
Содержание
- Чем занимаются инженеры по обработке данных?
- Обязанности инженеров по обработке данных
- Общие навыки проектирования данных
- Что не является инженерией данных?
- Заключение
Чем занимаются инженеры по обработке данных?
Инженерия данных — это очень широкая дисциплина, которую каждый называют по своему. Очень часто инженера по обработке данных вообще никак не называют. Вероятно, именно из-за этого лучше сначала определим цели инженерии данных, а затем обсудим, какие работы приносит желаемые результаты. Конечная цель инженерии данных — обеспечить организованный, согласованный поток данных для работ, связанных с их использованием, например:
- Машинное обучение;
- Исследовательский анализ данных;
- Генерация внешних данных для приложений автоматизации.
Для этого есть масса способов, конкретных наборов инструментов и методов, а требуемые навыки широко варьируются в зависимости от команды, организации и желаемых результатов. Однако, конвейер данных стал самым распространенным шаблоном обработки данных. Это система, состоящая из независимых программ, которые выполняют различные операции с входными или собранными данными.
Конвейеры данных часто распределяются между несколькими серверами:
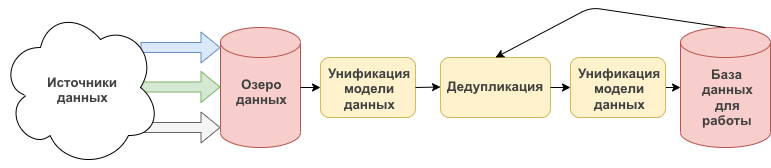
На этой схеме показан упрощенный пример конвейера данных, который дает самое общее представление об архитектуре, с которой можно столкнуться. Ниже вы увидите более сложное представление.
Данные могут поступать из любого источника:
- Устройства Интернет вещейએ.
- Телеметрия автомобиля.
- Каналы данных о недвижимости.
- Обычная активность пользователя в веб-приложении.
- Любые другие инструменты сбора или измерения, которые вы знаете …
В зависимости от природы этих источников входные данные будут обрабатываться в потоках и в реальном времени или с некоторой регулярностью пакетами.
За конвейер, по которому проходят данные, отвечает инженер данных. Группы инженеров данных несут ответственность за проектирование, строительство, обслуживание, расширение и часто инфраструктуру, поддерживающую конвейер данных. Они также могут нести ответственность за входые данные или, чаще всего, за модель данныхએ и то, как эти данные в конечном итоге хранятся.
Если конвейере данных предствлять себе, как приложение, то инженерия данных начинает напоминать любую другую дисциплину программной инженерии.
Сегодня многие команды движутся в сторону создания платформ данных. Во многих организациях недостаточно иметь только один конвейер, сохраняющий входящие данные где-то в базе данных SQL. В крупных организациях есть несколько команд, которым нужны разные уровни доступа к разным видам данных.
Например, командам искусственного интеллекта (AI) могут потребоваться способы пометить и разделить очищенные данные. Группам бизнес-аналитики (BI) может потребоваться простой доступ для агрегирования данных и построения визуализаций данных. Группам по анализу данных может потребоваться база данных — уровень доступа для правильного изучения данных.
Если вы знакомы с веб-разработкой, то можете найти эту структуру похожей на шаблон проектирования Model-View-Controllerએ (MVC) или Модель-Представление-Контроллер. В MVC инженеры данных несут ответственность за модель, команды AI или BI работают над представлениями, а все группы взаимодействуют с контроллером. Создание платформ данных, которые обслуживают все эти потребности, становится основным приоритетом в организациях с разными командами, где полагаются на доступ и использование данных для своего бизнеса.
Теперь, когда вы кое-что узнали из того, чем занимаются инженеры по обработке данных и насколько они важны, было бы полезно узнать немного больше об их клиентах и о тех обязанностях перед ними, которую несут инженеры по обработке данных.
Обязанности инженеров по обработке данных
Клиенты, которые полагаются на инженеров данных, столь же разнообразны, как и навыки и результаты самих групп инженеров данных. Независимо от того, в какой области вы работаете, ваши клиенты всегда будут определять, какие проблемы вы для них решаете и как вы их решаете.
Здесь через призму потребностей в данных перечислим нескольких типичных групп клиентов:
- Команды Data Science и AI;
- Команды бизнес-аналитики или аналитики;
- Продуктовые команды.
Прежде чем любая из этих команд сможет работать эффективно, данные должны отвечать определенным требованиям и обеспечивать:
- Уверенный переход к более широким системам аналитики;
- Быть нормализованными в разумных моделях данных;
- Очищенными и с заполненными важными пробелами;
- Быть доступными для всех участников процессов обработки и исследований.
Эти требования более подробно описаны в прекрасной статье Моники Рогарти «». Как специалист по обработке данных, вы несете ответственность за удовлетворение потребностей своих клиентов в качественных данных. Тем не менее, вы будете использовать различные подходы для удовлетворения индивидуальных требований рабочих процессов исследования данных.
Поток данных
Чтобы сделать что-либо с данными в системе, вы должны сначала убедиться, что они могут надежно поступать в систему и проходить через нее. Входными данными могут быть практически любые типы данных, которые можно себе представить, например:
- Прямые потоки данных JSONએ или XMLએ;
- Пакеты видео, обновляемые каждый час;
- Ежемесячные данные взятия крови;
- Еженедельные галереи изображений с ярлыками;
- Телеметрия с установленных датчиков.
Инженеры данных часто несут ответственность за использование этих данных, проектирование системы, которая может принимать эти данные в качестве входных из одного или нескольких источников, преобразовывать их и затем хранить для своих клиентов. Эти системы часто называют конвейерами ETLએ, что означает извлечение, преобразование и загрузка.
Ответственность за поток данных в основном ложится на этап извлечения. Но ответственность инженера данных не ограничивается их загрузкой в конвейер. Они должны убедиться, что конвейер достаточно надежен, чтобы противостоять неожиданным или искаженным данным, отключению источников при фатальных ошибках. Время безотказной работы очень важно, особенно когда вы используете данные в реальном времени или данные, которые зависят от времени.
Ваша ответственность за поддержание потока данных постоянна и не зависит от того, кто ваш клиент. Однако, некоторые клиенты могут быть более требовательными, чем другие, особенно когда клиентом является приложение, которое полагается исключительно на данные, обновляемые в реальном времени.
Нормализация и моделирование данных
Данные, поступающие в систему, грандиозны. Однако, в какой‑то момент времени данные должны соответствовать некоторому архитектурному стандарту. Нормализация данных включает задачи, которые преврщают данные в более доступные для пользователей. Это включает, но не ограничивается, следующие шаги:
- Удаление дубликатов (дедупликация);
- Исправление противоречивых данных;
- Проверку на соответствие данных указанной модели.
Эти процессы могут происходить на разных этапах. Например, представьте, что вы работаете в большой организации со специалистами по обработке данных и командой бизнес-аналитики, которые полагаются на ваши данные. Вы можете хранить неструктурированные данные в озере данных, которое будет использоваться вашими клиентами из области науки о данных для своих исследований. Вы также можете хранить нормализованные данные в реляционной базе данных или более того, использовать специализированное хранилище данныхએ, которое будет использоваться командой BI в своих отчетах.
У вас может быть больше или меньше групп клиентов или, возможно, приложение, которому «жуёт» ваши данные. На изображении ниже показана модифицированная версия предыдущего примера конвейера:
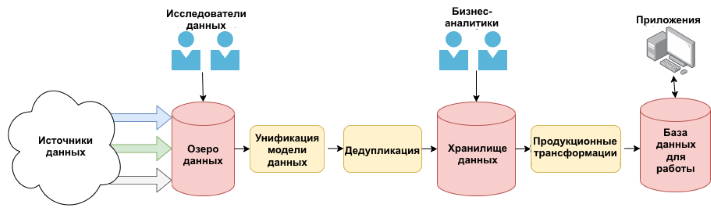
На этом изображении вы видите гипотетический конвейер данных и этапы, на которых часто работают разные группы клиентов.
Если вашим заказчиком является продуктовая команда, решающее значение имеет хорошо спроектированная модель данных. Приложение с продуманной моделью данных может отличаться медлительностью и почти отсутсвующей реакцией, работающее так, как будто оно уже знает, к каким данным пользователь хочет получить доступ. Подобные решения часто являются результатом сотрудничества между группами разработки продукта и данных.
Нормализация и моделирование данных обычно являются частью этапа преобразования ETLએ, но они не единственные в этой категории. Еще один распространенный этап преобразования — очистка данных.
Очистка данных
Очистка данных идет рука об руку с нормализацией. Некоторые даже считают нормализацию данных подмножеством очистки данных. Но в то время как нормализация данных в основном сосредоточена на приведении разрозненных данных в соответствие с некоторой моделью, очистка включает в себя ряд действий, которые делают данные более однородными и полными, в том числе:
- Приведение одних и тех же данных к одному типу (например, );
- Обеспечение единого формата дат;
- Заполнение недостающих значений (по возможности);
- Ограничение значений поля указанным диапазоном;
- Удаление поврежденных или непригодных для использования данных.
Очистка данных может вписаться в этапы дедупликации и унификации модели данных на диаграмме выше. В действительности, однако, каждый из этих шагов очень велик и может включать любое количество стадий и отдельных процессов.
Конкретные действия, которые вы предпринимаете для очистки данных, будут сильно зависеть от входных данных, модели данных и желаемых результатов. Однако, важность чистых данных неоспорима:
- Исследователям данных они необходимы для повышения точности анализа.
- Они необходимы инженерам по машинному обучению для создания точных и обобщаемых моделей.
- Они нужны группам бизнес-аналитики для предоставления точных отчетов и прогнозов для бизнеса.
- Команда разработчиков нуждается в очистке, чтобы гарантировать, что их продукт не дает сбоев и не предоставляет пользователям неверную информацию.
Ответственность за очистку данных ложится на плечи многих и зависит от приоритетов и организации в целом. Как инженеру данных, вам следует стремиться максимально автоматизировать очистку и проводить регулярные выборочные проверки входящих и сохраненных данных. Ваши клиентов и руководство могут дать представление о том, что собой представляют для них чистые данные.
Доступность данных
Доступность данных, как правило, обделена вниманием в сравнении с нормализацией и очисткой, но, возможно, это одна из наиболее важных задач группы разработки данных, ориентированной на клиента.
Доступность данных означает, насколько легко клиенты могут получить доступ к данным и понять их. Это то, что определяется по-разному в зависимости от клиента:
- Группам специалистов по анализу данных могут просто понадобиться данные, доступные с помощью какого-либо языка запросов.
- Команды аналитиков могут предпочесть данные, сгруппированные по некоторой метрике, доступные через базовые запросы или интерфейс отчетности.
- Продуктовым командам часто нужны данные, доступные через быстрые и простые запросы, которые не часто меняются, с учетом производительности и надежности продукта.
Поскольку более крупные организации предоставляют этим и другим группам одни и те же данные, многие из них перешли к разработке собственных внутренних платформ для своих разрозненных команд. Отличным зрелым примером этого является сервис такси Uber, который поделился многими деталями своей впечатляющей .
Фактически, многие инженеры по обработке данных становятся инженерами платформ, что дает понять непреходящую важность навыков проектирования данных для предприятий, основанных на данных.
Поскольку доступность данных тесно связана с тем, как данные хранятся, это основной компонент этапа загрузки ETL, который относится к тому, как данные хранятся для дальнейшего использования.
Теперь, когда вы познакомились с некоторыми типичными заказчиками инженерии данных и узнали об их потребностях, пришло время более внимательно изучить, какие навыки вы можете развить, чтобы удовлетворить эти потребности.
Общие навыки проектирования данных
Навыки инженерии данных во многом совпадают с навыками, необходимыми для разработки программного обеспечения. Однако, есть несколько областей, которым инженеры по обработке данных, как правило, уделяют большее внимание. Здесь о нескольких важных компетенциях:
- Общие концепции программирования;
- Базы данных;
- Распределенные системы и облачная инженерия.
Каждая из них играет решающую роль в том, чтобы сделает из вас квалифицированных инженеров данных.
Навыки программирования
Инжиниринг данных — это специализация разработки программного обеспечения, поэтому логично, что основы разработки программного обеспечения находятся в верхней части этого списка. Как и в случае с другими специализациями программной инженерии, инженеры по данным должны понимать такие концепции проектирования, как DRY (don’t repeat yourselfએ), объектно-ориентированное программированиеએ, структуры данныхએ и алгоритмыએ.
Как и в случае с другими специальностями, есть несколько любимых языков. На момент написания этой статьи в описаниях должностей инженеров данных вы чаще всего видите Pythonએ, Scala (язык программирования)એ и Javaએ. Что делает эти языки такими популярными?
Python популярен по нескольким причинам. Одна из самых больших — это его повсеместность. По многим параметрам Python входит в тройку самых популярных языков программирования в мире. Например, он занял второе место в за ноябрь 2020 года и третье место в .
Он также широко используется командами машинного обучения и искусственного интеллекта. Команды, которые работают в тесном сотрудничестве, часто нуждаются в возможности общаться на одном языке, а Python по-прежнему остается лингва-франкаએ в этой области.
Другой, более целевой причиной популярности Python является его использование в инструментах оркестровки, таких как , и доступных библиотеках для популярных инструментов, таких как . Если организация использует подобные инструменты, важно знать языки, которые они используют.
Scalaએ, как и Python, также довольно популярна и отчасти это связано с популярностью инструментов, которые ее используют, особенно . Scala — это функциональный язык, работающий на виртуальной машине Java (JVMએ), позволяя легко использовать его с Javaએ.
Javaએ не так популярна в инженерии данных, но вы все равно увидите ее в описаниях многих вакансий. Частично это связано с его повсеместным распространением в корпоративных стеках программного обеспечения и частично из-за его взаимодействия со Scala. Поскольку Scala используется для Apache Spark, имеет смысл то, что некоторые команды также используют Java.
Помимо общих навыков программирования важно хорошее знакомство с технологиями баз данных.
Технологии баз данных
Если вы собираетесь перемещать данные, вы будете часто использовать базы данных. В очень широком смысле вы можете разделить технологии баз данных на две категории: SQLએ и NoSQLએ.
Базы данных SQL — это системы управления реляционными базами данных (СУБД), которые моделируют отношения и взаимодействуют с ними с помощью языка структурированных запросов или SQL. Они обычно используются для моделирования данных, которые определяются отношениями, например данных о заказах клиентов.
Примечание. Если вы хотите узнать больше о SQL и о том, как взаимодействовать с базами данных SQL в Python, ознакомьтесь с разделом .
NoSQL обычно означает «все остальное». Это базы данных, которые обычно хранят нереляционные данные, например такие:
- Хранилища ключей и значений, такие как Redisએ или DynamoDBએ от AWSએ.
- Хранилища документов, такие как MongoDBએ или Elasticsearchએ.
- Графические базы данных, такие как Neo4jએ.
- Другие, менее распространенные хранилища данных.
Хотя вам не обязательно знать тонкости всех технологий баз данных, вы должны понимать плюсы и минусы этих различных систем и уметь быстро изучить одну или две из них.
Системы, над которыми работают инженеры по данным, все чаще располагаются в облаке, конвейеры данных обычно распределяются по нескольким серверам или кластерам, независимо от того, находятся они в частном облаке или нет. По этой причине будущий инженер по обработке данных должен разбираться в распределенных системах и облачной инженерии.
Распределенные системы и облачная инженерия
Одно из главных преимуществ методов инженерии данных, таких как конвейеры ETLએ, заключается в том, что они подходят для реализации распределенных систем. Распространенным шаблоном является наличие независимых сегментов конвейера, работающих на отдельных серверах, организованных очередью сообщений, например RabbitMQએ или Apache Kafkaએ.
Важно понимать, как проектировать эти системы, каковы их преимущества и риски, а также когда их следует использовать.
Для этих систем требуется много серверов, и географически распределенным командам часто требуется доступ к данным, которые они содержат. Поставщики частного облака, такие как Amazon Web Servicesએ, Google Cloudએ и Microsoft Azureએ — чрезвычайно популярные инструменты для создания и развертывания распределенных систем.
Базовое понимание основных предложений облачных провайдеров, а также некоторых из наиболее популярных инструментов распределенного обмена сообщениями поможет вам найти свою первую работу по проектированию данных. Вы можете рассчитывать на более глубокое изучение этих инструментов в процессе работы.
К настоящему времени вы много узнали о том, что такое инженерия данных. Но поскольку нет стандартного определения дисциплины и существует множество взаимосвязанных дисциплин, вы также должны иметь представление о том, что не является инженерией данных.
Что не является инженерией данных?
Многие области тесно связаны с обработкой данных и ваши клиенты часто будут участниками этих областей. Важно знать своих клиентов, поэтому вы должны знать эти области и то, что их отличает от инженерии данных.
Вот некоторые из областей, которые тесно связаны с инженерией данных:
- Наука о данных.
- Бизнес-аналитика.
- Машинное обучение.
В этом разделе вы подробнее познакомитесь с этими областями, начиная с науки о данных.
Наука о данных
Если инженерия данных определяется тем, как вы перемещаете и систематизируете огромные объемы данных, то наука о данных определяется тем, что вы делаете с этими данными.
Специалисты по обработке данных обычно запрашивают, исследуют и пытаются извлечь ценную информацию из наборов данных. Они могут писать разовые сценарии для использования с конкретным набором данных, в то время как инженеры по обработке данных стремятся создавать программы многократного использования, используя передовой опыт разработки программного обеспечения.
Специалисты по обработке данных используют статистические инструменты, такие как и , а также методы машинного обучения. Они часто работают с R или Python и пытаются получить идеи и прогнозы на основе данных, которые помогут принять решение на всех уровнях бизнеса.
Примечание: вы хотите изучить науку о данных? Взгляните на любой из следующих разделов:
- .
- .
- .
- .
Специалисты по обработке данных часто имеют научную или статистическую подготовку и их стиль работы отражает это. Они работают над проектом, который отвечает на конкретный исследовательский вопрос, в то время как группа инженеров данных фокусируется на создании расширяемых, многоразовых и быстрых внутренних продуктов.
Отличный пример того, как специалисты по данным отвечают на вопросы исследований, можно найти в компаниях, занимающихся биотехнологиями и технологиями в области здравоохранения, где специалисты по обработке данных исследуют данные о лекарственных взаимодействиях, побочных эффектах, исходах болезней и многом другом.
Бизнес-аналитика
Бизнес-аналитика похожа на науку о данных с некоторыми важными отличиями. Там, где наука о данных сосредоточена на прогнозировании и прогнозировании будущего, бизнес-аналитика сосредоточена на предоставлении обзора текущего состояния бизнеса.
Обе эти группы обслуживаются группами разработки данных и могут даже работать с одним и тем же пулом данных. Однако бизнес-аналитика занимается анализом эффективности бизнеса и созданием отчетов на основе данных. Эти отчеты затем помогают руководству принимать решения на уровне бизнеса.
Как и специалисты по данным, команды бизнес-аналитики полагаются на инженеров по обработке данных для создания инструментов, которые позволяют им анализировать данные, относящиеся к их сфере деятельности, и составлять отчеты по ним.
Машинное обучение
Инженеры по машинному обучению — еще одна группа, с которой вы часто будете контактировать. Вы можете выполнять с ними аналогичную работу или даже быть частью команды инженеров по машинному обучению.
Как и инженеры по обработке данных, инженеры по машинному обучению больше ориентированы на создание программного обеспечения многократного использования, и многие из них имеют опыт работы в области компьютерных наук. Тем не менее, они меньше сосредоточены на создании приложений и больше сосредоточены на создании моделей машинного обучения или разработке новых алгоритмов, которые будут использоваться в моделях.
Примечание. Если вас интересует машинное обучение, ознакомьтесь с планом обучения .
Модели, которые создают инженеры по машинному обучению, часто используются продуктовыми группами в продуктах, ориентированных на клиентов. Данные, которые вы предоставляете как специалист по обработке данных, будут использоваться для обучения их моделей, что сделает вашу работу основой возможностей любой группы машинного обучения, с которой вы работаете.
Например, инженер по машинному обучению может разработать новый алгоритм рекомендаций для продукта вашей компании, а инженер по обработке данных предоставит данные, используемые для обучения и тестирования этого алгоритма.
Важно понимать, что области, на которые вы здесь смотрели, часто нечеткие. Люди с наукой о данных, BI или опыт машинного обучения может выполнять работу по инжинирингу данных в организации, и как инженер по обработке данных вас могут попросить помочь этим командам в их работе.
В один прекрасный день вы можете изменить архитектуру модели данных, в другой — создать инструмент маркировки данных, а после этого оптимизировать внутреннюю структуру глубокого обучения.Хорошие инженеры по обработке данных гибки, любопытны и готовы пробовать новое.
Заключение
На этом ваше знакомство с инженерией данных — одной из самых востребованных дисциплин для людей с опытом или интересом в области компьютерных наук и технологий!
Здесь вы узнали:
- Чем занимаются инженеры по данным.
- Кто клиенты данных инженеров.
- Какие навыки общие для инженерии данных.
- Что не является инженерией данных.
Теперь вы находитесь в той точке, где вы можете решить, хотите ли вы углубиться и узнать больше об этой захватывающей области. Вам нравится инженерия данных? Вы заинтересованы в его более глубоком изучении? Дайте нам знать об этом в комментариях!
По мотивам

![]() Что такое инженерия данных и подходит ли она вам?, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Что такое инженерия данных и подходит ли она вам?, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Респект и уважуха
