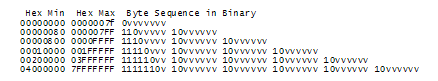Эссе о программировании — классика околокомпьютерной сатиры, которое написал Эд Пост (Ed Post) из Орегонской компании Tektronixએ. Оно было опубликовано как письмо редактору в 29-м томе 7-го выпуска журнала Datamationએ в июле 1983 года. Название статьи пародировало название сатирической книги-бестселлера Настоящие мужики не едят пироги с заварным кремом, высмеивающей стереотипы о мужественности.
Эта cтатья в своё время широко обсуждалась в новостных cкомпьютерной сети Usenetએ и была хорошо известна многим специалистам индустрии производства программного обеспечения. Статья породила множество подражаний и отсылок к предмету обсуждения.
Статья сравнивает и противопоставляет Настоящих Программистов, которые используют перфокарты и программируют на Фортране и Ассемблере, современным «пожирателям пирогов с заварным кремом», которые используют такие языки программирования как Pascal, которые поддерживают структурное программирование и накладывают определённые ограничения с целью предотвращения наиболее распространённых ошибок в логике работы программы. В статье приводился ряд подвигов Настоящих Программистов, таких как подвиг Сеймура Крэя — создателя суперкомпьютера Cray-1એ, набравшего операционную систему для компьютера CDC 7600 с консоли по памяти для того, чтобы его запустить.
Табличный процессор (речь идет о MS Excel или LibreOffice Calc) — это довольно занятный и универсальный инструмент. Мне часто приходилось (и приходится) пользоваться его широкими возможностями: автоматизированные отчеты, проверка гипотез, прототипирование алгоритмов. Например, я использовал его для решения задач , быстрой проверки алгоритмов, реализовал парсер одного прикладного протокола (по работе надо было). Мне нравится наглядность, которую можно добиться в табличном процессоре, а еще мне нравится нестандартное применение всего, чего только возможно. На Хабре уже появлялись интересные статьи на тему нестандартного применения
Excel:
В этой длинной статье я хочу поделиться своими экспериментами в с помощью формул табличного процессора. В результате этих экспериментов у меня получился «компьютер» с процессором, памятью, стеком и дисплеем, реализованный внутри LibreOffice Calc при помощи одних только формул (за исключением тактового генератора), который можно программировать на неком подобии ассемблера. Затем, в качестве примера и proof-of-concept, я написал игру «Змейка» и бегущуюползущую строку для этого компьютера.
Предисловие
Началось все с того, что я заинтересовался различными парадигмами программирования, посетил вводное занятие по в клубе робототехники; и вот в статье на википедии по я наткнулся на следующий текст:
Современные табличные процессоры представляют собой пример реактивного программирования. Ячейки таблицы могут содержать строковые значения или формулу вида «=B1+C1», значение которой будет вычислено исходя из значений соответствующих ячеек. Когда значение одной из зависимых ячеек будет изменено, значение этой ячейки будет автоматически обновлено.
Действительно, любой кто пользовался формулами в Excel знает, что изменив одну ячейку мы меняем связанные с ней ячейки — получается довольно похоже на распространение сигнала в цепи. Все эти факторы и навели меня на следующие мысли: а что если эта «цепь» будет достаточно сложной? являются ли формулы в табличном процессоре ? можно ли «запрограммировать» формулы, так чтобы получить какие-нибудь нетривиальные результаты? (например сделать тетрис) Т.к. последнее время я использую Ubuntu на работе и дома, то все эксперименты я проводил в LibreOffice Calc 4.2.7.2
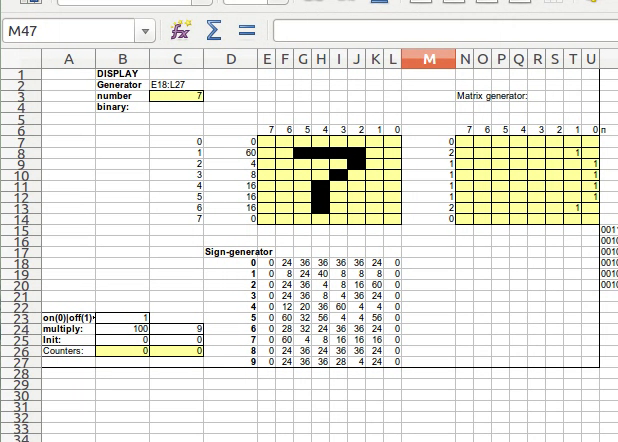
Цифровой дисплей 8×8
Начал эксперименты я с реализации дисплея. Дисплей представляет из себя набор квадратных ячеек 8х8. Здесь пригодилось условное форматирование (оно есть и в Excel и в Calc). Выделяем ячейки, заходим в Format/Conditional Formatting/Condition… и настраиваем внешний вид: черный фон, при условии, что в ячейке содержится, например, пробел. Теперь если записать в ячейку пробел, то она становится черной. Таким образом реализуются пиксели нашего дисплея. Но этим дисплеем хочется как-то управлять. Слева от него я выделил специальный столбец в который будут заноситься числа — идея такая, чтобы этим числом мы задавали битовую маску для отображения на экране. Сверху экрана я пронумеровал столбцы. Теперь в каждую ячейку дисплея мы должны написать формулу, которая даст в результате либо пробел, либо пустую строку, в зависимости от того, установлен ли нужный бит в самом левом столбце.
Здесь, по сути, происходит сдвиг вправо (деление на степень двойки и потом отброс дробной части), а затем берется 0-й бит, то есть остаток от деления на 2, и если он установлен, то возвращается пробел, иначе пустая строка.
Теперь при записи в самый левый столбец какого-то числа на дисплее отображаются пиксели. Далее мне хотелось сгенерировать битовых масок, например, для десятичных цифр и, в зависимости от цифры, заполнять столбец масок дисплея нужными числами.
Для генерации была создана еще одна конструкция 8х8, в которую руками заносятся единицы, а формула сворачивает все это в одно число:
=SUMPRODUCT(<строка ячеек с единичками и ноликами>;2^<строка с номерами позиций>)
В итоге получил такую матрицу битовых масок для цифр:
Здесь каждая строка соответствует десятичной цифре. Возможно, не самые красивые цифры вышли, к тому же, верхний и нижний ряд не использован, ну уж как нарисовал, так нарисовал )
Далее применим функцию INDEX, если ей указать матрицу, ряд и колонку, то она возвращает значение из этой матрицы. Так что, в каждой ячейке битовой маски дисплея пишем формулу
единицы прибавляются потому, что INDEX считает координаты с единицы, а не с нуля.
Циклические ссылки
Что ж, дисплей готов, пишешь руками цифру — она отображается. Далее мне захотелось сделать так, чтобы цифра сама переключалась, то есть некий счетчик, который будет накапливать сумму. Здесь то и пришлось вспомнить про циклические ссылки в формулах. По-умолчанию, они выключены, заходим в опции, разрешаем циклические ссылки, я у себя настроил вот так:
Опции вычислений
Циклическая ссылка подразумевает под собой формулу в ячейке, зависящую от нее самой же, например, в ячейку A1 мы запишем формулу «=A1+1». Такая ячейка, конечно, не может быть вычислена — когда заканчивается число допустимых итераций, то Calc выдает либо #VALUE, либо ошибку 523. К сожалению, обмануть Сalc не удалось, идея была такая, чтобы сделать одну ячейку постоянно растущей до какого-то предела, например, в A1 я бы записал что-то вроде: =IF(A1<500; A1+1; 0), а в B1, например, такое: =IF(A1=500;B1+1;B1). 500 — это просто магическое число, которое должно было обеспечить задержку, то есть, пока в А1 накапливается сумма, это заняло бы какое-то время, а потом бы поменялся B1. (Ну тут надо было бы еще позаботиться о начальной инициализации ячеек.) Однако, мой план не сработал: в Calc реализованы какие-то хитрые алгоритмы кэширования и проверки (я даже немножко заглядывал в исходники, но подробно не ковырялся), что зациклить вычисление формулы не получается, какие бы хитрые зависимости не были. Кстати в Excel 2003 этот трюк, кажется, частично срабатывал, и, вообще, там похоже другая модель вычисления формул, но я все-таки решил экспериментировать в Calc. После этого я решил сделать счетчик на макросах, а на него уже навешивать все свои зависимости. Один товарищ мне, вообще, подсказал сделать на макросах только синхроимпульс (сигнал clock), а на него уже навешивать счетчики и все что нужно. Идея мне понравилась — макрос получался тривиальным: задержка и смена состояния на противоположное. Сам же счетчик состоит из 4-х ячеек:
Здесь уже предусмотрен сброс для инициализации начальных значений, путем занесения 1 в A1.
Такой счетчик подключается к дисплею из предыдущего раздела, и получается то, что видно на данном видео:
Счетчик + дисплей 8х8
Жаль, что не получилось обойтись полностью без макросов и тактовый генератор сделать на формулах не получилось. Кроме этого, возникла еще одна проблема: когда макрос зациклен — он блокирует основной поток, и ничего уже сделать нельзя, приходится завершать работу Calc. Но у меня уже зрели мысли об интерактивности, хотелось как-то управлять своей будущей схемой, например, сбрасывать все в ноль, или менять какие-то режимы во время работы.
Неблокирующий таймер
К моему счастью, оказалось, что в Calc можно сделать так, чтобы основной поток макроса не блокировался. Здесь я немного слукавил и просто «нагуглил» готовое решение, приспособив его под себя. Это решение требовало Bean Shell для LibreOffice. Пакет называется libreoffice-script-provider-bsh. Код состоит из 2х частей: одна на BeanShell, другая на LibreOffice Basic. Честно говоря, полностью в коде я не разобрался… каюсь (не владею Java, BeanShell, да и с объектной моделью LibreOffice не особо знаком), но кое-что все-таки подправил.
BeanShell часть
import com.sun.star.uno.Type;
import com.sun.star.uno.UnoRuntime;
import com.sun.star.lib.uno.helper.PropertySet;
import com.sun.star.lib.uno.helper.WeakBase;
import com.sun.star.task.XJobExecutor;
import com.sun.star.lang.XInitialization;
import com.sun.star.beans.PropertyValue;
import com.sun.star.beans.XPropertyChangeListener;
import com.sun.star.beans.PropertyChangeEvent;
import com.sun.star.lang.EventObject;
import com.sun.star.uno.AnyConverter;
import com.sun.star.xml.crypto.sax.XElementStackKeeper ; // defines a start and a stop routine
// This prevents an error message when executing the script a second time
xClassLoader = java.lang.ClassLoader.getSystemClassLoader();
try {
xClassLoader.loadClass("ms777Timer_01");
} catch (ClassNotFoundException e)
{
System.out.println( "class not found - compiling" );
public class ms777Timer_01 extends PropertySet implements XElementStackKeeper
{
// These are the properties of the PropertySet
public boolean bFixedRate = true;
public boolean bIsRunning = false;
public int lPeriodInMilliSec = 2000;
public int lDelayInMilliSec = 0;
public int lCurrentValue = 0;
public XJobExecutor xJob = null;
// These are some additional properties
Task xTask =null;
Timer xTimer = null;
public ms777Timer_01() {
registerProperty("bFixedRate", (short) 0);
registerProperty("bIsRunning", (short) com.sun.star.beans.PropertyAttribute.READONLY);
registerProperty("lPeriodInMilliSec", (short) 0);
registerProperty("lDelayInMilliSec", (short) 0);
registerProperty("lCurrentValue", (short) 0);
registerProperty("xJob", (short) com.sun.star.beans.PropertyAttribute.MAYBEVOID);
xTimer = new Timer();
}
//XElementStackKeeper
public void start() {
stop();
if (xJob==null) {return;}
xTask = new Task();
lCurrentValue = 1;
bIsRunning = true;
if (bFixedRate) {
xTimer.scheduleAtFixedRate( xTask, (long) lDelayInMilliSec, (long) lPeriodInMilliSec );
} else {
xTimer.schedule( xTask, (long) lDelayInMilliSec, (long) lPeriodInMilliSec );
}
}
public void stop() {
lCurrentValue = 0;
bIsRunning = false;
if (xTask!=null) { xTask.cancel();}
}
public void retrieve(com.sun.star.xml.sax.XDocumentHandler h, boolean b) { }
class Task extends TimerTask {
public void run() { // эта функция вызывается по таймеру и дергает триггер, в который мы передаем либо 0 либо 1
xJob.trigger(lCurrentValue.toString());
if (lCurrentValue == 0)
lCurrentValue = 1;
else
lCurrentValue = 0;
}
}
}
System.out.println( "ms777PropertySet generated" );
} // of if (xClass = null)
Object TA = new ms777Timer_01();
return TA;
LibreOffice Basic часть
Sub clock // эту функцию я повешал на кнопку, чтобы запускать и останавливать "тактовый генератор"
if isEmpty(oP) then // если запустили первый раз, то создаем эти неведомые объекты в которых я не разобрался
oP = GenerateTimerPropertySet()
oJob1 = createUnoListener("JOB1_", "com.sun.star.task.XJobExecutor")
oP.xJob = oJob1
oP.lPeriodInMilliSec = 150 // здесь задается задержка
endif
if state = 0 then // а здесь смена состояния, 0 - означает синхроимпульс остановлен и его надо запустить
oP.start()
state = 1
else // в противном случае означает что синхроимпульс запущен и его надо остановить
oP.stop()
state = 0
endif
End Sub
function GenerateTimerPropertySet() as Any // функция в которой достается срипт на BeanShell
oSP = ThisComponent.getScriptProvider("")
oScript = oSP.getScript("vnd.sun.star.script:timer.timer.bsh?language=BeanShell&location=document")
GenerateTimerPropertySet = oScript.invoke(Array(), Array(), Array()
end function
sub JOB1_trigger(s as String) // это триггер который вызывается по таймеру из BeanShell скрипта
SetCell(1, 2, s)
end sub
sub SetCell (x as Integer, y as Integer, val as Integer) // установить значение в ячейке с координатами X, Y
ThisComponent.sheets.getByIndex(1).getCellByPosition(x, y).Value = val
end sub
Итак, на лист я добавил компонент кнопку, назвал ее «Cтарт/Стоп» и повешал на нее функцию clock. Теперь при нажатии кнопки, ячейка меняла свое значение на 0 или 1 с заданным интервалом, и поток приложения больше не блокировался. Можно было продолжать эксперименты: вешать какие-то формулы на синхро-сигнал и всячески «извращаться».
Тут я начал думать, чего-бы такого сделать. Вот экран есть, логику, вроде как, любую можно реализовать, есть синхроимпульс. А что, если сделать бегущую строку, или, вообще, «Тетрис»? Это ж у меня получается, практически, цифровая схемотехника! Тут вспомнилась занятная игра по цифровой схемотехнике: , там одно из заданий было сделать сумматор и память с адресным доступом. Если там это возможно было сделать, значит и тут можно — подумал я. А раз есть экран, значит надо сделать игру. А там где одна игра, там и другая, значит надо сделать возможность делать разные игры… Примерно, как-то так, в мою голову пришла идея сделать процессор, чтобы можно было в ячейки заносить команды, а он бы их считывал, менял свое состояние и выводил на экран то, что мне нужно.
Размышлений было много, проб и ошибок тоже, были мысли сделать эмулятор готового процессора, например Z80 и другие не менее безумные мысли… В конце концов я решил попробовать сделать память, стек, регистры и парочку команд типа mov, jmp, математические же команды типа add, mul, sub и т.д. было решено не делать, ибо формулы Calc уже и так это умеют и даже больше, так что я решил использовать в своем «ассемблере» напрямую формулы табличного процессора.
Память
Память это такой черный ящик, которому на вход можно подать адрес, значение, и сигнал на запись. Если сигнал на запись выставлен, то значение сохраняется по данному адресу внутрь черного ящика, если сигнал не выставлен, то на выходе черного ящика появляется значение, сохраненное ранее по данному адресу. Еще нужен отдельный вход для очистки содержимого. Вот такое определение памяти я себе придумал для реализации. Итак, у нас есть ячейки, для хранения значения, и есть «интерфейсы»: входы и выход:
m_address - адрес
m_value_in - значение для записи
m_set - сигнал "записать"
m_value_out - значение при чтении, выходной сигнал
m_clear - сигнал на очистку
Чтобы было удобнее, самое время воспользоваться возможностью именовать ячейки в Calc. Становимся на ячейку, Insert/Names/Define… Это позволит дать понятные имена ячейкам и использовать в формулах уже эти имена. Итак, я дал имена 5ти ячейкам, что описаны выше. Дальше выделил квадратную область 10х10 — это те ячейки которые будут хранить значения. По краям пронумеровал строки и столбцы — чтобы использовать номера столбцов и строк в формулах. Теперь каждая ячейка, хранящая значение, заполняется одинаковой формулой:
=IF( m_clear = 1; 0; IF(AND(m_address = ([ячейка_с_номером_ряда] * 10) + [ячека_с_номером_колонки]; m_set = 1); m_value; [текущая_ячейка])),
логика тут простая: сначала проверяется сигнал очистки, если он выставлен, то обнуляем ячейку, в противном случае смотрим совпадает ли адрес (ячейки адресуются числом 0..99, столбцы и строки пронумерованы от 0 до 9) и выставлен ли сигнал на запись, если да, то берем значение на запись, если нет, то сохраняем свое текущее значение. Протягиваем формулу по всем ячейкам памяти, и теперь мы можем заносить в память любые значения. В ячейку m_value_out заносим следующую формулу: =INDIRECT(ADDRESS(ROW([первая_ячейка_памяти]) + m_address / 10; COLUMN([первая_ячейка_памяти]) + MOD(m_address; 10); 1;0);0), функция INDIRECT возвращает значение по ссылке заданной в строке, а функция ADDRESS как раз возвращает строку со ссылкой, аргументы это ряд и колонка листа, и тип ссылки. Я оформил это таким образом:
Тут желтым цветом обозначены входные сигналы, в которые можно писать значения, в них формул нет, а красным выделено то, что трогать нельзя, зеленое поле — это выходное значение, оно содержит формулу и на него можно ссылаться в других формулах.
Cтек
Память готова, теперь я вздумал реализовать стек. Стек — это такой черный ящик, которому на вход можно подать значение, сигнал на запись и сигнал на чтение. Если подан сигнал на запись, то стек сохраняет значение у себя внутри, рядом с ранее сохраненными, если подан сигнал на чтение, то стек на выходе выдает крайнее сохраненное у себя значение, и удаляет его у себя внутри так, что крайним значением становится предыдущее сохраненное. Здесь уже пришлось повозиться, потому что, в отличие от памяти, стек имеет внутреннюю структуру: указатель на вершину стека, который должен правильно менять свое состояние. Итак, для интерфейсной части я завел следующие ячейки:
s_address - адрес откуда начинаются ячейки для хранения, например "Z2"
s_pushvalue - значение, которое надо записать в стек
s_push - сигнал на запись
s_pop - сигнал на извлечение из стека
s_popvalue - выходной сигнал - значение, извлеченное из стека
s_reset - сигнал сброса
Для внутренних структур я завел следующие ячейки:
sp_address - адрес ячейки куда показывает указатель стека
sp_row - ряд sp_address
sp_column - колонка sp_address
sp - указатель стека, число, например 20 означает что 20 значений уже сохранено в стек и следующее будет 21-е
oldsp - старый указатель стека, нужен для корректной работы sp
Ну и осталась длинная строка ячеек, в которых будут храниться значения. Начнем с формулы для извлечения значения s_popvalue =IF(s_pop=1; INDIRECT(sp_address; 0); s_popvalue), тут все просто, если сигнал для извлечения подан, то просто берем значение ячейки по адресу, куда показывает указатель стека, иначе сохраняем старое значение. Формулы для внутренних структур:
ячейка
формула
sp_address
=ADDRESS(sp_row; sp_column; 1;0)
sp_row
=ROW(INDIRECT(s_address))
sp_column
=COLUMN(INDIRECT(s_address)) + sp
oldsp
=IF(AND(s_push = 0; s_pop = 0); sp; oldsp)
Здесь легко заметить, что для формирования адреса, куда показывает стек, мы берем адрес начала стека и прибавляем к нему указатель стека. Старое значение указателя стека обновляется в случае когда оба сигнала: и на запись и на извлечение — нулевые. Пока все просто. Формула для sp же довольно сложна, поэтому я приведу ее с отступами, для лучшего понимания:
Указатель стека sp
=IF(s_reset = 1; // если сигнал сброса, то
0; // сбросить указатель в 0
IF(AND(sp = oldsp; c_clock = 1); // иначе проверяем равен ли стекпойнтер старому значению и взведен ли синхросигнал (то есть надо ли обновить стекпойнтер)
SUM(sp; IF(s_push = 1; // если обновление стекпойнтера требуется, значит к старому значению прибавляем некое смещение (-1, 0 или 1)
1; // прибавляем к стекпойнтеру 1, в случае если сигнал push
IF(s_pop=1; // в противном случае, если сигнал pop, то прибавляем либо 0 либо -1
IF(sp > 0; -1; 0); // -1 прибавляем в случае, когда sp > 0, иначе прибавляем 0, то есть оставляем старое значение
0))); // старое значение оставляем в случае когда ни push ни pop не взведены
sp)) // если стекпойнтер не равен старому значению, или синхросигнал невзведен то сохраняем старое значение
5 вложенных IF выглядят монстрообразно, в дальнейшем я такие длинные формулы разделял на несколько ячеек так, чтобы в каждой ячейке было не больше 2-х IF’ов.
Осталось привести формулу для ячеек, хранящих значение:
здесь в принципе можно «распарсить» без отступов, суть такова, что проверяется некоторое условие и в случае, когда это условие выполняется — в ячейку заносится s_pushvalue. Условие следующее: должен быть взведен сигнал s_push; ряд ячейки должен совпадать с рядом, куда указывает sp; колонка, куда показывает sp, должна быть на 1 больше, чем колонка нашей ячейки; ну и sp не должен равняться своему старому значению oldsp.
Картинка для наглядности, что у меня получилось:
Процессор
Ну вот, память есть, стек есть. Экран я сделал побольше чем 8х8, т.к. изначально думал про тетрис, то сделал 10х20, как на BrickGame из 90х. Первые 20 ячеек своей памяти я использовал в качестве видеопамяти, то есть подключил их к 20 строкам экрана (поэтому на картинке они темно-красного цвета), теперь я могу рисовать на экране что-то, путем занесения в память по нужному адресу нужных мне значений. Осталось реализовать главное: то, что будет пользоваться памятью, стеком, считывать команды и исполнять их.
Итак, центральный процессор у меня состоит из следующих частей:
Структуры CPU
Входы:
c_reset - сигнал сброса (обнуляет состояние процессора)
c_main - адрес начала программы, точка входа
c_clock - синхроимпульс, подается извне
pop_value - значение из стека, подключается к стеку =s_popvalue
Внутренние структуры:
command - команда на выполнение
opA - первый операнд команды
opB - второй операнд команды
cur_col - текущий ряд (куда показывает ip)
cur_row - текущая колонка
ip - instruction pointer, указатель на команду
oldip - старый ip, нужен для корректной работы ip
ax - регистр общего назначения (РОН)
bx - РОН
cx - РОН
rax - копия ax, нужна для того, чтобы корректно модифицировать значение ax
rbx - копия bx
rcx - копия cx
Выходы:
mem_addr - адрес памяти, подключено к памяти
mem_value - значение для записи в память или считанное из памяти
mem_set - сигнал для записи в память, подключен к памяти
pop_value - значение из стека, или для записи в стек, подключено к стеку
push_c - сигнал записи в стек
pop_c - сигнал чтения из стека
Вкратце, как все работает: входы подключены к тактовому генератору и сбросу (который я повесил на кнопку для удобства, чистая формальность), точка входа настраивается вручную. Выходы подключены к памяти и стеку, на них, в зависимости от команд, будут появляться нужные сигналы. Команда и операнды заполняются, в зависимости от того, куда показывает указатель инструкций ip. Регистры меняют свое значение, в зависимости от команд, и операндов. ip тоже может менять свое значение, в зависимости от команды, но по-умолчанию он просто увеличивается на 1 на каждом шаге, а начинается все с точки входа, которую указывает человек. Т.о. программа может располагаться в произвольном месте листа, главное — адрес первой ячейки указать в c_main.
Список команд поддерживаемый процессором:
mov - поместить значение в регистр, первый операнд имя регистра, второй - значение, например mov ax 666
movm - поместить значение по адресу в памяти, первый операнд - адрес в памяти, второй операнд значение
jmp - переход, один операнд - новое значение ip, второй операнд отсутствует (но в ячейке все-равно должно что-то быть! Магия Calc, которую я не разгадал...)
push - достать значение из стека и положить в регистр общего назначения, единственный операнд - название регистра (ax, bx или cx), магия со вторым оператором такая же
pop - положить значение в стек, операнд - значение
mmov - достать значение из памяти и положить в регистр, первый операнд - адрес памяти, второй операнд - название регистра
В качестве операндов и команд, в программе можно указывать формулу, главное — чтобы в ячейке в результате получилось значение, именно значения будут попадать на обработку в процессор.
Начнем с простых внутренних структур: cur_col=COLUMN(INDIRECT(ip)) и cur_row=ROW(INDIRECT(ip)) это просто текущий ряд и текущая колонка. command=IFERROR(INDIRECT(ADDRESS(ROW(INDIRECT(ip));COLUMN(INDIRECT(ip)); 1;0); 0); null) здесь уже видно различие теории и практики. Во-первых, пришлось вставить проверку на ошибки. Во-вторых, в формуле пришлось отказаться от предыдущих значений cur_col и cur_row — это приводило к каким-то хитрым циклическим зависимостям и не давало корректно работать ip, впрочем речь об ip ниже. В-третьих, здесь я применил специальное значение null (в случае ошибки), для него выделена отдельная ячейка с «-1».
Значения операндов формируются из текущей строки и колонки со смещением:
ip=IF(c_reset = 1; // проверка на сброс
c_main; // если был сброс, то возвращаемся на мейн
IF(AND(c_clock = 1;ip=oldip); // в противном случае проверяем надо ли обновлять значение (взведен клок и старое значение совпадает с текущим)
IF(command="jmp"; // если значение менять надо, то проверяем является ли ткущая команда переходом
opA; // если текущая команда jmp, тогда берем новое значение из операнда
ADDRESS(ROW(INDIRECT(ip))+1; // если текущая команда не jmp, тогда просто переходим на следующий ряд
COLUMN(INDIRECT(ip))));
ip)) // если значение обновлять не надо, то оставляем старое
Фактически, эта длинная формула у меня разнесена по нескольким ячейкам, но можно и все в одну записать.
opdip=IF(c_clock = 0; ip; oldip)
Формулы для регистров, также проверяют какая команда является текущей, но учитывается уже больше команд, поэтому уровень вложенности IF совсем нечитабельный. Здесь я приведу пример, как я разносил длинные формулы по нескольким ячейкам:
Здесь A1 и является, собственно, регистром ax, а остальные это вспомогательные ячейки.
Копия регистра rax=IF(c_reset= 1; 0; IF(AND(rax<>ax; c_clock=0); ax; rax))
Думаю тут совсем не сложно догадаться что происходит. Остальные регистры bx и cx устроены аналогичным образом.
Осталось дело за малым — выходные сигналы процессора:
Это сигналы для работы с памятью и стеком. На первый взгляд, сигналы push_c и pop_c, вроде бы, одинаковы по-сути, но формулы в них немножко разные. Могу лишь ответить, то, что они получены методом многочисленных проб и ошибок. В процессе отладки всей этой конструкции было много багов, и они еще остались, к сожалению процессор не всегда работает «как часы». По каким-то причинам, я остановился именно на таком варианте, значит «по-другому» что-то не работало. Сейчас уже не смогу точно вспомнить — что именно.
Картинка моего процессора:
Здесь видно еще debug поля — в них выводятся не значения, а формулы в виде текста.
Программирование
Итак, компьютер готов, можно приступать к написанию программы. В процессе программирования обнаружилось несколько проблем, некоторые из которых были решены, некоторые все же остались:
Иногда «компьютер» глючит и ведет себя непредсказуемо
Надо чтобы на листе было видно почти все, включая программу, иначе ячейки, которые далеко за пределом видимости не обновляют свое содержимое
«Компьютер» получился медленный, уменьшение задержки между тиками приводит к тому, что дисплей и некоторые формулы не успевают обновляться. Опытным путем я подобрал, более менее, оптимальную задержку для своего ноутбука: 150-200 мс
Так как каждая строчка «программы» выполняется за один «тик», то строчек должно быть как можно меньше, по возможности надо стараться запихать как можно больше в одну формулу. Главной проблемой оказалось, что код для «Тетриса» получается слишком большой и может совсем не поместится на лист, поэтому было решено (после того, как намучался с «Тетрисом») написать «Змейку» и постараться использовать минимальное число строк для этого.
Интерфейс ввода, т.е. кнопки управления, пришлось сделать на макросах: 4 кнопки со стрелками и 4 ячейки в которые помещается 1, если кнопка нажата, которые я назвал key_up, key_down, key_left и key_right. К ним был прикручен триггер key_trigger=IF(key_up; «U»; IF(key_down; «D»; IF(key_left; «L»; IF(key_right; «R»; key_trigger)))), в котором сохраняется последняя нажатая клавиша.
Также я сделал кнопку «Debug», для отладки программы, с помощью нее можно руками управлять тактовым генератором и смотреть как меняются состояния ячеек (она заносит попеременно 1 или 0 в ячейку clock). Это все за что отвечают макросы: тактовый генератор и органы управления. Больше макросов не будет.
Начал разработку «Змейки» с псевдокода:
Псевдокод ‘Змейки’
Для «Змейки» нужны следующие сущности: координаты головы; координаты хвоста; массив, где хранятся координаты всех точек змейки; координаты мячика.
HEAD // ядрес ячейки памяти с координатами головы
TAIL // ядрес ячейки памяти с координатами хвоста
BXBY = rand // координаты мячика
HXHY = *HEAD // координаты головы
TXTY = *TAIL // координаты хвоста
loop:
read DIRECTION // считываем направление (клавишу)
HEAD++ // увеличиваем указатель головы на единицу
HXHY += DIRECTION // векторно прибавляем направление к координатам головы
[HEAD] = HXHY // сохраняем в память новые координаты головы
BXBY <> HXHY ? JMP cltail // если координаты головы не совпали с координатами мячика, то прыгаем на "стирание хвоста"
BXBY = rand // генерируем новые координаты мячика
[BY] = OR([BY]; 9-2^BX) // рисуем мячик на экране (первые 20 ячеек памяти отображаются на экране 10х20)
JMP svtail //перепрыгиваем стирание хвоста
cltail:
[TY] = AND([TY]; XOR(FFFF; (9-2^TX))) // стираем хвост с экрана
TAIL++ // увеличиваем указатель хвоста
TXTY = [TAIL] // берем новые координаты хвоста из памяти
svtail:
[HY] = OR([HY]; 9-2^HX) // рисуем голову на экране
JMP loop // переходим на начало цикла
Вот такой несложный алгоритм получился.
Хранить данные я решил в аггрегированном виде в регистрах, например регистр ax хранит BXBYHHTT, то есть фактически 4 двузначных переменных: координаты мячика (BX и BY), номер ячейки с координатами головы (HH), номер ячейки с координатами хвоста (TT). Это усложняет доступ к переменным, но позволяет уменьшить число строк программы.
Далее нужно было этот алгоритм детализировать. Начнем с инициализации:
Дальше начинается основной цикл. Сначала я просто взял свой псевдокод и начал детализировать каждую его строчку с учетом формул Calc и архитектуры своего процессора. Вид у этого всего вышел страшный:
Здесь я заменил переменные псевдокода на регистры, в ax решил хранить 4 двузначных числа: BXBYHHTT, в bx HXHYTXTY, то есть координаты головы и хвоста, а в cx — направление, ну и использовать его для промежуточных нужд. Например, когда надо переложить из памяти в память, напрямую этого сделать нельзя, приходится делать через регистр.
Дальнейшим шагом было только заменить присваивания на команды mov, movm и mmov соответственно и перенести код в ячейки на листе.
Из интересных особенностей стоит отметить генератор случайных чисел. Функция табличного процессора нам не подходит, потому что на каждой генерации координат мячика в программе надо иметь новые случайные значения. А функция вычисляется лишь раз и потом лежит в ячейке, пока не обновишь лист. Поэтому здесь был прменен т.н. .
Для упрощения, проверок на то, что мячик появился посреди змеи не делается. Также не делается проверок на проход змеи сквозь себя.
Работает программа очень «слоупочно». Я записал видео в реальном времени и ускоренное в 16 раз. В конце видео я прохожу сквозь себя и врезаюсь в стену (в регистре bx появляестя «FAIL» и змейка больше никуда не ползет).
Ускоренное в 16 раз видео:
Реальное время
На видео можно видеть, что внизу листа есть код еще одной маленькой программы — вывод бегущей ползущей строки. Там применен некоторый «хак», а именно: в программе используются данные из соседних ячеек, но, в конце концов, почему бы и нет? Ведь никто этого и не запрещал.
Видео ускорено в 16 раз:
Проект доступен на , для работы требуется LIbreOffice Calc с установленным BeanShell.
Безусловно, интернет технологии могут расширить доступ к высшему образованию во всем мире.
Такие образовательные онлайн-платформы, как Courseraએ, и Udacityએ, стремительно вышедшие на сцену в прошлом году, по утверждению своих сторонников имеют огромный потенциал для демократизации высшего образования в странах, где доступ к нему наименьший (см. ). Сегодня такие амбиции становятся реальностью постольку, поскольку все больше людей, не смотря на серьезные проблемы, начинают экспериментировать с их установкой.
Великое множество студентов из Индии и Бразилии регистрируются на этих массовых открытых онлайн-курсах или, так называемых , продолжая свое бесплатное обучение с такими ведущими университетами, как Стэнфорд, Массачусетский технологический институт и Гарвард.
Однако, в беднейших регионах мира, где иногда затруднен надежный высокоскоростной доступ в Интернет для передачи потокового видео курса лекций, доставка образовательного контента в массы явно не простая задача, поэтому эксперименты организационного порядка здесь только начинаются (см. ).
Одна из главных задач курсов MOOCs, которые до сих пор, в основном, поступают из университетов США — это адаптация содержания к разнообразию аудиторий всего мира, к любым комбинациям языков, образовательным, мотивационным и культурным традициям. Критики опасаются большого роста образовательных кейсов всего от нескольких элитных учреждений западных стран, но это беспокойство беспочвенно в силу не соответствия различных традиций обучения у разных народов.
Такая ситуация, чисто с точки зрения курсов, начинает меняться и эти стартапы расширяются предложениями сотрудничества с международными университетами. Так, например, в феврале (2013 года) некоммерческая платформа EDX, созданная в прошлом году силами Гарварда и MIT, в качестве партнера дополнилась Федеральной политехнической школой из Лозанны, Швейцария. И хотя первые курсы проводятся на английском языке, в Школе, согласуясь с задачами развития Гражданского общества, по предложению представителей EDX теперь задумали распространить их на франкоязычные регионы Восточной и Центральной Африки.
Обслуживание и мониторинг MOOCs необходимо передавать в развивающиеся страны, ведь даже такой очень мелкий недочет как, например, невозможность загрузки и использования студентами контента, отличного от видео, имеет огромное значение. Но серьезные MOOCs идут дальше, в том числе и EDX, у которых в планах ближайших месяцев создать открытые источники своей платформы и предоставить эти источники не только университетам для создания своих онлайн-курсов, но и программистам всего мира для экспериментов и разработки настраиваемых интерфейсов.
«То, что мы уже имеем сегодня — это очень хороший первый шаг», говорит , ведущий ученый и исследователь из Microsoft. «Мы должны убедиться в том, что создаем инструменты, позволяющие легко генерировать новый контент, отличный от того, что создается в Массачусетском технологическом институте и Стэнфорде». Релевантностьએ, как отмечает он, является одним из крупнейших мотиваторов для студентов.
Многие уже сейчас, заглядывая в будущее онлайн-курсов для развивающихся странах, понимают, что нельзя надеяться исключительно на Интернет, а необходимо органичное совмещение с традиционной работой колледжей.
В Индии, например, Microsoft Research, у которого офисы в Бангалоре, сотрудничает с университетами, используя , где проводятся онлайн лекции, форумы и викторины для студентов инженерных специальностей различных школ, совмещенные с тем же курсом информатики. Еще одна интересная идея из Индии — это проект Microsoft Research по сканированию электронных учебников на предмет извлечения наиболее важных понятий, которые в дальнейшем могут быть интегрированы в обучающее онлайн видео. Таким образом, индийские профессора могут обсуждать воздействие электромагнитных полей вместе с показом ряда диаграмм из учебников по физике. Еще один проект, называется и позволяет любому комментировать видео текстом на родном языке.
В MOOCs существуют очень актуальные практические вопросы, например, обеспечение реальной сертификации независимо от местонахождения. Для этом Coursera с различными способами идентификации студента. С другой стороны Udacity просто работает с Центрами компании , которая проводит тестирование физических лиц по всему миру.
Самые грандиозные планы не могут приходить только от технологий.
Прямо сейчас, в Руанде, некоммерческая организация приступает к работе над амбициозным экспериментальным проектом, вероятно, одним из первых в своем роде — университет, полностью построенный на MOOCs.
Хотя в конце этого года (2013) будет работать только пилотный вариант, конечной целью является создание университета в Руанде для 400 человек, с обеспечением занятий всех студентов только посредством MOOCs и путем обсуждения проблемных областей для стипендиатов (коммерческих студентов). «Для начала, первые студенты попробуют курс Гарвардского университета по и курс Университета Эдинбурга «, — говорит исполнительный директор создаваемого Университета Jamie Hodari (Джейми Ходари). Как только будет достигнуто соглашение о партнерстве с по тестированию и сертификации, Университет начнет работать.
Hodari считает, что упрощается работа эксперта (учителя), когда он наблюдает без посредников (без деканата), только через провайдера MOOCs, за данными студента тем, как человек добывает знания, спотыкается в той или иной теме и это позволит сэкономить средства. Некоммерческие амбиции уже сейчас позволяют предлагать стоимость полного года обучения в пределах US $1500 и даже меньше.
Хотя только 1% руандийцев смогут с помощью интернет-технологий достичь степени бакалавра, Hodari не ждет. Ссылаясь на то внимание, которое приобрело MOOCs за последний год он утверждает — «Нам тяжело понять, прочитав все эти посылы, что уже сейчас можно учиться где нибудь в Судане и получать первоклассное высшее образование бесплатно. Сегодня нам кажется, что это очень далеко от реальности и на самом деле доступно не всем, а только немногим избранным».
Специально студентам неблизким к информационным технологиям, экономистам, юристам и прочим нетехнарям-гуманитариям, желающим знать немного больше, чем слово «браузер» …
By Jouel Spolski
Источник:
Абсолютно для каждого программиста абсолютный минимум знаний о наборах символов и Unicode, без которых решительно не обойтись. (Без возражений!)
Джоэл Спольски, Среда, 8 октября 2003
Вы никогда не задумывались о таинственном теге Content-Type? Того самого, который неизвестно как выглядит, если его надо вставить в HTML документ? Вы когда-нибудь получали электронную почту от своих друзей из Болгарии с темой «???? ???????? ????»?
Осознав, что множество разработчиков программного обеспечения абсолютно не компетентны во всем, что касается наборов символов, кодировкой, Unicode, считая все это таинственным миром, я был разочарован. Пару лет назад, при бета-тестировании , стало любопытно, а справиться ли он с входящей почтой на японском языке. Японский? Электропочта на японском? Об этом я и мечтать не смел. При тщательной отладке коммерческого ActiveX компонента, который мы использовали для анализа MIME сообщений электронной почты, мы обнаружили, что при работе с текстом он делает что-то совсем непотребное и были вынуждены героически править код для исключения неправильных преобразований, что бы заставить его работать так, как надо. Когда я присматривался к другой коммерческой библиотеке, да к тому же еще в объектном коде, то в переписке с разработчиком этого пакета узнал, что он «ничего не сможет с этим поделать». Как и большинство программистов, он просто понадеялся, что все и так сойдет. Не получилось. А когда я обнаружил, что для популярнейшего средства Web-разработки PHP демонстрируется , а для представления символов беспечно использует 8 бит, что делает практически невозможной любую «языковую примочку» в хороших международных Web-приложений, то понял — довольно, пора что-то делать.
Сегодня я официально заявляю, что если Вы программист и в 2003 году не знаете основ кодировки символов, Unicode и я Вас на этом поймаю — накажу, заставлю полгода чистить лук на подводной лодке. Клянусь — я это сделаю.
Кроме того,
ИТ не так уж сложны
В этой заметке я попытаюсь объяснить то, что должен знать каждый реальный программер. Выражение «Текст = ASCII символ = 8 бит» — не просто ошибка, а воинствующее и вопиющее незнание. Если, занимаясь программированием, Вы все еще так думаете, то Вы не намного лучше врача, который верит в бессмертие. Остановитесь, пожалуйста, не торопитесь писать еще одну строчку кода до тех пор, пока не прочитаете эту заметку.
Прежде чем я начну, должен сразу предупредить — если вы один из тех редких людей, которые знают об интернационализации, то, скорее всего, найдёте все мои рассуждения немного упрощёнными. Действительно, здесь я просто пытаюсь показать тот минимальный порог, который каждый должен перешагнуть для понимания происходящего и, возможно, написать код, только сулящий надежду на обработку текста с любым языком, кроме английского. И ещё должен предупредить, что принципы обработки — это только малая часть того, что необходимо для создания программного обеспечения международного уровня. Но одновременно писать я могу только об одном, а сегодня это наборы символов.
Историческая справка
Понять это проще всего, если заглянуть в историю. Не думаете, что сейчас я расскажу об очень старых наборах символов, например, EBCDICએ. Не буду, нет. EBCDICએ не имеет никакого отношения к нашей жизни. Так далеко углубляться в прошлое не надо. Вернёмся в лишь в недалёкое прошлое. Когда был придуман Unixએ и K&R писали о , все было очень просто. EBCDICએ был единственным выходом из положения. Символы, имеющие значение, — это только добрые старые безударные английские буквы, а код это, так называемый, -код, в котором для представления каждого символа используется число от 32 до 127. А до 32 все было свободно, буква «А» — это 65 и т.д. Все это удобно и можно хранить в 7 битах.
Большинство компьютеров тех дней использовали 8-битные байты, что позволяло особо прижимистым, скаредно экономить, использовав резерв в собственных целях — тусклая луковица WordStarએ фактически превратила свободный бит в индикатор последней буквы слова и это обрекло WordStar к обработке только английских текстов.
Все, что меньше 32 считалось нецензурными, предназначенным исключительно для ругательств. Шутка такая. На самом деле — это символы управления, например, 7 — это звуковой сигнал, которые должен изрекать компьютер, а 12 выбрасывает текущую страницу бумаги из принтера и на прокорм забирает новую.
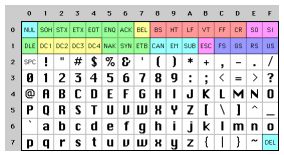
И все бы было ничего, если бы был только английский. Постольку поскольку в байт помещалось восемь бит, то многим пришло в голову — «черт возьми, для себя любимого можно использовать коды диапазона 128-255». Но всё дело в том, что эта мысль пришла одновременно ко многим, а у каждого свои собственные идеи по использованию пространства от 128 до 255. У IBM-PC это выродилось в наборы OEMએ символов, где представлены нетрадиционные для английского символы европейских языков, а так же — горизонтальные и вертикальные полосы, горизонтальные полосы с небольшими галтелями, оборванными по краям и т.д. С помощью таких графических символов можно нарисовать на экране элегантный бокс, который Вы еще сможете подсмотреть на компьютере 8088 своей химчистки. В действительности, как только ПК стали покупать за пределами Америки, каждый стал выдумывать свои наборы OEM символов, использующие верхние 128 кодов для своих собственных нужд. Например, на некоторых ПК код 130 будет отображать как символ é, а на компьютерах, продаваемых в Израиле, на иврите, будет написано гимел (λ). Поэтому, когда американцы посылают свои résumés в Израиль то, там читают rλsumλs . Частенько, например у русских, было множество различных реализаций верхних 128 кодов. Так, что надежно обмениваться русскими документами было невозможно.
В итоге по либеральному принципу «свободно для всех» OEM стало стандартом ANSIએ кодировок. Согласно стандарту ANSIએ коды до 128 полностью соответствуют ASCIIએ, а символы с кодами от 128 и выше зависят от Вашего местожительства с полной свободой реализации. Такие различия операционных систем назвали . Так, например, в Израиле DOS использует 862 кодовую страницу, в то же время греки предпочитают 737. Они одинаковы до 128 и отличаются после 128, где живут все эти смешные буковки. В национальных версиях MS-DOS были десятки кодовых страниц для обработки всего не английского, а может быть исландского. Было даже несколько «многоязычных» кодовых страниц, что позволяло работать на одном компьютере одновременно и на эсперанто, и на галисийском! Вот так! Однако, написать свою собственную программу, использующую для отображения растровую графику так, чтобы на одном компьютере работали одновременно и евреи, и греки принципиально невозможно — иврит и греческий слишком различны в интерпретации кодов и требуют абсолютно разных кодовых страниц.
А тем временем в Азии творится вообще полное безумие с учетом того факта, что азиатские алфавиты содержат тысячи символов, т.е. все их, ну никак, не вписать в 8 бит. Как правило, использовались «грязные» методы типа DBCSએ, «Double Byte Character Set», где часть букв кодируются одним байтом, а другая — двумя. В такой строке легко перемещаться вперед, но, чёрт возьми, совершенно не возможно назад. Для движения по строке назад и вперед программистам рекомендовалось не использовать *S++ и *S—, а вместо этого применять функции типа AnsiNext и AnsiPrev в Windows, которые научили бороться со всем этим кошмаром.
И все же до сих пор большинство просто делает вид, что байт — это все ещё 8 бит потому, что это всегда работает, если не переносить строки с компьютера на компьютер и говорить только на одном английском. Конечно, с появлением Интернета, когда передача текстов между компьютерами стала просто вынужденной необходимостью, весь этот порядок рухнул. Но к счастью изобрели Unicode.
Unicode
Unicodeએ — это смелая попытка создания единого набора символов, включающего все разумные системы письма на планете и даже некоторые, искусственно созданные такие, например, как «клингонский языкએ». Многие заблуждаются, считая Unicode просто 16-разрядным кодом, где каждому символу отводится 16 бит, т.е. 65 536 возможных комбинаций. На самом деле все не так. Это самый распространенный миф о Unicode, а если вы так думаете, то пусть же Вам будет хуже.
Фактически, в Unicode несколько иное представление о персонажах и Вы должны понимать мотивы, иначе все остальное теряет смысл. До сих пор мы предполагали, что образ символ соответствует некоему набору бит, который хранится на диске или в памяти:
А -> 0100 0001
В Unicodeએ символом называют код местоположения в таблице, а не битовый образ, — это теоретическая концепция. Именно, код места хранится в памяти или на диске. Образ А в Unicode — это платонический идеал. Это просто, парящий в небе символ A.
Этот платонический А отличается от B, точно так же, как а отличается А, но А не отличается от A, хотя отличается от а. Идея того, что «А» шрифта Times New Roman то же самое, что и «А» шрифта Helvetica, но отличается от «а» в нижнем регистре, не кажется очень уж спорной. Однако, выясняется, что в некоторых языках графический образ может быть сомнительным. Немецкий символ β – это действительно символ или причудливый способ написания ss? Если символ изменен в конце слова, является ли он другой буквой? Евреи говорят «да», а арабы «нет». Но по любому, Вам не придется об этом беспокоиться потому, что умные люди из консорциума Unicode на протяжении последнего десятилетия или около того только тем и занимались, что выясняли всё это, проводя большие и высокопарные политические споры для всеобщей ясности и понимания.
Всякому платоническому символу всякого алфавита консорциумом Unicode присвоено магическое число, которое записывается в виде U+0639. Это магическое число называется кодом места. U+ означает «Unicode», далее шестнадцатеричное число. U+0639 — это арабское Айн. Английская буква А — U+0041. Вы можете найти их все с помощью утилиты отображении символов вWindows 2000/XP или посетив .
В действительности в Unicode нет никаких ограничений на количество мест, даже если его надо больше чем 65 536 и символу надо сопоставить код размером большим чем два байта. Вот так и ни как иначе рушатся мифы.
Итак, у нас есть строка:
Hello,
что в Unicode соответствует пяти кодам:
U+0048 U+0065 U+006C U+006C U+006F.
Просто куча кодов. В действительности — это номера. Мы еще ничего не говорил о том, как эта куча хранится в памяти или представлена в электронной почте.
Кодировка
Вот, где введение в кодировку. Первая мысль о Unicode, которая и стала источником мифа о двух байтах, — Эй, давайте хранить эти цифры просто в двух байтах. Так Hello превращается в
00 48 00 65 00 6C 00 6C 00 6F
Верно? Но, не спешите! А не то же ли самое:
48 00 65 00 6C 00 6C 00 6F 00?
Ну, на самом деле, по технике это одно и то же и я уверен, что первые разработчики были в сомнениях — для какого конкретного режима работы процессора естественней хранить номера Unicode в старших байтах, а для какого в младших, но был вечер, и было утро, и вот уже два способа хранения Unicode. Так люди вынуждены придумать странные соглашения о записи FE FF в начале каждой строки Unicode. Это называется , и если вы смените свои старшие байты на младшие, то это будет выглядеть, как FF FE, а человек, читающий вашу строку, будет знать, что необходимо поменять местами все оставшиеся байты. Уф … Однако, в дикой природе не каждая строка Unicode содержит в начале метку порядка байтов.
Какое-то время всем всё казалось довольно удобным, но заворчали программисты. «Посмотрите на все эти нули!» — говорили они потому, что были американцами и смотрели только на английский текст, где редко используются номера более U+00FF. Более того, все эти либеральные Калифорнийские хиппи не хотели расти над собой. Техасцы даже не думали бы о двукратном поглощении байтов (прикол). Но эти калифорнийские слабаки не смогли переварить идею удвоения памяти для хранения текстов. Так или иначе, но уже есть масса ANSI и DBCS документов и, черт возьми, кто будет их конвертировать? Мы? Вот только по этой причине на протяжении нескольких лет большинство решительно игнорировало Unicode, а за это время всё стало совсем плохо.
В итоге, появилась блестящая концепция . UTF-8એ – это другая системы хранения кодов, этих волшебных U+номеров строки Unicode в памяти с помощью 8 битного байта. В UTF-8 каждый код от 0 до 127 хранится в одном байте. И только для хранения некоторых кодов от 128 и больше используются 2, 3, а на самом деле, до 6 байтов.
Английский текст выглядит в UTF-8 точно так же, как в ASCII, в чем нет ничего плохого. Но американцы даже не замечают этого галантного побочного эффекта. А весь остальной мир вынужден подпрыгивать в кольце. В частности, Hello, U+0048 U+0065 U+006C U+006C U+006F, будет храниться в виде 48 65 6C 6C 6F, вот! Точно так же как он хранится в ASCII, ANSI и любом OEM наборе планеты. Теперь, если вы возьмете на себя смелость использовать нестандартные или греческие буквы, клингонский язык, и должны будете использовать несколько байт для хранения одного номера символа, то американцы этого просто не заметят. (Кроме того, UTF-8 обладает хорошим свойством не обрезать строки в косолапой старой строке, где байт со значение NULL используется как нуль-терминатор).
До сих пор я говорил о трёх способах кодирования Unicode. Традиционные store-it-in-two-byte методы называются UCS-2એ (потому что два байта) или UTF-16 (потому что 16 бит) и вы поняли, что такое UCS-2 старшего байта и UCS-2 младшего байта. Новый популярный UTF-8એ, обладает еще одним замечательным свойством — счастливым совпадением текстов на английском языке в различных кодировках, что позволяет прилично работать брендовым программам, которые даже не подозревают, что существует нечто кроме ASCII.
На самом деле есть масса других способов кодирования Unicode. Например, так называемый, UTF-7એ, который очень похож на UTF-8એ, но с гарантией нулевого значения старшего бита, что дает ему возможность, при необходимости, пробиться через всякие драконовские ограничения системы электронной полиции. Думается, что 7 битов Unicode вполне достаточно, что бы пролезть там без искажений.
Есть UCS-4એ, где каждый код места хранится в 4 байтах, обладающий замечательным свойством, хранения кода в фиксированном количестве байт, но, ей-богу, в самом деле, даже техасцы не настолько решительны, что бы жертвовать под отходы такую уйму памяти.
Надеюсь теперь, Вы думаете о сущности с точки зрения платонического идеала буквы, представленной номером в Unicode, которое может быть закодировано по схеме любой не слишком древней школы кодирования! Например, вы можете кодировать Unicode строку Hello (U+0048 U+0065 U +006C U+006C U+006F) в ASCII или старом OEM греческой кодировки, или иврите ANSI кодировки, или любой другой из нескольких сотен кодировок, изобретённых до сих пор с пониманием того, что некоторые буквы могут просто не отображаться! Если номер Unicode не заполнен, а Вы пытаетесь показать этот символ, то, обычно, получаете небольшой знак вопроса «?», а если Вы действительно хороши, то вопрос в коробке �. У Вас какой?
Есть сотни традиционных кодировок, где верно хранятся только некоторые номера, а все остальные места Unicode заменяются вопросительным знаком. Наиболее популярными кодировками текста для английского являются Windows-1252એ (Windows 9x стандарт западноевропейских языков) и , также известный как Latin-1 (полезен для любого западноевропейского языка). Но попробуйте в них сохранить буквы русского или иврита и вы получите кучу вопросительных знаков. А вот UTF, 7, 8, 16 и 32 — все обладают хорошими свойствами и позволяют правильно хранить любой номер.
Самое важное в кодировках
Если вы полностью забудите все, что я только что сейчас объяснил, помните одно чрезвычайно важное обстоятельство — строка не имеет смысла, если не известна её кодировка. И Вы больше не можете прятать голову в песок и делать вид, что «просто текст» — это ASCII.
Нет такого понятия «просто текст».
Если у вас есть строка, в памяти, в файле или в сообщении электронной почты, то необходимо точно знать в какой она кодировке, иначе Вы не сможете её правильно интерпретировать и показать пользователям.
Почти каждый брюзжал — «мой сайт выглядит бредом» или «она не может прочитать мои письма не на английском». А проблему создал один наивный программист, который не понимает простого факта — если ему не сказали, что конкретная строка закодирована UTF-8, ASCII, ISO 8859-1 (Latin 1) или Windows 1252 (западноевропейская), то просто невозможно правильно её отобразить, более того, даже выяснить, где же она заканчивается.
Существует более ста кодировок, где номера более 127 полностью отсутствуют.
Как сохранить информацию о кодировке строки? Для этого есть несколько стандартных способов. Для сообщений электронной почты, вам потребуется строка в заголовке формы
Content-Type: text/plain; charset=»UTF-8″
Для веб-страниц была оригинальная идея — веб-сервер в заголовке http возвращает аналогичный Content-Type, т.е. не в HTMLએ странице, а в заголовке, который отправляются до передачи самой HTML страницы.
Однако, в этом есть проблема. Допустим, у вас большой веб-сервер с огромным количеством сайтов и миллионами страниц, размещенных множеством людей на самых разных языках с использованием любых возможных кодировок, которые по своему усмотрению генерирует MS FrontPageએ. Веб-сервер сам по себе не может знать кодировку каждого файла и поэтому не может отправить соответствующий Content-Type заголовка.
Было бы удобно получить возможность размещать Content-Type в самом файле HTML, используя какой-то специальный тег. Конечно, пуристы сочтут Вас за сумасшедшего … Как вы можете прочитать HTML файл, если не знаете в какой он кодировке?! К счастью, почти у всех кодировок коды всех символов от 32 до 127 одинаковы, так что вы всегда можете прочитать страницу HTML без использования смешанных записей до:
Этот мета тег действительно должен быть самым первым, прочитав его, веб-браузер останавливает дальнейшую обработку страницы и заново начинает все переосмысливать, применяя полученную от Вас кодировку.
Что делают веб-браузеры, если не находят Content-Type в HTTPએ заголовке или в мета-теге? Internet Explorer на деле предпринимает что-то довольно интересное — по частоте появления характерных байт в характерных местах текста он пытается угадать язык и кодировку. По-столько по-скольку, старых 8 битовых страниц мало, а национальные буквы, из диапазона между 128 и 255, имеют характерные частоты распределения в текстах различных человечьих языков, то это, скорее всего, имеет шансы работать. По настоящему странно то, что это работает довольно часто потому, что веб-страницы наивных писателей, которые никогда не знали о Content-Type в заголовке, выглядят в web-браузере нормально, пока в один прекрасный день, они не начнут писать тексты с отличным от их родного языка частотным распределение букв. Тогда Internet Explorer решит, что это корейский и соответствующим образом отобразит, доказывая, как думается, закон Постела «Будь требователен к тому, что отсылаешь, и либерален к тому, что принимаешь», откровенно неважный принцип для инженера. Во всяком случае, что делает бедный читатель болгарского сайта, который показан на корейском (и даже фрагментарно на корейском)? В главном меню «Просмотр» пункт «Кодировка» он пытается перебирать кучу разных кодировок (по крайней мере дюжину для восточн-европейских языков), пока страница не прояснится. Если он знает, что делать, но большинство об этом не знает.
В программном обеспечении последней версии — системы управления контентом сайта , мы решили всю внутреннюю кодировку сделать в UCS-2 (два байта) Unicode, которая по жизни была родной в Visual Basic, COM, и Windows NT/2000/XP. В кодах на C++ мы просто объявили строки как wchar_t («широкий символ»), а не char и использовать wcs_функции вместо str_функций (например, wcscat и wcslen вместо strcat и strlen). Для записи литеральной константы UCS-2 в коде на C достаточно перед ней просто написать символ L, вот так: L»Hello».
Когда CityDesk публикуется, то веб-страницы преобразуются в UTF-8, который на протяжении многих лет замечательно поддерживается большинством веб-браузеров. Вот так кодируются все программного обеспечения от Joel и еще ни от одного человека я не слышал жалоб на какие-либо проблемы при просмотре.
Заметка становится довольно нудной, хотя, все еще не охватила всего того, что надо знать о кодировках и Unicode. Однако, надеюсь, что ежели Вы дочитали до сюда, то знаете достаточно и можете вернуться к программированию без пиявок и заклинаний, применив прописанные здесь антибиотики.
Обдумывая проблемы, великие мыслители во всем находят общность. Глядя на людей посылающих друг другу файлы текстовых процессоров или файлы электронных таблиц, они понимают, что существует общность — отправка файлов. Уже готов первый уровень абстракции. Тогда они идут дальше — люди «отправляют» файлы, а веб-браузеры «отправляют» запросы на веб-страницы. А если немного подумать, то вызов метода объекта схож с отправкой сообщения объекту! Следующее обобщение, все это — операции отправки. Позднее наш умный мыслитель изобретает новую, более высокую, более всеобъемлющую абстракцию, которую называет messaging. И все становится настолько расплывчатым, что уже никто не понимает, о чем речь. Бла-бла-бла.
Наполненные великими абстракциями, Вы поднимаетесь столь высоко, что оказываетесь в безвоздушном пространстве. Иногда умные мыслители просто не знают, когда пора остановиться. Они создают свои нелепые, всеохватывающие фотографии вселенной наивысшего уровня абстракции, где все хорошо и прекрасно, а на самом деле уже ничего не рассмотреть. Читать далее «Не позволяйте космонавтам архитектуры запугивать себя»
Последние три года уровень доходов IT-специалистов в госсекторе США не претерпевает значительных изменений — зарплаты и бонусы практически замерли на месте. Однако за последний год, , наметился небольшой рост средней заработной платы сотрудников, количество недовольных своей работой при этом снизилось. Читать далее «Посчитаем деньги в чужом кармане»

![d01a237e261749658ef4234ddc80819d[1]](http://waksoft.susu.ru/wp-content/uploads/2015/04/d01a237e261749658ef4234ddc80819d1.png)
![3cd86e1153a04e89ac9d048fe1240734[1]](http://waksoft.susu.ru/wp-content/uploads/2015/04/3cd86e1153a04e89ac9d048fe12407341.png)
![e03588c4cbb047d0a76a128eac6dc6d8[1]](http://waksoft.susu.ru/wp-content/uploads/2015/04/e03588c4cbb047d0a76a128eac6dc6d81.png)
![bd856de810d24284bf8f21fac1260bcd[1]](http://waksoft.susu.ru/wp-content/uploads/2015/04/bd856de810d24284bf8f21fac1260bcd1.png)
![next.step_.moocsx299[1]](/wp-content/uploads/2015/04/next.step_.moocsx2991.jpg)
 В итоге по либеральному принципу «свободно для всех» OEM стало стандартом
В итоге по либеральному принципу «свободно для всех» OEM стало стандартом