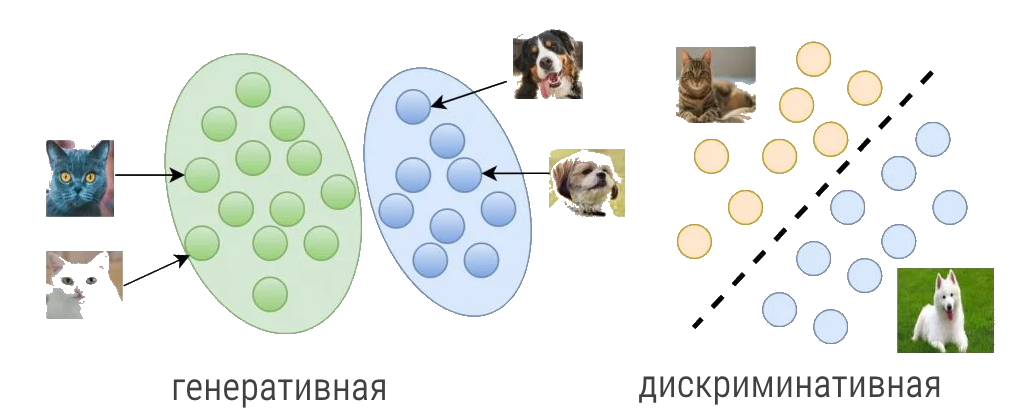
Большинство задач, которые вы решаете в области машинного и глубокого обучения, основываны на генеративной и дискриминативной моделях. В машинном обучении нужно четко различать два типа моделирования:
- Классификация изображения, например, собаки или кошки, которое подпадает под дискриминативное моделирование.
- Создание реалистичного изображения, той же собаки или кошки — задача генеративного моделирования.
Чем больше нейронные сети вторгаются в нашу жизнь, тем больше разрастаются области генеративного и дискриминативного моделирования. Для понимания алгоритмов, основанных на этих моделях, необходимо изучить теорию и все концепции моделирования.
Что нужно для взлёта? ↑
Базовое понимание машинного обучения и глубокого обучения — это то, с чего нужно начать. После того, как появится основа, переходите к более сложным темам, таким как генеративные состязательные сети или GAN. Если у вас есть какой-то опыт в задачах классификации изображений (дискриминация) или реконструкции изображений (генерация), то это будет значительным бонусом. Не понимать, что именно скрывается под капотом и как моделируются проблемы — это нормально.
Содержание
Как уже упоминалось, нормально не иметь ноу-хау или глубокого понимания того, как все работает. В этом посте мы обсудим детали и попытаемся добиться интуитивного понимания:
- Что такое «дискриминативное» моделирование?
- Несколько распространённых дискриминативных моделей.
- Что такое «генеративное» моделирование?
- Несколько примечательных скрытых вариативные дискриминативных моделей.
- Сравнение дискриминативного и генеративного моделирования.
- Заключение
Что такое «дискриминативное» моделирование? ↑
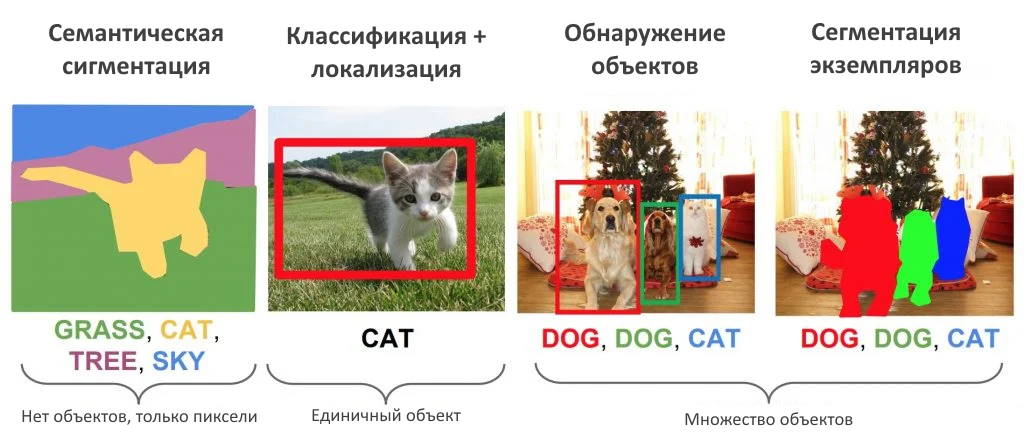
Что может дискриминативное моделирование?
Многие из вас, возможно, уже использовали дискриминативное моделирование для решения проблемы классификации в машинном обучении или глубоком обучении. Будучи надмножеством алгоритмов машинного обучения и глубокого обучения, дискриминативное моделирование не ограничивается задачами классификации. Оно также широко используется при обнаружении объектов, семантической сегментации, паноптической сегментации., обнаружение ключевых точек, проблемы регрессии и языкового моделирования.
Дискриминантная модель относится к контролируемой ветви обучения. В задаче классификации, учитывая, что данные помечены, он пытается различать классы, например, автомобиль, светофор и грузовик. Эти модели, также известные как классификаторы, соответствуют образцам изображений X меткам классов Y, и определить вероятность принадлежности образца изображения x \in X к метке класса y \in Y.
Они учатся моделировать границы принятия решений среди классов (например, кошек, собак и тигров). Граница решения может быть линейной или нелинейной. Точки данных, которые находятся далеко от границы принятия решения (т. е. Выбросы), не очень важны. Дискриминантная модель пытается определить границу, которая отделяет положительный класс от отрицательного, и предлагает границу принятия решения. Учитываются только те, кто находится ближе всего к этой границе.
Дискриминантные модели классифицируют точки данных, не предоставляя модели того, как эти точки были созданы.
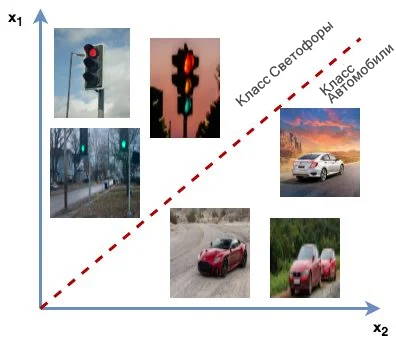
Пытаясь классифицировать образец x, принадлежащий метке класса y, дискриминативная модель косвенно изучает определенные особенности набора данных, которые облегчают ее задачу. Например, у автомобиля четыре колеса круглой формы и длина больше, чем ширина, а светофор вертикальный с тремя круговыми кольцами. Эти функции помогают модели различать два класса.
Модели могут быть:
- Вероятностными:
- логистическая регрессия;
- глубокая нейронная сеть, которая моделирует P(Y|X);
- Не вероятностными:
- Поддержка векторной машины (SVMએ), которая пытается изучить сопоставления непосредственно из точек данных в классы с гиперплоскостью.
Дискриминационное моделирование учится моделировать условную вероятность метки класса y с учетом набора характеристик x как P(Y|X).
Некоторые известные дискриминативные модели ↑
Обсудим несколько известных дискриминативных моделей:
- Support Vector Machine (Машина опорных векторов)
- Logistic Regression (Логистическая регрессия)
- k-Nearest Neighbour (kNN или k-ближайший сосед)
- Random Forest (Случайный лес)
- Deep Neural Network (Глубокая нейронная сеть, например, AlexNet, VGGNet и ResNet)
Давайте изучим несколько отличительных моделей и обнаружим их характерные особенности.
Машина опорных векторов
Машина опорных векторов (SVM) — это непараметрический метод контролируемого обучения, очень популярный среди инженеров, поскольку он дает отличные результаты при значительно меньших вычислительных ресурсах. Алгоритм машинного обучения может применяться как к задачам классификации (вывод детерминирован), так и к задачам регрессии (вывод непрерывен). Он широко используется при классификации текста, классификации изображений, классификации белков и генов.
Знаменитая модель обнаружения объектов на основе глубокого обучения, известная как Regions with CNN (R-CNN), использует SVM для классификации объектов в ограничивающих прямоугольниках. В этой статье авторы использовали линейные SVM для конкретных классов для классификации каждой области изображения.
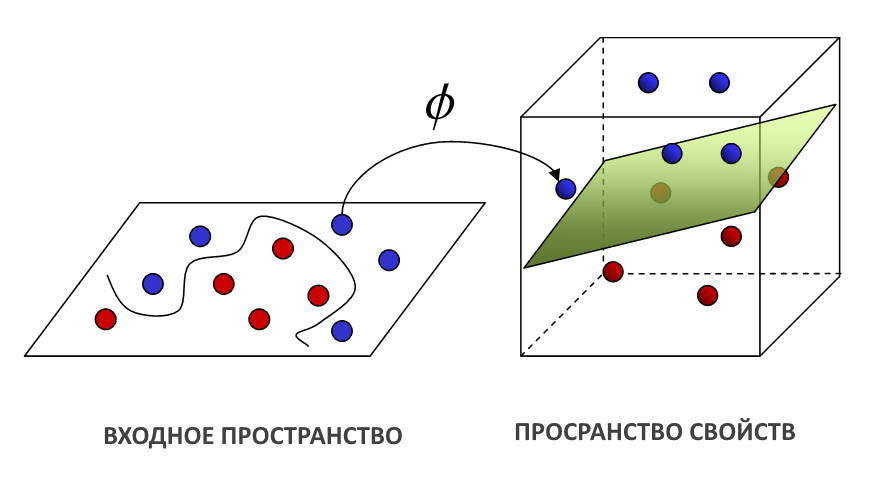
SVM может разделять как линейные, так и нелинейные точки данных. Уловка с ядром помогает разделить нелинейные точки. Не имея ядра, Linear SVM находит решением проблемы поиском гиперплоскости с максимально линейными границами. Граничные точки в пространстве признаков называются опорными векторами (как показано на рисунке выше). Исходя из их взаимного расположения, выводится максимальный запас и в средней точке рисуется оптимальная гиперплоскость.
Гиперплоскость имеет размерность N-1, где N — количество объектов, присутствующих в данном наборе данных. Например, линия будет указывать границу решения, если набор данных имеет две функции (2d входное пространство).
Зачем нужна гиперплоскость с максимальным запасом?
Граница решения с максимальным запасом работает лучше всего, увеличивает шанс обобщения. Достаточная свобода для граничных точек снижает вероятность ошибочной классификации. С другой стороны, граница принятия решения с меньшим запасом обычно приводит к переобучению.
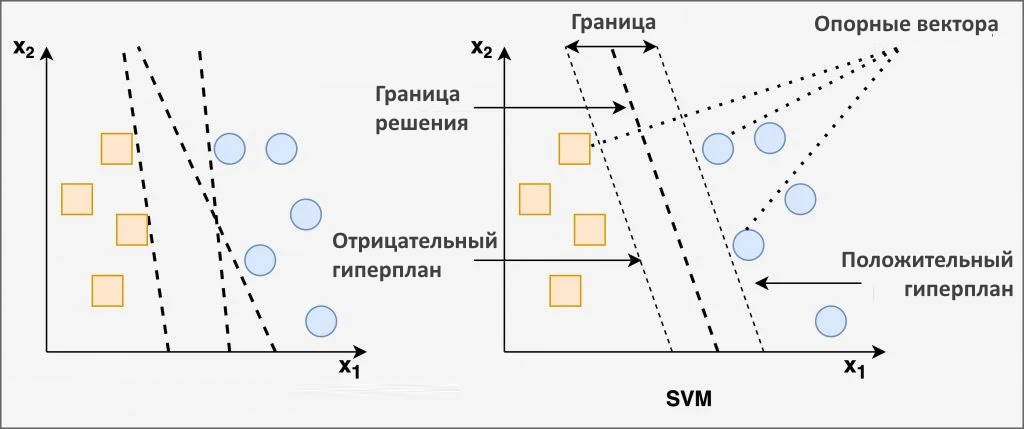
Когда точки данных не разделены линейным образом, используется нелинейная SVM. Функция ядра или трюк с ядром помогают получить новую гиперплоскость для всех данных обучения. Как показано на рисунке выше, пространство ввода проецируется в пространство функций более высокого измерения, таким образом, чтобы распределение точек данных в новой гиперплоскости было линейным. Различные уловки ядра, такие как полиномиальная и радиальная базисная функция, используются для решения задач нелинейной классификации с помощью SVM.
SVM можно использовать в готовом виде. Просто импортируйте модуль SVM из библиотеки sklearn.
from sklearn import svm
Случайный лес
Как и SVM, Random Forestએ также относится к классу дискриминативного моделирования. Это один из самых популярных и мощных алгоритмов машинного обучения для классификации и регрессии. Random Forest стал хитом сообщества Kaggle, так как помог выиграть множество соревнований.
Это совокупность моделей дерева решений. Следовательно, чтобы понять алгоритм случайного леса, вам необходимо знать деревья решений.
Microsoft обучила глубокий рандомизированный классификатор леса решений для на основе изображения с одной глубиной. Не было временной информации, использовались сотни тысяч обучающих образов.
Итак, что такое деревья решений?
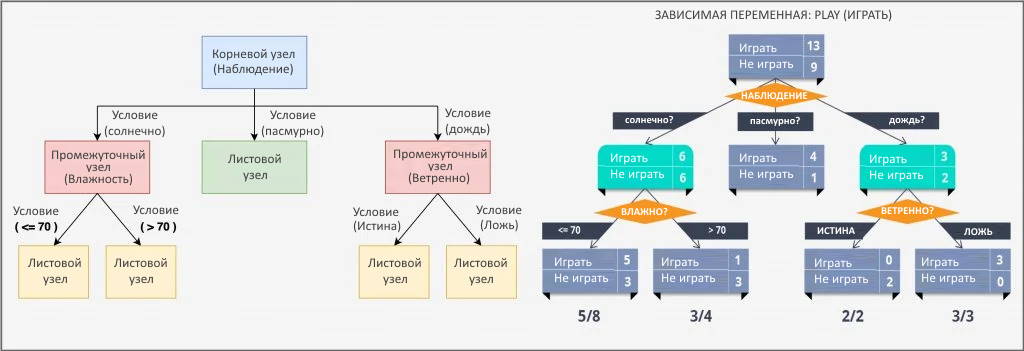
Дерево решений — это непараметрический алгоритм с контролируемым обучением, используемый как в задачах классификации, так и в задачах регрессии. Однако, он преимущественно используется для классификации. Дерево решений постепенно разбивает данные на более мелкие группы на основе определенных атрибутов, пока они не достигнут конца, где данные можно назвать меткой. Как только он научится моделировать данные с помощью меток, он пытается соответствующим образом пометить набор тестов. Это классификатор с древовидной структурой, состоящий из корневого узла, промежуточного или решающего узла и листового узла.
Данные представлены в виде древовидной структуры, где каждый:
- внутренний узел обозначает проверку атрибута (в основном условие)
- ветка представляет собой результат теста
- листовой узел содержит метку класса
Деревья решений можно разделить на два типа:
- Если целевая переменная категориальна (как показано на рисунке выше), то
- предсказывает одну из двух категорий: играть или не играть.
- возможность определить: вид (солнечно, ветрено, дождливо), влажность и ветер. Дерево решений учится на этих функциях, и после прохождения каждой точки данных через каждый узел оно попадает в конечный узел одной из двух категориальных целей (играть или не играть).
- Когда целевые переменные непрерывны. Например, прогноз цены дома на основе различных характеристик дома.
Разбиение в деревьях решений может быть:
- бинарным (да/нет)
- многозначным (солнечно, дождливо, пасмурно)
Деревья решений анализируют все функции данных, чтобы найти те, которые разделяют данные обучения на подмножества, чтобы получить наилучшие результаты классификации. На этапе обучения также определяется, какие атрибуты данных будут корневым узлом, ветвями и промежуточными. Данные рекурсивно разделяются, пока дерево не достигнет листового узла. То, как разделяется дерево решений, регулируется индексом Джини или энтропией — двумя критериями для выбора промежуточных (условий) узлов.
Деревья решений обычно используют метрику индекс Джиниએ для создания точек принятия решений, которые показывают, насколько точно данные были разделены.
- Когда все наблюдения принадлежат одному ярлыку, это идеальная классификация, и индекс Джини равен нулю (наилучшая).
- Когда наблюдения поровну разделены между ярлыками, значение индекса Джини равно единице (наихудшая).
Модуль дерева решений можно импортировать из библиотеки sklearn.
from sklearn.tree import DecisionTreeClassifier
С учётом всего того, что вы узнали о деревьях решений, попробуем разобраться со случайным лесом (Random Forestએ).
Импортируйте алгоритм случайного леса прямо из библиотеки sklearn.
from sklearn.ensemble import RandomForestClassifier
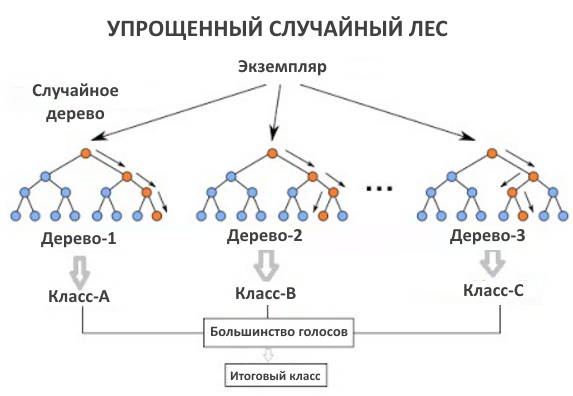
Поскольку образцы начальной загрузки тренируют алгоритм случайного леса, случайные выборки или точки данных могут быть взяты из набора данных с заменой.
Для объединения деревьев решений Random Forest использует метод упаковки. Однако этот немного отличается от обычной упаковки. Вместо использования всех функций случайного леса, нарисуйте его случайные подмножества для обучения каждого дерева. Случайный выбор признаков дает деревьям большую независимость. Затем каждое дерево может собирать уникальную информацию из набора данных, что, в свою очередь, улучшает точность модели и время обучения. После объединения всех деревьев он вычисляет окончательный результат, используя большинство голосов. Метка с максимальным количеством голосов называется окончательным предсказанием.
Глубокая нейронная сеть
Чтобы понять глубокие нейронные сети, вернитесь в прошлое и сначала познакомьтесь с и .
Линейная регрессия
Как следует из названия, это регрессионная модель и алгоритм обучения с учителем. Таким образом, он вводит переменные для вывода непрерывной цели, такой как цена акций, прогнозы цен на жилье и т. д. Кроме того, поскольку он является параметрическим алгоритмом машинного обучения, некоторые из его параметров изучаются на этапе обучения. Линейная регрессия пытается найти границу линейного решения. Алгоритм довольно простой и интуитивно понятный и основан на уравнении прямой из двух точек: y = mx + b, где y — зависимая переменная (прогнозируемая выходная ось y), m — наклон линии, x — независимая входная переменная (ось x), а b — точка пересечения с y.
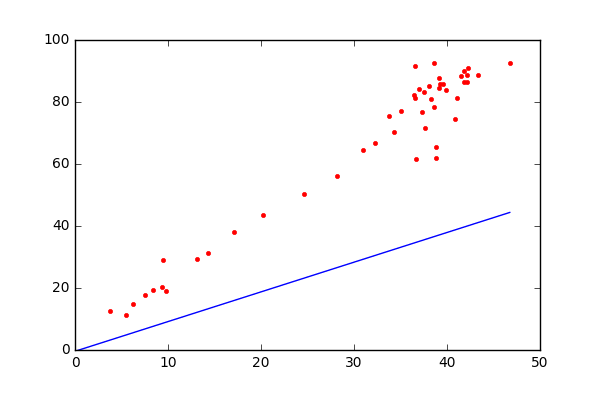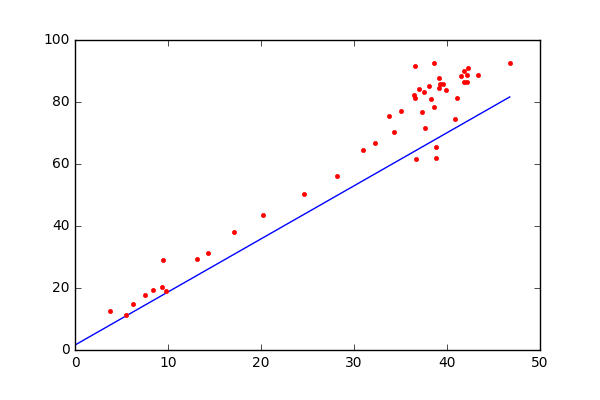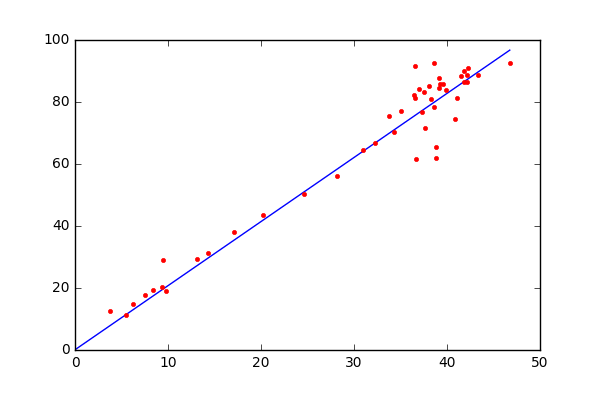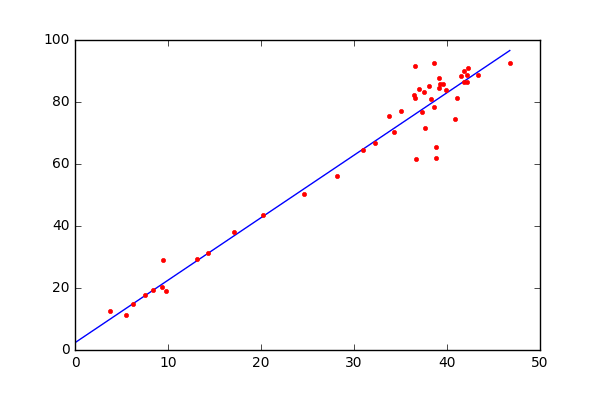
Чтобы немного упростить, предположим, что x — это площадь дома (в квадратных футах), а y — его цена. Переменные m и b инициализируются случайным образом, и их значения обновляются до тех пор, пока потеря (среднеквадратическая ошибка) между предсказанием (\hat{y}) и истинным значением (y) не станет минимальной (не уменьшается далее).
От линейной к логистической регрессии
Логистическая регрессия
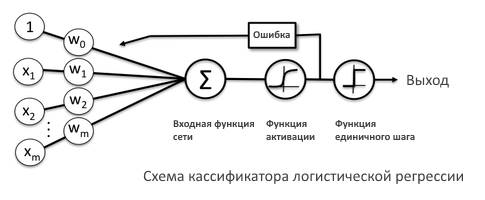
Логистическая регрессия — это параметрический алгоритм с контролируемым обучением, используемый для решения задач классификации. Это обобщенный линейный алгоритм машинного обучения, потому что результат всегда зависит от суммы входных данных и параметров. Но пусть вас не смущает его название. Добавление логистической функции к построенной линейной регрессии логистической регрессии. Это было сделано для преобразования целевой переменной из непрерывной в детерминированную и с ограничением от 0 до 1.

На приведенном выше рисунке показана логистическая функция, также известная как функция активации сигмоидаએ, которая принимает действительное число (x) и сжимает его в диапазоне от 0 до 1. Она преобразует большие отрицательные числа в 0, а большие положительные числа в 1.
Модифицированное уравнение линейной регрессии можно представить в виде y = \sigma (mx + b), где \sigma — сигмоида. Как и в случае линейной регрессии, здесь параметры обновляются путем вычисления потерь между предсказанным выходом и истинной меткой. В качестве функции потерь используется бинарная функция кросс-энтропии.
Возьмем простой пример классификации изображений кошек и собак. Логистическая регрессия возьмет входное изображение x и выведите значение от 0 до 1. Предположим, что истинная метка для кошки равна 0, а для собаки 1. Когда вы вводите изображение кошки, модель предсказывает 0,2 в качестве вывода. Затем будут вычислены потери между истинной меткой: 0 и прогнозируемым выходным значением: 0,2 и параметры будут соответствующим образом обновлены.
Импортируйте модуль логистической регрессии из библиотеки sklearn:
from sklearn.linear_model import LogisticRegression
Теперь погрузимся в глубокие нейронные сети
Ошибка классификаторов изображений (%)
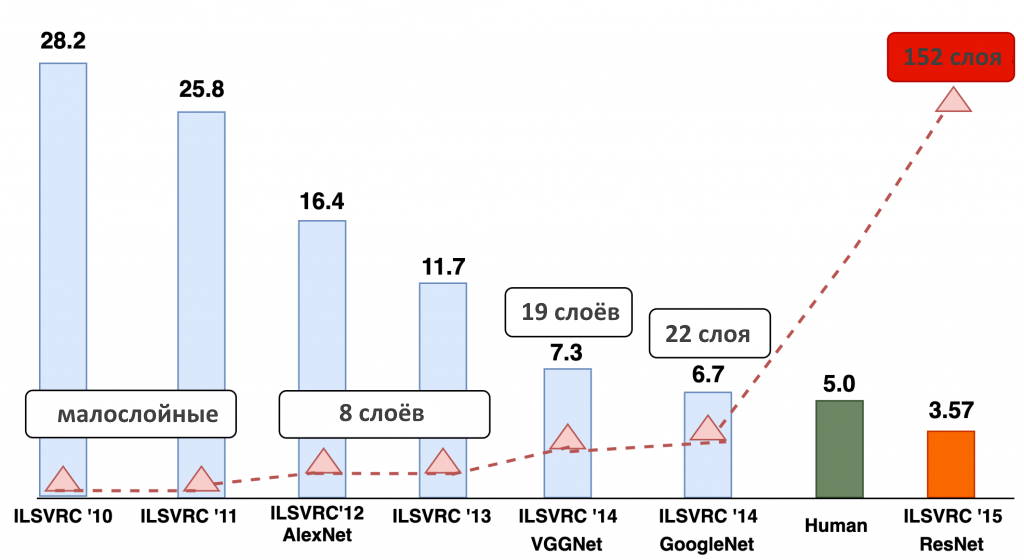
На приведенном выше рисунке показано, насколько глубокие нейронные сети, широко известные как Deep Learningએ, продвинулись за последние годы. Режим классификации был протестирован на знаменитом конкурсе Imagenet Large Scale Visual Recognition Challengeએ (ILSVRC). Вы обнаружите, что машина (ResNet) достигла максимальной оценки 3,57.5 и превзошел 5% -й коэффициент ошибок, связанных с действиями человека. Разве это не потрясающе? На приведенном выше рисунке отмечен еще один интересный момент: по мере увеличения количества слоев в нейронных сетях росла и производительность модели.
Глубокие нейронные сети (DNN), глубокое обучениеએ привлекательно, сложностью архитектуры, имитирующей человеческий мозг. С 2012 года сверточные нейронные сетиએ (CNN) значительно превосходят дескрипторы, созданные вручную или малослойными сетями.
Созданные вручную дескрипторы (LBP, SIFT) — это функции, извлеченные с помощью руководства, предопределенный алгоритм для настройки нескольких параметров, которые не могут быть хорошо обобщены для набора данных.
- Традиционные дескрипторы, созданные вручную, явно извлекают функции.
- В нейронных сетях функции изучаются по своей сути как часть обучения, которое является более общим для данных. Неудивительно, что нейронные сети известны как отличные экстракторы функций.
Неглубокие нейронные сети в сравнении с глубокими: неглубокие нейронные сети не являются глубокими и обычно имеют только один скрытый слой. Глубокая нейронная сеть может иметь до 152 слоев (архитектура ResNet).
Известные как отличные аппроксиматоры функций, нейронные сети имеют три типа слоев: входной, скрытый и выходной. Скрытый слой — это то место, где и происходит вся магия.
- Как логистическая регрессия связана с нейронными сетями? По сути, логистическая регрессия похожа на однослойную нейронную сеть. Напротив, глубокие нейронные сети представляют собой сложенные логистические регрессии.
- Помните, что в логистической регрессии вы использовали сигмовидную функцию активации для изучения нелинейности, которая имела свои собственные оговорки. Однако глубокие нейронные сети используют более эффективные наборы функций активации, такие как ReLU, PReLU и Swish. Они превзошли сигмоид и еще больше повысили производительность нейронных сетей, сделав их больше, чем просто «глубокими».

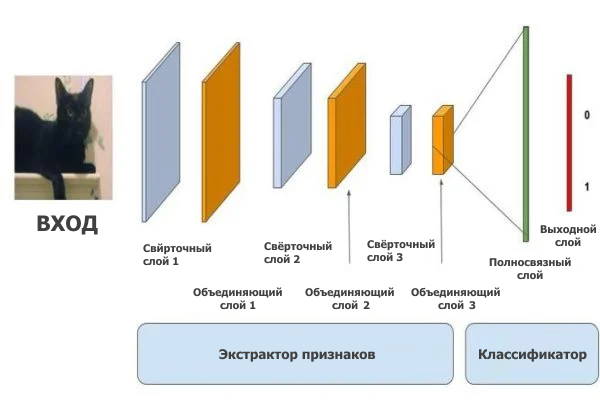
В DNN задачи классификации изображений сначала выполняются уровнями CNN, которые изучают особенности. Затем полносвязные слои объединяют эти функции и выводят классификационную оценку (вероятность того, что входное изображение — это кошка). Конечно, требуется гораздо больше вычислений, прежде чем изображение будет успешно классифицировано.
Начальные уровни в CNN (как показано в приведенной выше визуализации) изучают низкоуровневые функции, такие как вертикальные, горизонтальные и диагональные s (локальные шаблоны). По мере того, как вы углубляетесь в сеть, функции становятся более абстрактными (глобальные закономерности).
Сравнение дискриминационных моделей
Машина опорных векторов (SVM)
- SVM можно использовать как для классификации, так и для регрессии. Это контролируемый алгоритм обучения.
- SVM работает лучше, даже если обучающие данные ограничены, а количество функций больше.
- Она использует приёмы ядра, такие как Polynomial, RBF и Sigmoid, для решения сложных нелинейных задач. Вы можете не только определять собственные ядра,но также добавьте немного, чтобы получить более сложную границу принятия решения.
- Для большей точности используйте потерю шарнира (хотя и с некоторыми оговорками).
- SVM поддерживает только двоичную классификацию. Для мультиклассовой классификации вам необходимо иметь несколько моделей SVM.
- Такие гиперпараметры, как настройка мягких полей, помогают достичь достаточной точности.
- SVM эффективен по памяти, потому что здесь максимальный запас определяется опорными векторами, то есть только подмножеством точек данных.
- Поскольку это не вероятностная модель, она не выводит вероятность для прогноза или для оценок вероятности.
- Вы тренируетесь на ЦП, который можно распараллелить между ядрами. Очевидно, что для больших наборов данных требуется больше времени на обучение. Выпуклая целевая функция означает, что нет локальных оптимумов, и множитель Лагранжа вступает в игру вместо градиентного спуска (используется в DNN).
Случайный лес (Random Forest)
- Случайный лес может решать задачи как классификации, так и регрессии. Это контролируемый алгоритм обучения.
- В отличие от SVM, он может выполнять мультиклассовую классификацию.
- Кроме того, дайте оценку вероятности прогноза.
- Им следует отдавать предпочтение при увеличении набора данных. Хорошо обобщайте и не переоснащайте при объединении нескольких слабых лесов.
- Обучение идет медленнее, если количество лесов велико. Однако, если размер обучающих данных велик, мы обнаруживаем, что они обучаются быстрее, чем SVM.
- Он также поддерживает неявный выбор функций и интуитивно сообщает вам, какие функции важны.
Глубокие машинные сети (DNN)
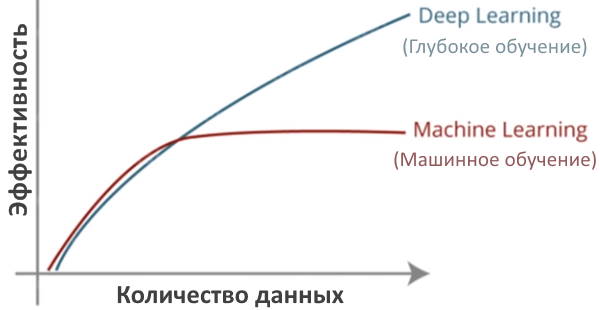
- Как и две другие модели, глубокие нейронные сети (DNN) также решают проблемы классификации и регрессии.
- Используйте метки при применении DNN к обучению с учителем (например, классификация изображений). Никаких меток не требуется, кроме как для неконтролируемого обучения (например, генерации изображений).
- DNN работают хорошо, особенно когда у вас много данных.
- В отличие от SVM, целевая функция DNN — невыпуклый, и более одного локальный оптимум может существовать. Градиентный спуск используется для оптимизации ошибки обучения.
- Они очень требовательны к вычислениям: чем выше глубина сети, тем выше требования к вычислениям. Вам нужно будет тренироваться на Графические процессоры (графические процессоры).
- Этот метод лучше всего работает при попытке извлечь значимые функции из необработанных данных. Вам не нужно полагаться на созданные вручную функции, такие как локальные двоичные шаблоны или гистограмма градиентов.
- Вам нужно действительно настроить гиперпараметры нейронной сети, чтобы достичь наилучших результатов. Они хорошо обобщают, но при распределении обученных данных.
- Используется в миллионах приложений, тем более известные из них компьютерное зрение, обработка/понимание естественного языка, медицинская визуализация, обработка речи и временные ряды.
Таким образом, не существует одного алгоритма чуда, который набирает очки по всем пунктам. Какой алгоритм будет работать, зависит от набора данных, типа проблемы, вычислительной мощности и точности, которую вы ожидаете достичь.
Что такое «генеративное» моделирование? ↑
Генеративное моделирование определяет способ создания набора данных. Он пытается понять распределение точек данных, обеспечивая модель того, как данные фактически генерируются в терминах вероятностной модели. (например, машины опорных векторов или алгоритм персептрона дает разделяющую границу решения, но не модель генерации точек синтетических данных). Цель состоит в том, чтобы сгенерировать новые образцы из того, что уже было распределено в обучающих данных.
Предположим, у вас есть набор данных об автономном вождении с настройками городской сцены. Теперь вы хотите сгенерировать из него изображения, которые семантически и пространственно похожи. Это прекрасный пример задачи генеративного моделирования. Для этого Генеративная модель должна понимать основную структуру данных и изучать реалистичное обобщенное представление набора данных, например, небо голубое, здания обычно высокие, а пешеходы ходят по тротуарам.

Изображение выше является примером генерации выборки с использованием генеративного моделирования. Цель состоит в том, чтобы ввести обучающие выборки с распределением вероятностей P_{data} и изучить такое распределение, которое: Когда вы выбираете из P_{model} распределения, оно генерирует реалистичные наблюдения, которые представляют истинное распределение.
Чтобы сгенерировать такие обучающие выборки, нужен набор данных для обучения, который состоит из немаркированных точек данных. Каждая точка данных имеет свои особенности, такие как отдельные значения пикселей (область изображения) и набор словаря (область текста). Весь этот процесс генерации является стохастическим и влияет на отдельные выборки, генерируемые моделью.
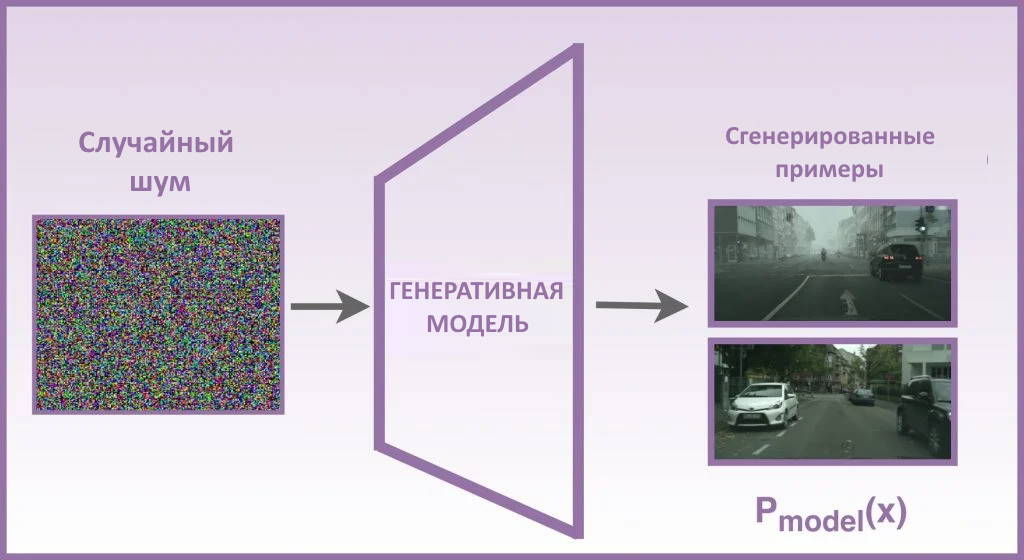
Генеративные модели, которые вы уже знаете, пытаются изучить вероятностное распределение обучающих данных. Это помогает им более реалистично представлять данные. На приведенном выше рисунке генеративная модель учится генерировать изображения городской сцены, принимая случайный шум в качестве матрицы или вектора. Его задача — генерировать реалистичные образцы X, с распределением вероятностей, аналогичным P_{data} (исходные данные из обучающей выборки). Шум добавляет модели случайности и обеспечивает разнообразие сгенерированных изображений.
Генеративное моделирование учится приближать вероятность p(x), которая является вероятностью наблюдения x в обучающем наборе данных.
Типы генеративных моделей
Вот некоторые из популярных:
- Наивная байесовская.
- Скрытые марковские модели.
- Автоэнкодер.
- Машины Больцмана.
- Вариационный автоэнкодер.
- Генеративные состязательные сети.
Давайте теперь разберемся с двумя из этих моделей: автоэнкодером и вариационным автоэнкодером. В этом разделе рассказывается об обучении без учителя (без ярлыков).
Автоэнкодер
Эта нейронная сеть в основном используется для неконтролируемого обучения сжатию данных. Цель автоэнкодера — изучить обобщенное скрытое представление (кодировку) набора данных, как и PCA. Он также получил широкое распространение для решения задач самообучения. Сеть Autoencoder разделена на два блока:
- Кодер сжимает входные данные большой размерности в режим низкой размерности, также известный как представление скрытого пространства, сохраняя всю необходимую информацию.
- Декодер работает наоборот, распаковывая низкоразмерное представление в исходный многомерный вход.
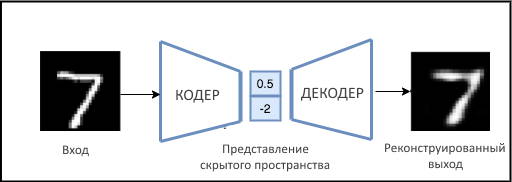
В традиционном автоэнкодере, как показано на рисунке выше:
- Используйте функцию активации, чтобы попытаться воссоздать исходное изображение после некоторого обобщенного нелинейного сжатия.
- Минимизируйте потери между входным изображением и восстановленным (предсказанным) выходным изображением, используя евклидово расстояние в качестве функции потерь.
- Выполняйте этот процесс итеративно, пока не достигнете точки, в которой потери будут минимальными, а восстановленный выход будет таким же, как входной.
Таким образом, обучается сеть подбором наилучших весов для кодировщика и декодера.
Узнайте больше об автоэнкодерах в .
Приложения автоэнкодера включают:
- шумоподавление изображений;
- уменьшение размерности;
- кластеризацию;
- рекомендательные системы;
- отрисовка изображения.
Они также могут генерировать данные; ванильный автоэнкодер не может этого сделать из-за некоторых оговорок, обсуждаемых в следующем разделе.
Архитектура глубинного кодировщика-декодера под названием SegNet была разработана специально для мультиклассовой пиксельной сегментации в наборе данных сцены городской дороги.Группа компьютерного зрения Кембриджского университета опубликовала свою работу. !
Важно отметить, что автоэнкодер не является чисто генеративной моделью. Его скрытое пространство не моделируется для генерации новых точек данных с учетом случайного вектора нормали. Следовательно, чтобы сделать их генеративными, перейдите на вариационные автоэнкодеры.
Существует множество вариантов, таких как шумоподавление, наложение и т. д. Вместо того, чтобы подробно останавливаться на этих вариантах, давайте попробуем понять, что же такое вариационный автокодер.
Несколько примечательных скрытых вариативные дискриминативных моделей
Вариационный автоэнкодер
Вариационный автоэнкодер (VAE) — это генеративная модель, которая применяет априор к скрытым векторам, так что все они лежат на гауссовой плоскости или имеют гауссов профиль (предшествующий распределению представлений). Вместо того, чтобы наносить изображение на точку в пространстве, кодировщик VAE отображает изображение на все распределение (многомерное нормальное или гауссово распределение). Затем он произвольно выбирает точку из этого распределения для восстановления изображения. Это помогает ему узнать, как распределяются данные.
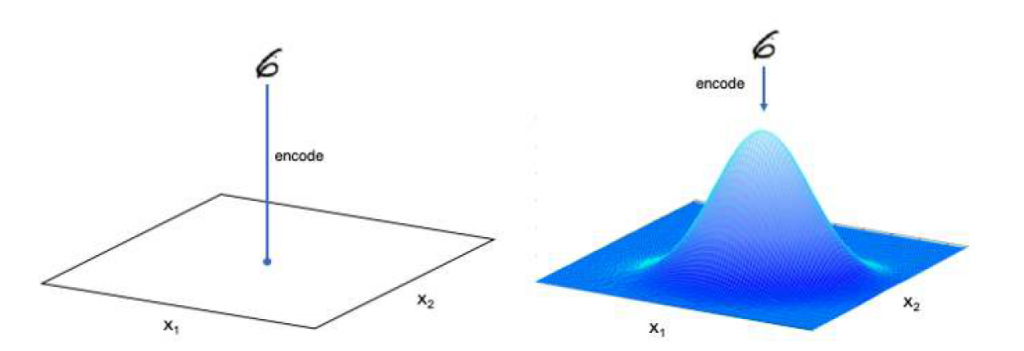
На рисунке выше цифра 6 кодируется двумя способами:
- Слева цифра 6 соответствует одной точке (традиционный автокодировщик). Рассмотрим изображение, представленное столбцом чисел, где размер столбца равен измерению скрытого пространства.
- Справа цифра 6 отображается в распределение Гаусса,поскольку вы явно узнали о распределении.
Вы можете спросить, почему традиционные автоэнкодеры не генерируют новые образцы?
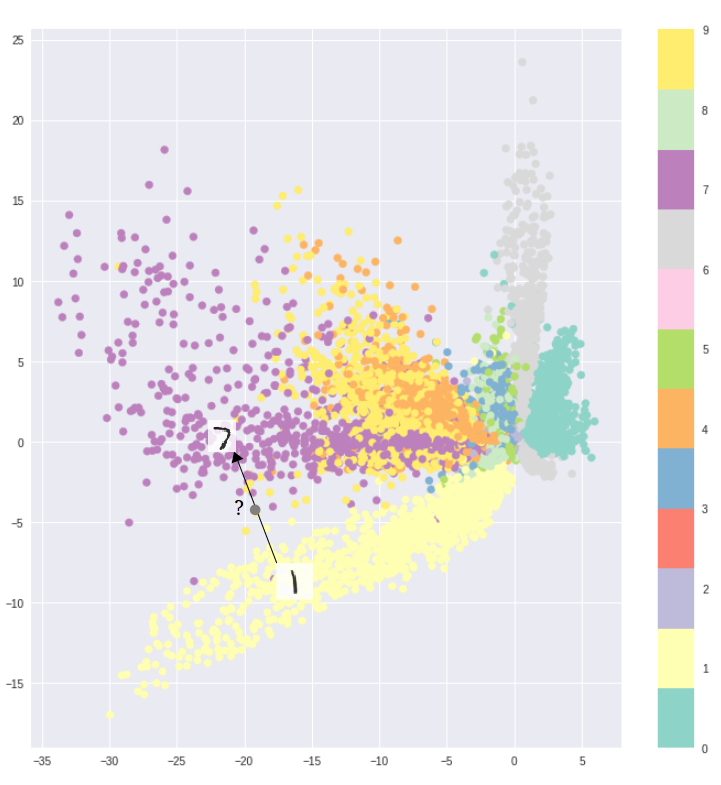
Это потому что:
- Скрытое пространство в автоэнкодерах было нерегулярным и непостоянным. Было почти невозможно узнать, какую случайную точку выбрать и декодировать из скрытого пространства для создания реалистичного изображения, поскольку в кластерах было много пробелов. Если вы выбрали точку из разрыва и передали ее декодеру,он может дать произвольный вывод, не похожий ни на один класс.
- Кроме того, распределение точек из скрытого пространства не определено должным образом, поскольку каждое изображение сопоставляется непосредственно с одной точкой. Принимая во внимание, что каждое изображение в VAE отображается на многомерное гауссово или нормальное распределение,неотъемлемое свойство которого — делать скрытые векторы непрерывными.
Введите изображение в кодировщик VAE. Он кодирует его в два отдельных вектора: среднее значение и логарифм дисперсии, соответствующие переменным скрытого пространства. Если вы возьмете случайную выборку из распределения и затем передадите ее декодеру, он восстановит изображение.
Обучив такую модель:
- Вы гарантируете, что представление скрытого пространства непрерывно.
- Изучите пул (100 пулов в случае VAE, который тренировался на 100 классах), чтобы они находились в четко определенном регионе.
В отличие от автоэнкодера, VAE не только гарантирует, что две близкие точки в скрытом пространстве дают одинаковые выходные данные,но также и то, что точка, выбранная отсюда, дает значимый результат.

Что делает вариационный автоэнкодер генеративной моделью? После обучения модели во время тестирования вы в основном избавляетесь от кодировщика и выбираете точку из нормального распределения. При прохождении через декодер генерируются разнообразные реалистичные изображения.
Вы все еще можете задаться вопросом, что мы оптимизируем в VAE? Хорошо, в отличие от традиционных автоэнкодеров, VAE оптимизирует потерю реконструкции (евклидову) плюс скрытую потерю (KL-дивергенцию). KL-дивергенция измеряет расхождение между парой распределений вероятностей. Скрытая потеря заставляет скрытое представление быть непрерывным и ограничивает пулы, полученные сетью, в одном регионе. Это гарантирует, что распределение, изученное вашей моделью, четко определено и похоже на нормальное распределение.
Вариационный автоэнкодер (VAE) также использовался в статье по обучению с подкреплением (RL) под названием «». Авторы запускают агент RL для сжатого представления VAE,вместо всего пространства ввода. Награды RL немногочисленны и требуют много времени для тренировки, поэтому VAE.
Чтобы подробнее узнать о вариационных автоэнкодерах, прочтите .
Генеративная состязательная сеть
- Хотя модель VAE использует как генеративную модель, так и модель вывода и изучает базовое распределение данных неконтролируемым образом, генерируемые ею изображения размыты. Генеративная состязательная сеть (GAN) дает четкие и лучше воспринимаемые изображения.
- В VAE оптимизирована нижняя вариационная оценка. В GAN такого предположения не существует. Фактически, GAN не имеют дело с какой-либо явной оценкой плотности вероятности.
Неспособность VAE генерировать четкие изображения означает, что модель не может узнать истинное апостериорное распределение, то есть P(x|z), где x — сгенерированная выборка, а z — скрытое пространственное представление должно быть близко к нормальному распределению.
В следующем посте мы подробно рассмотрим генеративную состязательную сеть и дадим вам интуитивное понимание архитектуры GAN, функции состязательных потерь и ее стратегии обучения. Вы также кодируете ванильный GAN для создания модных изображений в PyTorch и TensorFlow. Прочтите это!
Сравнение дискриминативного и генеративного моделирования. ↑
- Для классификации можно использовать как генеративный (G), так и дискриминативный (D).
- G-модели работают с обоими контролируемое и неконтролируемое обучение. Но модели D используются только для задач обучения с учителем.
- Цель модели D — оценить условную вероятность P(Y|X). Напротив, модель G учится приближать P(X) и P(X|Y) в неконтролируемой настройке, затем выводит P(Y|X) в контролируемой настройке.
- Модели D изучают линейную и нелинейную границу решения, используя точки данных и их соответствующие ярлыки, без знания того, как были созданы данные. Обучаясь моделировать распределение вероятностей данных, G-модели достигают понимать основные характеристики данных.
- Известно, что в контролируемых условиях D-модели превосходят G-модели. Особенно, когда G-модели плохо подходят для данных.
- G-модели могут предоставить богатое понимание данных, когда у вас нет ярлыков (меток).
Заключение ↑
Поздравляю, вы так далеко зашли. Это похвально! Вот краткое изложение.
Теперь у вас есть всестороннее понимание теории, а также работы как дискриминационного, так и генеративного моделирования, которые являются двумя выдающимися моделями машинного обучения. Обсуждались даже известные модели скрытых переменных для каждого из них. Сравнительный анализ двух моделей, должно быть, помог вам лучше понять их сильные и слабые стороны.
Попутно мы предоставили подробную информацию о ресурсах и ссылках для всестороннего обучения.

![]() Генеративная и дискриминативная модели, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Генеративная и дискриминативная модели, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Респект и уважуха
