
В этом посте расскажу, как выбрать правильную модель с помощью Modelplace.AI. Выбор правильной модели ускорит ваше приложение, поможет масштабировать его до миллионов запросов и сэкономит кучу денег на облачных вычислениях.
Прежде чем перейти к техническим деталям, посмотрим на проблемы n00b (новичка).
Выбор модели для n00bs
Допустим, вы программист, который не слишкои глубоко знаком с искусственным интеллектом, но хотите использовать детектор людей для приложения камеры. Вы не являетесь экспертом в области ИИ, но немного погуглив, чтобы узнать о многочисленных вариантах, которые у вас есть.
Самым популярным среди них, вероятно, является YOLO, что означает You Only Look Once. Название иронично, потому как не все верят в любовь с первого взгляда!
Вы посмотрите YOLO v1, v2, v3, v4, v5, v6 — ок, мы немного увлеклись. Пока нет v6, но есть так много вариантов! Какой выбрать?
Сбитый с толку, вы рискуете и наобум останавливаетесь на YOLO v4.
Вы тратите свою кровь, пот и слезы в течение следующих 4 часов, проверяя репозиторий GitHub, компилируя с необходимыми предпосылками, загружая модель и заставляя все работать на Raspberry Pi, только чтобы обнаружить, что модель работает медленно.
Вы пропустили крошечную версию YOLO!
Итак, вы делаете это снова и снова для Tiny YOLO v4. Отлично работает и ты счастлив.
Ваше счастье испаряется, когда старший программист AI в вашей команде спрашивает вас, почему вы выбрали Tiny YOLO v4 вместо Tiny YOLO v3.
У тебя нет ответа.
Вы предположили, что Tiny YOLO v4 будет лучше, чем Tiny YOLO v3, потому что вы знаете, что v4 старше v3.
Позже вы откроете для себя Modelplace.AI, который поможет вам решить эту проблему за секунды, но сейчас события могут пойти не так.
Вы демонстрируете свое приложение своему клиенту, и его не устраивает точность. Они готовы добавить приложению больше вычислительной мощности.
Хорошо, вы предлагаете YOLO v4.
Клиент, в Google, как рыба в воде, спрашивает про NAS-FPN?
Вы никогда об этом не слышали. И это стыдно.
Чтобы добавить оскорбления к травме, они спрашивают вас о CenterNet. Опять же, вы понятия не имеете.
Чтобы сохранить лицо, вы говорите клиенту, что проведете свое исследование и передадите его им. Теперь вы сталкиваетесь с мрачной перспективой установки этих моделей, обнаруживая точность каждой модели, понимание того, насколько быстро каждая модель, и проверка объема используемой памяти.
AI должен был доставить удовольствие!
В момент отчаяния вы бежите к одному волшебнику Uber AI, который, кажется, знает все. Независимо от того, чем вы занимаетесь, всегда найдется один такой человек.
Она расскажет вам об инструменте Benchmarking на Modelplace.AI, который навсегда изменит вашу жизнь.
Теперь, немного поговорим о технических моментах.
Что такое Modelplace.AI?
Modelplace.AI — это большая коллекция моделей искусственного интеллекта, которые вы можете опробовать на своих собственных изображениях и видео перед загрузкой моделей или установкой любого кода. Помимо качественной оценки моделей, вы также можете количественно сравнить модели, доступные для одной и той же задачи.После того, как вам понравится модель, у вас есть несколько вариантов использования ее в своем приложении.
- Веб-API — вы можете использовать любую модель или их коллекцию, вызвав веб-API.
- Open source models Python — если вы предпочитаете загрузить модель и запустить ее локально, многие модели доступны в виде загружаемого пакета Python, которое можно установить с помощью pip.
- Зависимость от устройства — на веб-сайте также есть много моделей, которые работают непосредственно с . Вы можете приобрести OAK в.
Modelplace.AI также является торговой площадкой, где разработчики моделей искусственного интеллекта могут монетизировать свои модели. Эта функция в настоящее время находится в стадии бета-тестирования, и вы можете узнать больше, отправив письмо по адресу . Видео ниже — это краткое введение в Modelplace.AI.
Тестирование на Modelplace.AI
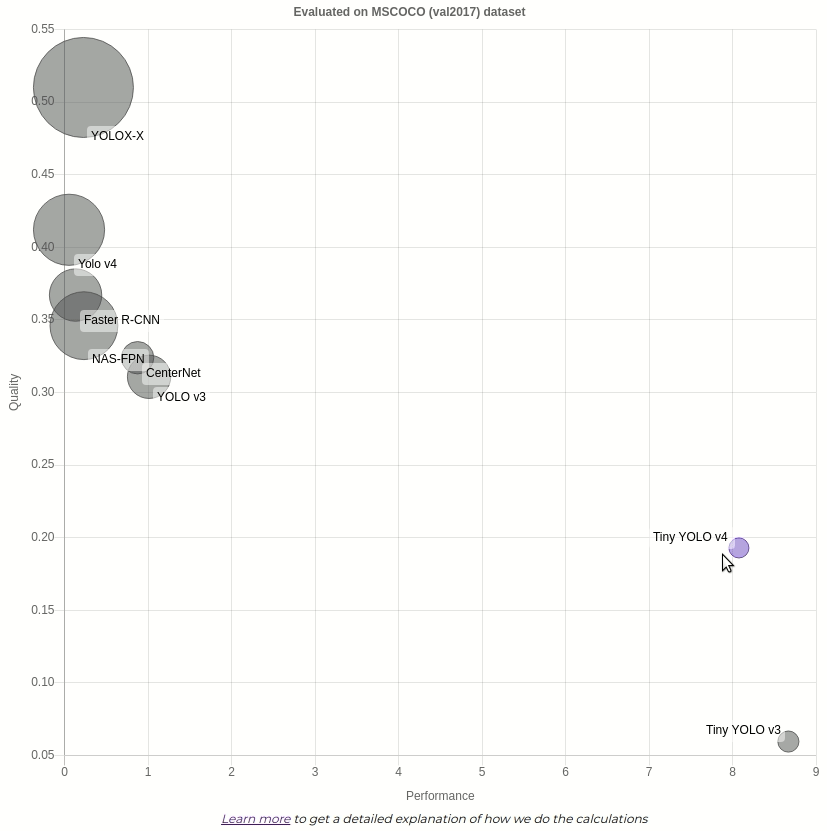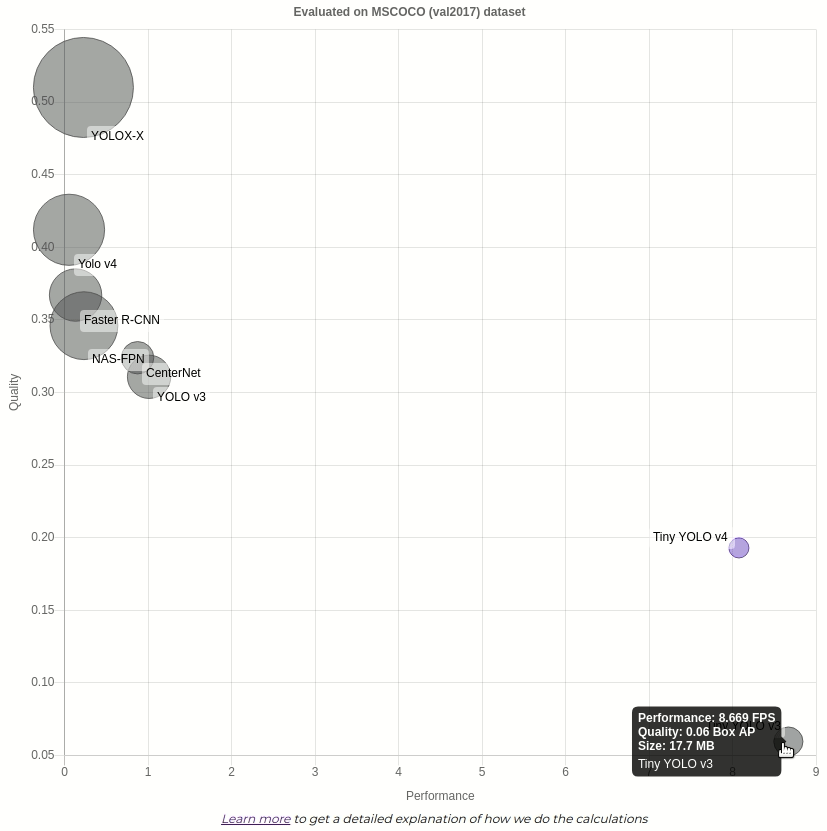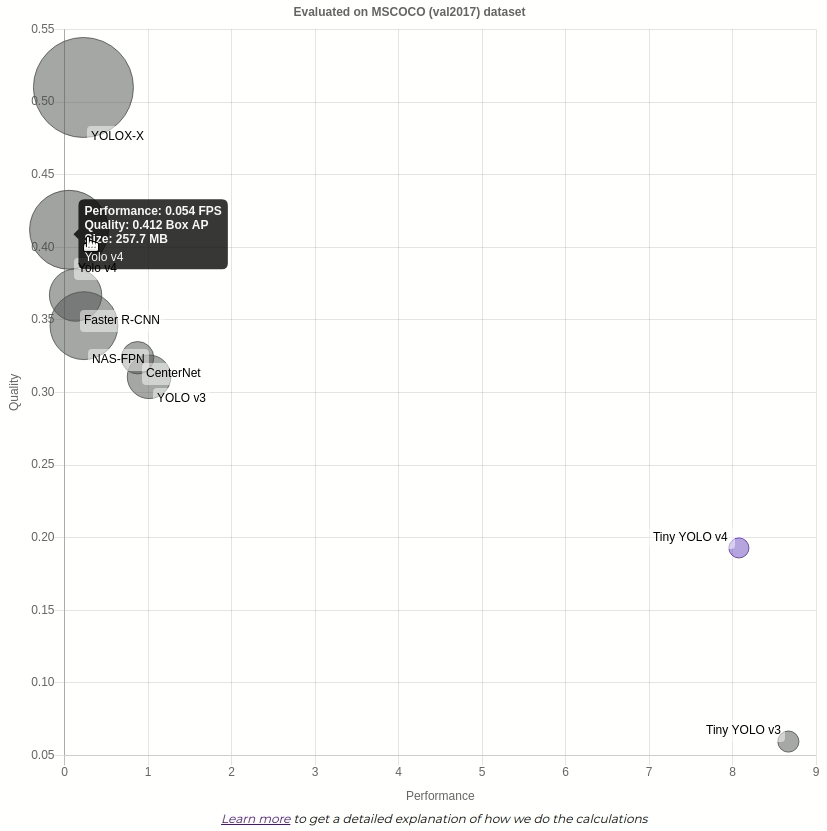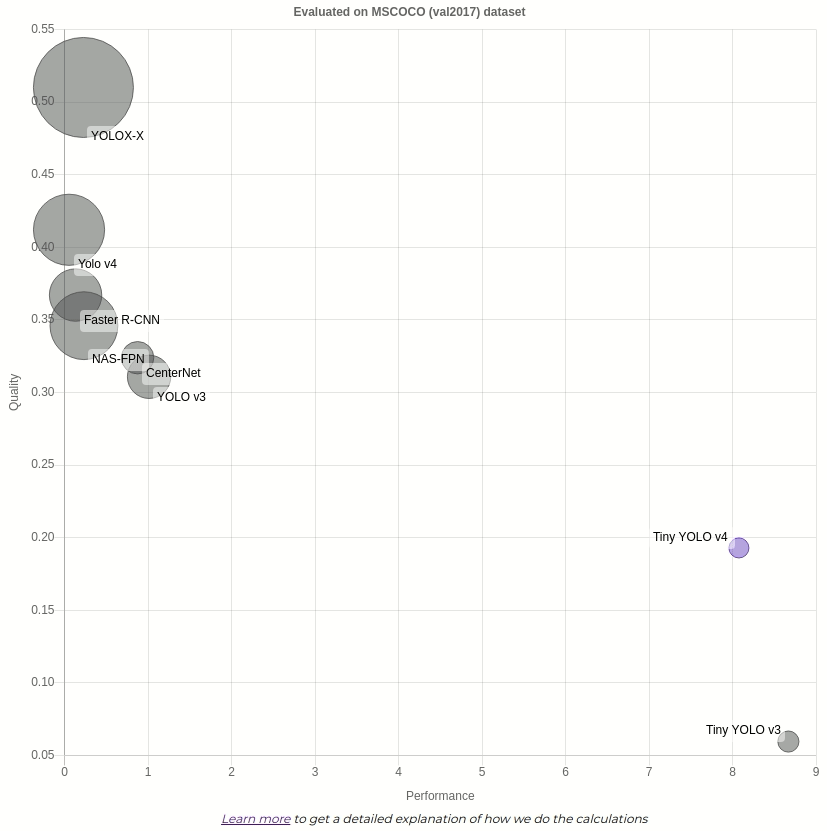
Сравнение двух моделей для конкретной задачи не так просто, как может показаться вначале. Например, одна модель может быть очень точной, но может быть очень затратной в вычислительном отношении. Вот почему мы сравниваем модели по трем различным показателям и визуализируем их на пузырьковой диаграмме на Modelplace.AI.
- Производительность: мера скорости вывода. Показана длинная ось X.
- Качество: мера точности модели. Показано по оси Y.
- Размер модели: мера размера модели во время вывода. Показано с использованием размера круга.
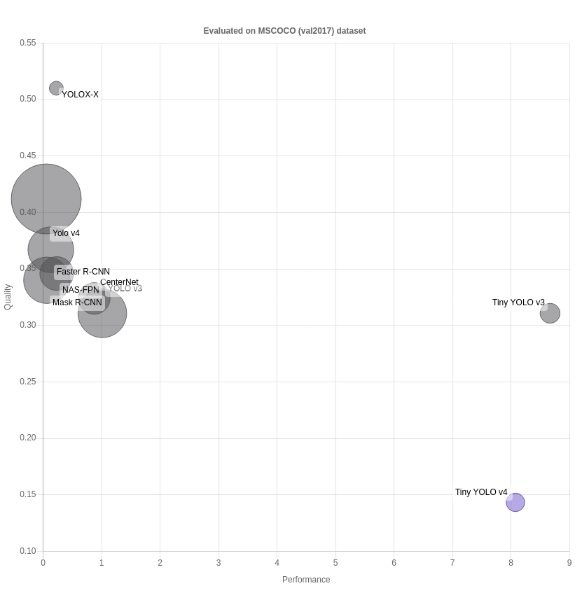
Каждая диаграмма сгруппирована по типу задачи и набору данных, на котором были получены значения. Например, мы сравниваем модели обнаружения объектов на .
Как читать тест
Раздел Benchmark расположен внизу страниц моделей.
Для примера посмотрим на .
Вы можете видеть, что пузырьковая диаграмма представляет все модели с тем же типом задачи (обнаружение) и тем же набором данных проверки , что и модель, на которой вы работаете (Tiny YOLO v4). Набор данных, используемый для оценки моделей, показан вверху диаграммы. Модель, на которую вы в данный момент смотрите, выделена фиолетовым кружком.
Чтобы увидеть конкретные значения, вы можете навести курсор на кружок.
показывает лучшее качество, в то время как намного быстрее, чем другие. Она занимает небольшой объем памяти, но если вам нужна более точная модель без резкого снижения скорости — может быть лучшим вариантом.
Наборы данных
По возможности мы измеряем модели общего назначения на общедоступных наборах данных, таких как или . Однако для некоторых моделей (например, для модели обнаружения листьев) мы не можем измерить показатели качества, поскольку нет больших общедоступных наборов данных для измерения их качества. Поэтому мы используем значение, предоставленное авторами.Чтобы он оставался стандартным для всех моделей, мы следуем двум правилам:
- Если модель универсальная, она измеряется на общедоступном наборе данных.
- Если модель является конкретной, измеряются только показатели производительности, а значение качества берется из исходной публикации. Для этих моделей мы используем внутренний набор данных, и если он отображается на пузырьковой диаграмме.
1. Обнаружение объектов — .
Исключения:
Все описанные ниже подмножества были получены с использованием . Путем передачи аргумента catIds (индексы категорий, которые должны быть извлечены из ) функции , были извлечены аннотации для конкретных классов.
- (val2017 подмножество только людей) — для проверки моделей обнаружения людей/пешеходов:,,;
- (подмножество val2017 только для автомобилей ) набор данных — для проверки моделей обнаружения транспортных средств:;
- (val2017 человек, автомобиль и только велосипед) набор данных — для проверки моделей обнаружения PVB (человек, автомобиль, велосипед):.
2. Обнаружение ориентиров: — для проверки моделей лицевых ориентиров: , , .
3. Оценка позы: набор данных (val2017 person keypoints subset) — для проверки моделей оценки позы.
4. Классификация: набор данных — для проверки моделей классификации.
Исключения:
- из . Эта модель обучена на конкретных данных, поэтому ее нельзя измерить на универсальном наборе данных.
6. Обнаружение текста: — для проверки моделей обнаружения текста.
7. Распознавание эмоций: — для проверки моделей распознавания эмоций.
Качество
Мы используем определенные метрики для измерения качества в зависимости от типа задачи. В этом разделе представлен обзор показателей, используемых для каждого типа.
1. Обнаружение: — mAP с несколькими порогами пересечения по объединению Intersection over Union (IoU), Коэффициент Жаккараએ. В качестве окончательной метрики мы усредняем MAP по порогам IoU (от 0,5 до 0,95 с шагом 0,05)..
2. Оценка позы: — с .
Исключения:
Нормализованная средняя абсолютная ошибка (NMAE) для регрессии ориентиров руки .
3. Обнаружение наземных ориентиров — Нормированная средняя ошибка, вычисляемая как расстояние между точным и предполагаемым ориентиром, нормированное на расстояние.Он рассчитывается по-разному в зависимости от модели:
- Для и, расстояние между глаза мы используем как нормализацию;
- для, нормализация выполняется с использованием диаметра от белого к белому (WWD). WWD рассчитывается как трехмерное расстояние между левым и правым ориентирами на контуре радужной оболочки, взятое из наземной истины.
4. Классификация — с коэффициентами ошибок «топ-1» и «топ-5».
5. Сегментация — мы используем точность пикселей.
6. Обнаружение текста — и их модифицированные версии .
7. Отслеживание — . MOTA учитывает все ошибки конфигурации объекта, сделанные трекером, ложные срабатывания, промахи, несовпадения по всем кадрам.
Производительность
Метрика для измерения производительности — FPS и рассчитывается по формуле:
FPS = 1 / (Mean Preprocess Time + Mean Forward Time + Mean Postprocess Time)
- Среднее время предварительной обработки — среднее время выполнения функции предварительной обработки на пакете;
- Среднее время пересылки — среднее время выполнения функции пересылки на пакете;
- Среднее время постобработки — среднее время выполнения функции постобработки на пакете.
Все модели оцениваются с размером партии 1.
Размер модели
Для размера модели мы используем размер модели на диске, который является разумным показателем размера модели в памяти.
Вычислительные машины
Все модели из одной области выводятся на облачных машинах с одинаковыми характеристиками для сравнения их на фарватере. Они оцениваются на виртуальной машине Google Cloud n1-standard-1.Эта машина имеет 1 виртуальный ЦП и 3,75 ГБ ОЗУ.
Примечание: Мы оцениваем все модели на vCPU, поэтому результаты ожидаемо низкие. Учтите, что при более мощном процессоре производительность будет выше.
Также для сравнения и лучшего понимания результатов производительности, например, мы оценили CenterNet на не облачной машине со следующими характеристиками:
- Intel Core i7-8700
- 12 CPU
- 64 GB system memory
- batch size = 1
| Метрика | Не облачная машина | Машина в облаке |
| FPS | 4.75 | 0.87 |
| Среднее время предварительной обработки(с) | 0.0004 | 0.001 |
| Среднее время постобработки(с) | 0.0005 | 0.0009 |
| Среднее время обработкт(с) | 0.2 | 1.14 |
Источник

![]() Выбор модели и сравнительный анализ с помощью Modelplace.AI, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Выбор модели и сравнительный анализ с помощью Modelplace.AI, опубликовано К ВВ, лицензия — Creative Commons Attribution-NonCommercial 4.0 International.
Респект и уважуха
