': self.color_labels[idx],
'gender_labels': self.gender_labels[idx],
'article_labels': self.article_labels[idx]
}
}
return dict_data
Хорошо, похоже, мы готовы загрузить наши данные.
Аугментация данных
Аугментацияએ данных — случайные преобразования, которые улучшают распознавание изображений. Она рандомизируют данные и, таким образом, помогают нам бороться с перегрузкой при обучении сети.
Здесь мы будем использовать случайное переворачивание, небольшие изменения цвета, вращение, масштабирование и перевод (объединенные в аффинное преобразованиеએ). Кроме того, перед загрузкой изображений в сеть для обучения нормализуем данные — это стандартный подход в Deep Learningએ.
# specify image transforms for augmentation during training
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0),
transforms.RandomAffine(degrees=20, translate=(0.1, 0.1), scale=(0.8, 1.2),
shear=None, resample=False, fillcolor=(255, 255, 255)),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
На этапе проверки мы не будем рандомизировать данные — просто нормализуем и конвертируем их в формат PyTorch Tensor.
# во время проверки мы используем только тензорные и нормализационные преобразования
val_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
Теперь, когда наш набор данных готов, давайте определим модель.
Модель
Посмотрите на определение класса модели. Мы берем нейронную сеть mobilenet_v2 из torchvision.models. Эта модель может решить классификацию ImageNet, поэтому ее последним уровнем является отдельный классификатор.
Чтобы использовать эту модель для нашей задачи с несколькими выходами, но изменим ее. Нам нужно предсказать три свойства, поэтому мы будем использовать три новых классификационных заголовка вместо одного классификатора: эти заголовки называются color, gender и article. У каждого заголовка будет своя потеря перекрестной энтропии.
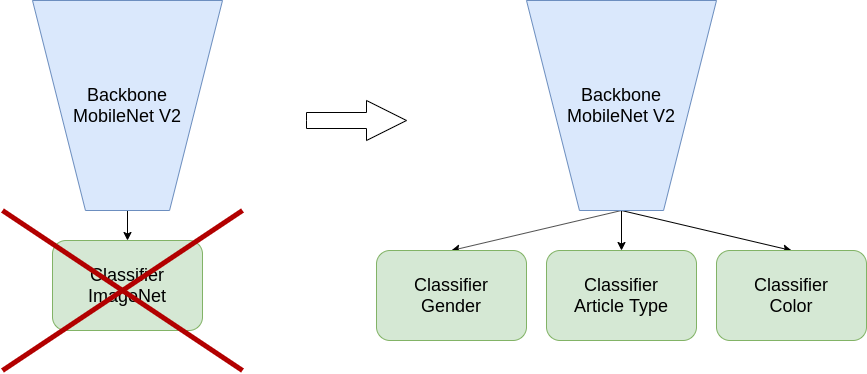
Теперь давайте посмотрим, как мы определяем сеть и эти новые заголовки.
class MultiOutputModel(nn.Module):
def __init__(self, n_color_classes, n_gender_classes, n_article_classes):
super().__init__()
self.base_model = models.mobilenet_v2().features # взять модель без классификатора
last_channel = models.mobilenet_v2().last_channel # размер слоя перед классификатором
# вход для классификатора должен быть двумерным, но у нас
# [<batch_size&qt;, <channels&qt;, <width&qt;, <height&qt;]
# Итак, давайте сделаем пространственное усреднение: уменьшить <width&qt; и <height&qt; до 1
self.pool = nn.AdaptiveAvgPool2D((1, 1))
# создать отдельные классификаторы для наших выходов
self.color = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=last_channel, out_features=n_color_classes)
)
self.gender = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=last_channel, out_features=n_gender_classes)
)
self.article = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=last_channel, out_features=n_article_classes)
)
При прямом прохождении через сеть мы дополнительно усредняем по последним двум тензорным измерениям (ширине и высоте), используя адаптивный средний пул. Мы делаем это, чтобы получить тензор, подходящий в качестве входных данных для наших классификаторов. Обратите внимание, что мы применяем каждый классификатор параллельно к выходу сети и возвращаем словарь с тремя полученными значениями:
def forward(self, x):
x = self.base_model(x)
x = self.pool(x)
# reshape from [batch, channels, 1, 1] to [batch, channels] to put it into classifier
x = torch.flatten(x, start_dim=1)
return {
'color': self.color(x),
'gender': self.gender(x),
'article': self.article(x)
}
Теперь давайте определим нашу потерю для мульти-выходной сети. Фактически, мы просто определим нашу потерю как сумму трех потерь — для цвета, пола и заголовков статьи:
def get_loss(self, net_output, ground_truth):
color_loss = F.cross_entropy(net_output['color'], ground_truth['color_labels'])
gender_loss = F.cross_entropy(net_output['gender'], ground_truth['gender_labels'])
article_loss = F.cross_entropy(net_output['article'], ground_truth['article_labels'])
loss = color_loss + gender_loss + article_loss
return loss, {'color': color_loss, 'gender': gender_loss, 'article': article_loss}
Теперь у нас есть готовая модель и данные. Давайте начнем обучение.
Обучение
Процедура обучения для случая классификации с несколькими выходами такая же, как и для задачи классификации с одним выходом, поэтому здесь я упомяну только несколько шагов. Вы можете обратиться к для получения дополнительной информации о том, как код обучающего конвейера в PyTorch.
Сначала определим несколько параметров обучения и саму модель.
Здесь я использую небольшой размер пакета, так как в этом случае он обеспечивает лучшую точность. Вы можете поэкспериментировать с различными значениями (например, 128 или 256) и проверить это самостоятельно — время обучения уменьшится, но качество может пострадать.
N_epochs = 50
batch_size = 16
...
model = MultiOutputModel(n_color_classes=attributes.num_colors, n_gender_classes=attributes.num_genders,
n_article_classes=attributes.num_articles).to(device)
optimizer = torch.optim.Adam(model.parameters())
Then we run the training in the main loop:
for epoch in range(start_epoch, N_epochs + 1):
...
for batch in train_dataloader:
optimizer.zero_grad()
...
подать пакет данных в сеть:
img = batch['img'] target_labels = batch['labels'] ... output = model(img.to(device)) ...
Рассчитать потери и точность:
loss_train.backward() optimizer.step() ...
И, наконец, мы распространяем ошибку через нашу модель и применяем полученные весовые обновления:
loss_train.backward() optimizer.step() ...
Каждые 5 эпох мы запускаем оценку для набора данных проверки и сохраняем контрольную точку каждые 25 эпох:
if epoch % 5 == 0:
validate(model, val_dataloader, attributes, logger, epoch, device)
if epoch % 25 == 0:
checkpoint_save(model, savedir, epoch)
...
Оценка качества
Вернемся на минуту к задаче классификации с одним выходом. Что такое показатель по умолчанию для этой проблемы? Это точность. Определение точности в простейшем случае (мы не учитываем дисбаланс классов) — это количество правильных прогнозов среди всех данных, которые мы передали в модель:
accuracy = \frac{\#correct\ predictions}{dataset\ size}
Каким должен быть показатель для нашей задачи классификации с несколькими выходами? Действительно, мы все еще можем использовать точность! Напомним, что у нас есть несколько независимых выходов из сети — по одному на каждую метку. Мы можем рассчитать точность для каждой метки независимо так же, как мы это делали для классификации с одним выходом.
Сначала мы должны передать изображения из набора данных в модель и получить прогнозы. В приведенном ниже коде мы сделаем это для класса «color», но процесс будет одинаковым для всех классов, которые мы использовали для обучения:
# перевести модель в режим оценки
model.eval()
# инициализировать хранилище для обоснованной правдоподобности предсказанных меток
predicted_color_all = []
gt_color_all = []
# просмотреть все изображения
for batch in dataloader:
images = batch["img"]
# мы собираемся построить матрицу путаницы для предсказаний "color"
gt_colors = batch["labels"]["color_labels"]
target_labels = {"color": gr_colors.to(device)}
# получить выходные данные модели
output = model(images.to(device))
# получить наиболее уверенный прогноз для каждого изображения
_, predicted_colors = output["color"].cpu().max(1)
predicted_color_all.extend(
prediction.item() for prediction in predicted_colors
)
gt_color_all.extend(
gt_color.item() for gt_color in gt_colors
)
Далее, имея все прогнозы и метки в руках, мы можем вычислить точность. Чтобы быть точным, мы можем вычислить точность для каждой партии в цикле вывода модели и усреднить ее по партиям. По мере того, как мы будем использовать прогнозы и основные значения истинности, давайте оставим их и сделаем вычисления точности вне цикла:
from sklearn.metrics import accuracy_score accuracy_color = accuracy_score(gt_color_all, predicted_color_all)
Если мы посмотрим на метрики, то увидим, что окончательная модель имеет точность ~ 80% для article, 82% для gender и 60% для color.
Эти значения хороши, но не велики. Давайте посмотрим на изображения и прогнозные метки в тестовом наборе данных:
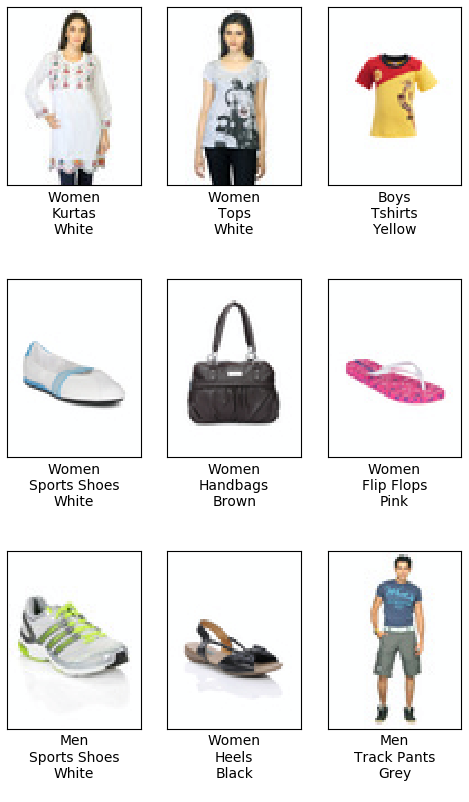
Большинство прогнозов выглядят вполне разумно, так что же пошло не так?
Матрица ошибок
Confusion Matrix (матрица ошибок) — это отличный инструмент для отладки вашей модели классификации изображений. Используя его, вы можете получить ценную информацию о том, какие классы ваша модель хорошо распознает, а какие не очень. Вот некоторая о матрицах ошибок, если вам нужно больше подробностей о том, как они работают.
Для построения сюжета матрицы ошибок, первое, что нужно, это предсказания модели. И да, именно поэтому мы сохранили их раньше!
Поскольку у нас есть прогнозы и обоснованные правдободобные метки, мы готовы построить матрицу ошибок:
from sklearn.metrics import (
confusion_matrix,
ConfusionMatrixDisplay
)
...
cn_matrix = confusion_matrix(
y_true=gt_color_all,
y_pred=predicted_color_all,
labels=attributes.color_labels,
normalize="true",
)
ConfusionMatrixDisplay(cn_matrix, attributes.color_labels).plot(
include_values=False, xticks_rotation="vertical"
)
plt.title("Colors")
plt.tight_layout()
plt.show()
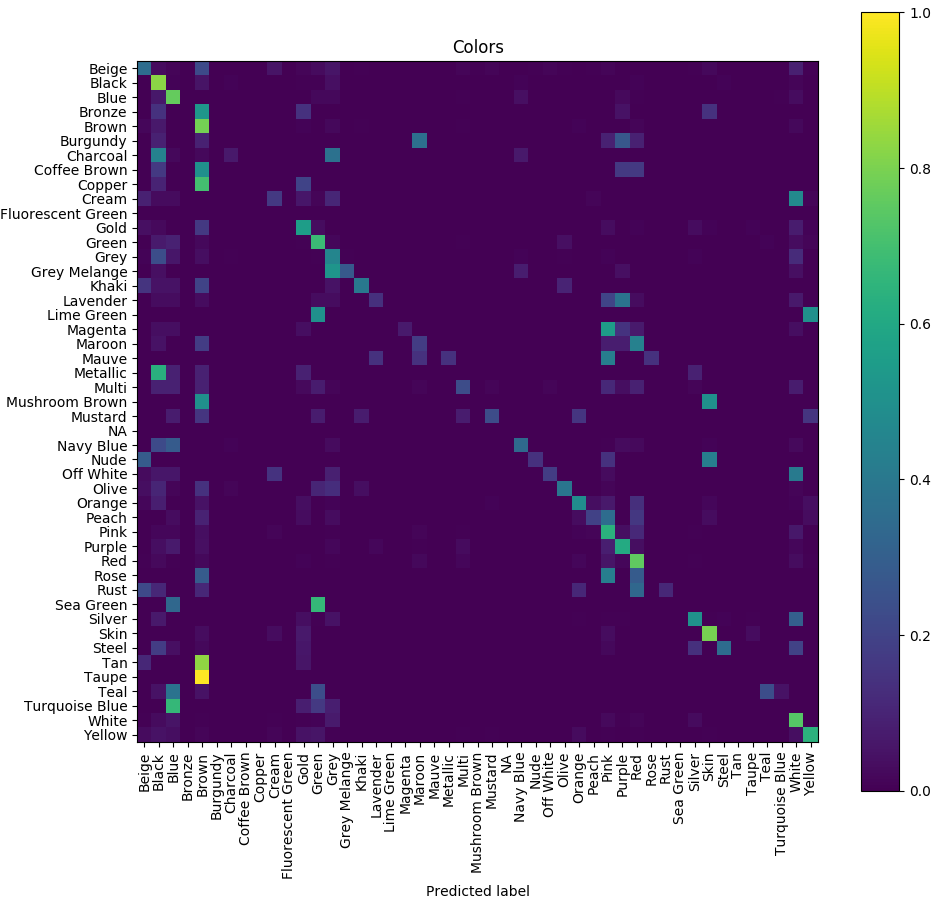
Теперь понятно, что модель смешивает похожие цвета, например, пурпурный, розовый и фиолетовый. Даже человеку порой трудно распознать все 47 цветов, представленных в наборе данных.

Как мы видим, низкая точность цветопередачи не является большой проблемой. Если вы хотите исправить это, то можете уменьшить количество цветов в наборе данных, например, до 10, повторно сопоставив сходные цвета с одним классом, а затем повторно обучив модель. Уверяю вас, результат будет лучше.
С меткой gender мы видим похожее поведение:
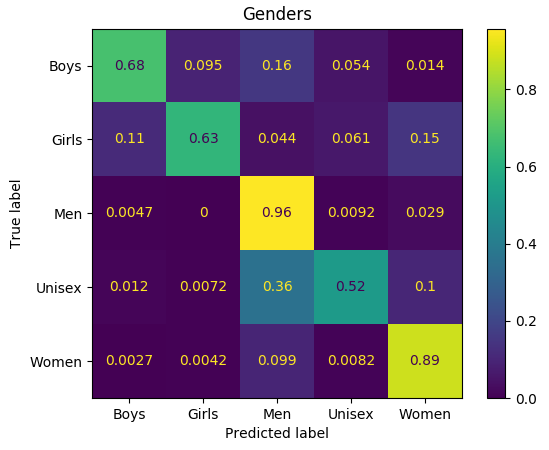
Модель смешивает ярлыки «девушки» и «женщины», «мужчины» и «унисекс». Опять же, для людей иногда бывает также трудно определить правильные ярлыки одежды в этих случаях.

И наконец, матрица ошибок для одежды и аксессуаров. Обратите внимание, что его главная диагональ довольно четкая, то есть в большинстве случаев предсказанная метка совпадает с истиной:
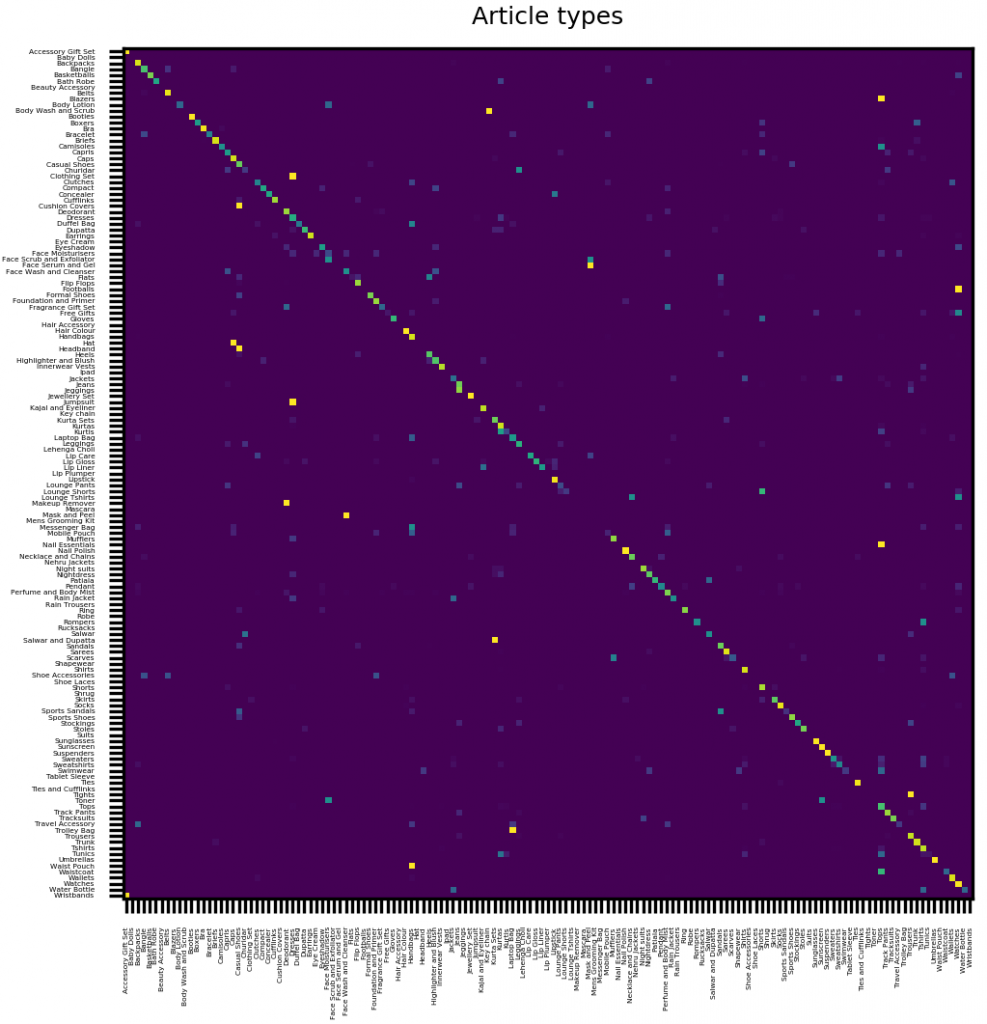
Опять же, некоторые статьи просто трудно отличить — посмотрите на приведённые ниже примеры:

Заключение
В этом уроке мы узнали, как построить модель с несколькими выходами из существующей модели с одним выходом. Мы также показали, как проверить достоверность результатов с помощью матриц ошибок.
В качестве последнего совета, я рекомендую всегда проверять ваш набор данных перед обучением. Таким образом, вы сможете лучше понять свои данные: лучше понять интересующие вас объекты, метки и их распределение в данных и так далее. Как правило, это жизненно важный шаг для того, чтобы ваша модель достигла наилучших результатов.
По мотивам:

![]() Мульти-метки при классификация изображений с PyTorch, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Мульти-метки при классификация изображений с PyTorch, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Респект и уважуха
