10 апреля в ЧЕЛГУ состоялся Межвузовский студенческий брифинг на английском языке «Возможности современных информационных ресурсов». Среди команд-участниц были представители вуза-организатора – ЧелГУ, ЮУрГУ, Русско-Британского института управления, и Челябинского института путей сообщения. ЮУрГУ представляли студенты кафедры «Информационные системы» факультета Экономики и предпринимательства Пинтус Артур, Савицкий Артём, Сметанин Павел (все из группы ЭиП 212).
Читать далее «Межвузовский студенческий брифинг на английском языке «Возможности современных информационных ресурсов»»
Рубрика: ИКТ образования
Практика применения ИКТ в образовательном процессе
Несколько секретов поиска в Google

Если вы активно пользуетесь Интернетом, то, наверняка, используете поисковик от Google по нескольку раз в день. Но, думаю, что не ошибусь в том, что вы используете его в самой простейшей форме. Т.е. в большинстве случаев все использование поисковика сводится к набору нескольких слов в строке поиска и к последующему изменению запросов пока не находится именно то, что вам нужно. Но я хочу вам дать несколько простых советов, которые позволят вам сэкономить время, затраченное на поиск. Благодаря этим советам вы больше не будете посыпать голову пеплом в случаях, когда уже отчаялись найти нужную информацию.
Читать далее «Несколько секретов поиска в Google»
Об авторских правах на переводы

Новый проект предназначен, прежде всего, для автоматизированного сбора контента с персональных сайтов, созданных на базе CMSએ WordPressએ, студентов инфо-коммуникационных специальностей. Этот проект инициирован и совместно реализован кафедрами и . В качестве собираемого контента используются переводы научно-популярных статей из Интернета, сделанные и опубликованные авторами — владельцами сайтов блог-клиентов, из персональных электронных дневников студентов. Реализовать проект позволяет то обстоятельство, что начиная с I курса обучения по образовательному направлению 080500.62 Бизнес-информатикаએ, все студенты должны создать и вести свой персональный электронный дневник. О резонах использования такой методологии подготовки специалистов информационных технологий можно ознакомится здесь. Так как материалы для перевода заимствуются со сторонних ресурсов неплохо бы разобраться с авторскими правами.
С++ — «латинский» XXI века

I’m going back to ones and zeros.
(You had ones? Lucky bastard! All we got were zeros.)
The Perils of Java Schools by Joel Spolsky, Thursday, December 29, 2005
Я возвращаюсь назад к нулям и единицам.
(У тебя есть единицы? Везучий отморозок! У нас были только нули.)
Опасности Java школ. Джоэл Спольски, четверг, 29 декабря 2005
Все чаще и чаще, в разговорах бывалых возникает тема — «программисты скоро вымрут, и останутся дизайнеры программного обеспечения».
Реактивное программирование в табличном процессоре
Табличный процессор (речь идет о MS Excel или LibreOffice Calc) — это довольно занятный и универсальный инструмент. Мне часто приходилось (и приходится) пользоваться его широкими возможностями: автоматизированные отчеты, проверка гипотез, прототипирование алгоритмов. Например, я использовал его для решения задач , быстрой проверки алгоритмов, реализовал парсер одного прикладного протокола (по работе надо было). Мне нравится наглядность, которую можно добиться в табличном процессоре, а еще мне нравится нестандартное применение всего, чего только возможно. На Хабре уже появлялись интересные статьи на тему нестандартного применения
Excel:
В этой длинной статье я хочу поделиться своими экспериментами в с помощью формул табличного процессора. В результате этих экспериментов у меня получился «компьютер» с процессором, памятью, стеком и дисплеем, реализованный внутри LibreOffice Calc при помощи одних только формул (за исключением тактового генератора), который можно программировать на неком подобии ассемблера. Затем, в качестве примера и proof-of-concept, я написал игру «Змейка» и бегущуюползущую строку для этого компьютера.
Предисловие
Началось все с того, что я заинтересовался различными парадигмами программирования, посетил вводное занятие по в клубе робототехники; и вот в статье на википедии по я наткнулся на следующий текст:
Современные табличные процессоры представляют собой пример реактивного программирования. Ячейки таблицы могут содержать строковые значения или формулу вида «=B1+C1», значение которой будет вычислено исходя из значений соответствующих ячеек. Когда значение одной из зависимых ячеек будет изменено, значение этой ячейки будет автоматически обновлено.
Действительно, любой кто пользовался формулами в Excel знает, что изменив одну ячейку мы меняем связанные с ней ячейки — получается довольно похоже на распространение сигнала в цепи. Все эти факторы и навели меня на следующие мысли: а что если эта «цепь» будет достаточно сложной? являются ли формулы в табличном процессоре ? можно ли «запрограммировать» формулы, так чтобы получить какие-нибудь нетривиальные результаты? (например сделать тетрис) Т.к. последнее время я использую Ubuntu на работе и дома, то все эксперименты я проводил в LibreOffice Calc 4.2.7.2
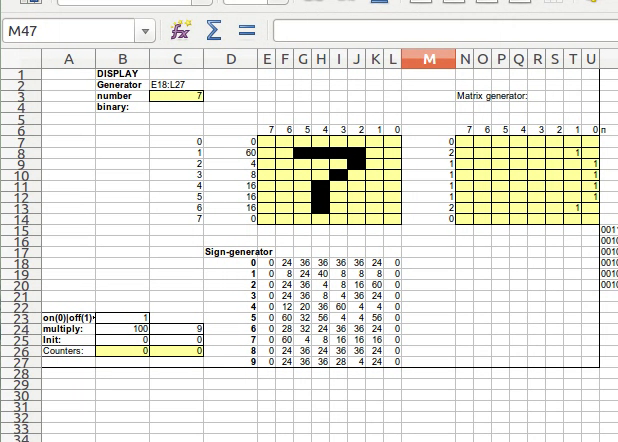
Цифровой дисплей 8×8
Начал эксперименты я с реализации дисплея. Дисплей представляет из себя набор квадратных ячеек 8х8. Здесь пригодилось условное форматирование (оно есть и в Excel и в Calc). Выделяем ячейки, заходим в Format/Conditional Formatting/Condition… и настраиваем внешний вид: черный фон, при условии, что в ячейке содержится, например, пробел. Теперь если записать в ячейку пробел, то она становится черной. Таким образом реализуются пиксели нашего дисплея. Но этим дисплеем хочется как-то управлять. Слева от него я выделил специальный столбец в который будут заноситься числа — идея такая, чтобы этим числом мы задавали битовую маску для отображения на экране. Сверху экрана я пронумеровал столбцы. Теперь в каждую ячейку дисплея мы должны написать формулу, которая даст в результате либо пробел, либо пустую строку, в зависимости от того, установлен ли нужный бит в самом левом столбце.
=IF(MOD(TRUNC(<битовая маска>/(2^<номер столбца дисплея>));2);" ";"")
Здесь, по сути, происходит сдвиг вправо (деление на степень двойки и потом отброс дробной части), а затем берется 0-й бит, то есть остаток от деления на 2, и если он установлен, то возвращается пробел, иначе пустая строка.
Теперь при записи в самый левый столбец какого-то числа на дисплее отображаются пиксели. Далее мне хотелось сгенерировать битовых масок, например, для десятичных цифр и, в зависимости от цифры, заполнять столбец масок дисплея нужными числами.
Для генерации была создана еще одна конструкция 8х8, в которую руками заносятся единицы, а формула сворачивает все это в одно число:
=SUMPRODUCT(<строка ячеек с единичками и ноликами>;2^<строка с номерами позиций>)
В итоге получил такую матрицу битовых масок для цифр:
Sign-generator
0 0 24 36 36 36 36 24 0 1 0 8 24 40 8 8 8 0 2 0 24 36 4 8 16 60 0 3 0 24 36 8 4 36 24 0 4 0 12 20 36 60 4 4 0 5 0 60 32 56 4 4 56 0 6 0 28 32 24 36 36 24 0 7 0 60 4 8 16 16 16 0 8 0 24 36 24 36 36 24 0 9 0 24 36 36 28 4 24 0
Здесь каждая строка соответствует десятичной цифре. Возможно, не самые красивые цифры вышли, к тому же, верхний и нижний ряд не использован, ну уж как нарисовал, так нарисовал )
Далее применим функцию INDEX, если ей указать матрицу, ряд и колонку, то она возвращает значение из этой матрицы. Так что, в каждой ячейке битовой маски дисплея пишем формулу
INDEX(<матрица>; <цифра> + 1; <номер строки дисплея>+1)
единицы прибавляются потому, что INDEX считает координаты с единицы, а не с нуля.
Циклические ссылки
Что ж, дисплей готов, пишешь руками цифру — она отображается. Далее мне захотелось сделать так, чтобы цифра сама переключалась, то есть некий счетчик, который будет накапливать сумму. Здесь то и пришлось вспомнить про циклические ссылки в формулах. По-умолчанию, они выключены, заходим в опции, разрешаем циклические ссылки, я у себя настроил вот так:
Опции вычислений
![d01a237e261749658ef4234ddc80819d[1]](http://waksoft.susu.ru/wp-content/uploads/2015/04/d01a237e261749658ef4234ddc80819d1.png)
Циклическая ссылка подразумевает под собой формулу в ячейке, зависящую от нее самой же, например, в ячейку A1 мы запишем формулу «=A1+1». Такая ячейка, конечно, не может быть вычислена — когда заканчивается число допустимых итераций, то Calc выдает либо #VALUE, либо ошибку 523. К сожалению, обмануть Сalc не удалось, идея была такая, чтобы сделать одну ячейку постоянно растущей до какого-то предела, например, в A1 я бы записал что-то вроде: =IF(A1<500; A1+1; 0), а в B1, например, такое: =IF(A1=500;B1+1;B1). 500 — это просто магическое число, которое должно было обеспечить задержку, то есть, пока в А1 накапливается сумма, это заняло бы какое-то время, а потом бы поменялся B1. (Ну тут надо было бы еще позаботиться о начальной инициализации ячеек.) Однако, мой план не сработал: в Calc реализованы какие-то хитрые алгоритмы кэширования и проверки (я даже немножко заглядывал в исходники, но подробно не ковырялся), что зациклить вычисление формулы не получается, какие бы хитрые зависимости не были. Кстати в Excel 2003 этот трюк, кажется, частично срабатывал, и, вообще, там похоже другая модель вычисления формул, но я все-таки решил экспериментировать в Calc. После этого я решил сделать счетчик на макросах, а на него уже навешивать все свои зависимости. Один товарищ мне, вообще, подсказал сделать на макросах только синхроимпульс (сигнал clock), а на него уже навешивать счетчики и все что нужно. Идея мне понравилась — макрос получался тривиальным: задержка и смена состояния на противоположное. Сам же счетчик состоит из 4-х ячеек:
Cчетчик от 0 до 9
| A | B | |
|---|---|---|
| 1 | Reset | 0 |
| 2 | Clock | [меняется макросом 0 или 1] |
| 3 | Old value | =IF(B1=1; 0; IF(B2 = 0; B4; B3)) |
| 4 | New value | =IF(B1 = 1; 0; IF(AND(B2 = 1; B4 = B3); IF(B4<9; SUM(B4;1); 0); B4)) |
Здесь уже предусмотрен сброс для инициализации начальных значений, путем занесения 1 в A1.
Такой счетчик подключается к дисплею из предыдущего раздела, и получается то, что видно на данном видео:
Счетчик + дисплей 8х8
Жаль, что не получилось обойтись полностью без макросов и тактовый генератор сделать на формулах не получилось. Кроме этого, возникла еще одна проблема: когда макрос зациклен — он блокирует основной поток, и ничего уже сделать нельзя, приходится завершать работу Calc. Но у меня уже зрели мысли об интерактивности, хотелось как-то управлять своей будущей схемой, например, сбрасывать все в ноль, или менять какие-то режимы во время работы.
Неблокирующий таймер
К моему счастью, оказалось, что в Calc можно сделать так, чтобы основной поток макроса не блокировался. Здесь я немного слукавил и просто «нагуглил» готовое решение, приспособив его под себя. Это решение требовало Bean Shell для LibreOffice. Пакет называется libreoffice-script-provider-bsh. Код состоит из 2х частей: одна на BeanShell, другая на LibreOffice Basic. Честно говоря, полностью в коде я не разобрался… каюсь (не владею Java, BeanShell, да и с объектной моделью LibreOffice не особо знаком), но кое-что все-таки подправил.
BeanShell часть
import com.sun.star.uno.Type;
import com.sun.star.uno.UnoRuntime;
import com.sun.star.lib.uno.helper.PropertySet;
import com.sun.star.lib.uno.helper.WeakBase;
import com.sun.star.task.XJobExecutor;
import com.sun.star.lang.XInitialization;
import com.sun.star.beans.PropertyValue;
import com.sun.star.beans.XPropertyChangeListener;
import com.sun.star.beans.PropertyChangeEvent;
import com.sun.star.lang.EventObject;
import com.sun.star.uno.AnyConverter;
import com.sun.star.xml.crypto.sax.XElementStackKeeper ; // defines a start and a stop routine
// This prevents an error message when executing the script a second time
xClassLoader = java.lang.ClassLoader.getSystemClassLoader();
try {
xClassLoader.loadClass("ms777Timer_01");
} catch (ClassNotFoundException e)
{
System.out.println( "class not found - compiling" );
public class ms777Timer_01 extends PropertySet implements XElementStackKeeper
{
// These are the properties of the PropertySet
public boolean bFixedRate = true;
public boolean bIsRunning = false;
public int lPeriodInMilliSec = 2000;
public int lDelayInMilliSec = 0;
public int lCurrentValue = 0;
public XJobExecutor xJob = null;
// These are some additional properties
Task xTask =null;
Timer xTimer = null;
public ms777Timer_01() {
registerProperty("bFixedRate", (short) 0);
registerProperty("bIsRunning", (short) com.sun.star.beans.PropertyAttribute.READONLY);
registerProperty("lPeriodInMilliSec", (short) 0);
registerProperty("lDelayInMilliSec", (short) 0);
registerProperty("lCurrentValue", (short) 0);
registerProperty("xJob", (short) com.sun.star.beans.PropertyAttribute.MAYBEVOID);
xTimer = new Timer();
}
//XElementStackKeeper
public void start() {
stop();
if (xJob==null) {return;}
xTask = new Task();
lCurrentValue = 1;
bIsRunning = true;
if (bFixedRate) {
xTimer.scheduleAtFixedRate( xTask, (long) lDelayInMilliSec, (long) lPeriodInMilliSec );
} else {
xTimer.schedule( xTask, (long) lDelayInMilliSec, (long) lPeriodInMilliSec );
}
}
public void stop() {
lCurrentValue = 0;
bIsRunning = false;
if (xTask!=null) { xTask.cancel();}
}
public void retrieve(com.sun.star.xml.sax.XDocumentHandler h, boolean b) { }
class Task extends TimerTask {
public void run() { // эта функция вызывается по таймеру и дергает триггер, в который мы передаем либо 0 либо 1
xJob.trigger(lCurrentValue.toString());
if (lCurrentValue == 0)
lCurrentValue = 1;
else
lCurrentValue = 0;
}
}
}
System.out.println( "ms777PropertySet generated" );
} // of if (xClass = null)
Object TA = new ms777Timer_01();
return TA;
LibreOffice Basic часть
Sub clock // эту функцию я повешал на кнопку, чтобы запускать и останавливать "тактовый генератор"
if isEmpty(oP) then // если запустили первый раз, то создаем эти неведомые объекты в которых я не разобрался
oP = GenerateTimerPropertySet()
oJob1 = createUnoListener("JOB1_", "com.sun.star.task.XJobExecutor")
oP.xJob = oJob1
oP.lPeriodInMilliSec = 150 // здесь задается задержка
endif
if state = 0 then // а здесь смена состояния, 0 - означает синхроимпульс остановлен и его надо запустить
oP.start()
state = 1
else // в противном случае означает что синхроимпульс запущен и его надо остановить
oP.stop()
state = 0
endif
End Sub
function GenerateTimerPropertySet() as Any // функция в которой достается срипт на BeanShell
oSP = ThisComponent.getScriptProvider("")
oScript = oSP.getScript("vnd.sun.star.script:timer.timer.bsh?language=BeanShell&location=document")
GenerateTimerPropertySet = oScript.invoke(Array(), Array(), Array()
end function
sub JOB1_trigger(s as String) // это триггер который вызывается по таймеру из BeanShell скрипта
SetCell(1, 2, s)
end sub
sub SetCell (x as Integer, y as Integer, val as Integer) // установить значение в ячейке с координатами X, Y
ThisComponent.sheets.getByIndex(1).getCellByPosition(x, y).Value = val
end sub
Итак, на лист я добавил компонент кнопку, назвал ее «Cтарт/Стоп» и повешал на нее функцию clock. Теперь при нажатии кнопки, ячейка меняла свое значение на 0 или 1 с заданным интервалом, и поток приложения больше не блокировался. Можно было продолжать эксперименты: вешать какие-то формулы на синхро-сигнал и всячески «извращаться».
Тут я начал думать, чего-бы такого сделать. Вот экран есть, логику, вроде как, любую можно реализовать, есть синхроимпульс. А что, если сделать бегущую строку, или, вообще, «Тетрис»? Это ж у меня получается, практически, цифровая схемотехника! Тут вспомнилась занятная игра по цифровой схемотехнике: , там одно из заданий было сделать сумматор и память с адресным доступом. Если там это возможно было сделать, значит и тут можно — подумал я. А раз есть экран, значит надо сделать игру. А там где одна игра, там и другая, значит надо сделать возможность делать разные игры… Примерно, как-то так, в мою голову пришла идея сделать процессор, чтобы можно было в ячейки заносить команды, а он бы их считывал, менял свое состояние и выводил на экран то, что мне нужно.
Размышлений было много, проб и ошибок тоже, были мысли сделать эмулятор готового процессора, например Z80 и другие не менее безумные мысли… В конце концов я решил попробовать сделать память, стек, регистры и парочку команд типа mov, jmp, математические же команды типа add, mul, sub и т.д. было решено не делать, ибо формулы Calc уже и так это умеют и даже больше, так что я решил использовать в своем «ассемблере» напрямую формулы табличного процессора.
Память
Память это такой черный ящик, которому на вход можно подать адрес, значение, и сигнал на запись. Если сигнал на запись выставлен, то значение сохраняется по данному адресу внутрь черного ящика, если сигнал не выставлен, то на выходе черного ящика появляется значение, сохраненное ранее по данному адресу. Еще нужен отдельный вход для очистки содержимого. Вот такое определение памяти я себе придумал для реализации. Итак, у нас есть ячейки, для хранения значения, и есть «интерфейсы»: входы и выход:
m_address - адрес m_value_in - значение для записи m_set - сигнал "записать" m_value_out - значение при чтении, выходной сигнал m_clear - сигнал на очистку
Чтобы было удобнее, самое время воспользоваться возможностью именовать ячейки в Calc. Становимся на ячейку, Insert/Names/Define… Это позволит дать понятные имена ячейкам и использовать в формулах уже эти имена. Итак, я дал имена 5ти ячейкам, что описаны выше. Дальше выделил квадратную область 10х10 — это те ячейки которые будут хранить значения. По краям пронумеровал строки и столбцы — чтобы использовать номера столбцов и строк в формулах. Теперь каждая ячейка, хранящая значение, заполняется одинаковой формулой:
=IF( m_clear = 1; 0; IF(AND(m_address = ([ячейка_с_номером_ряда] * 10) + [ячека_с_номером_колонки]; m_set = 1); m_value; [текущая_ячейка])),
логика тут простая: сначала проверяется сигнал очистки, если он выставлен, то обнуляем ячейку, в противном случае смотрим совпадает ли адрес (ячейки адресуются числом 0..99, столбцы и строки пронумерованы от 0 до 9) и выставлен ли сигнал на запись, если да, то берем значение на запись, если нет, то сохраняем свое текущее значение. Протягиваем формулу по всем ячейкам памяти, и теперь мы можем заносить в память любые значения. В ячейку m_value_out заносим следующую формулу: =INDIRECT(ADDRESS(ROW([первая_ячейка_памяти]) + m_address / 10; COLUMN([первая_ячейка_памяти]) + MOD(m_address; 10); 1;0);0), функция INDIRECT возвращает значение по ссылке заданной в строке, а функция ADDRESS как раз возвращает строку со ссылкой, аргументы это ряд и колонка листа, и тип ссылки. Я оформил это таким образом:
![3cd86e1153a04e89ac9d048fe1240734[1]](http://waksoft.susu.ru/wp-content/uploads/2015/04/3cd86e1153a04e89ac9d048fe12407341.png)
Тут желтым цветом обозначены входные сигналы, в которые можно писать значения, в них формул нет, а красным выделено то, что трогать нельзя, зеленое поле — это выходное значение, оно содержит формулу и на него можно ссылаться в других формулах.
Cтек
Память готова, теперь я вздумал реализовать стек. Стек — это такой черный ящик, которому на вход можно подать значение, сигнал на запись и сигнал на чтение. Если подан сигнал на запись, то стек сохраняет значение у себя внутри, рядом с ранее сохраненными, если подан сигнал на чтение, то стек на выходе выдает крайнее сохраненное у себя значение, и удаляет его у себя внутри так, что крайним значением становится предыдущее сохраненное. Здесь уже пришлось повозиться, потому что, в отличие от памяти, стек имеет внутреннюю структуру: указатель на вершину стека, который должен правильно менять свое состояние. Итак, для интерфейсной части я завел следующие ячейки:
s_address - адрес откуда начинаются ячейки для хранения, например "Z2" s_pushvalue - значение, которое надо записать в стек s_push - сигнал на запись s_pop - сигнал на извлечение из стека s_popvalue - выходной сигнал - значение, извлеченное из стека s_reset - сигнал сброса
Для внутренних структур я завел следующие ячейки:
sp_address - адрес ячейки куда показывает указатель стека sp_row - ряд sp_address sp_column - колонка sp_address sp - указатель стека, число, например 20 означает что 20 значений уже сохранено в стек и следующее будет 21-е oldsp - старый указатель стека, нужен для корректной работы sp
Ну и осталась длинная строка ячеек, в которых будут храниться значения. Начнем с формулы для извлечения значения s_popvalue =IF(s_pop=1; INDIRECT(sp_address; 0); s_popvalue), тут все просто, если сигнал для извлечения подан, то просто берем значение ячейки по адресу, куда показывает указатель стека, иначе сохраняем старое значение. Формулы для внутренних структур:
| ячейка | формула |
|---|---|
| sp_address | =ADDRESS(sp_row; sp_column; 1;0) |
| sp_row | =ROW(INDIRECT(s_address)) |
| sp_column | =COLUMN(INDIRECT(s_address)) + sp |
| oldsp | =IF(AND(s_push = 0; s_pop = 0); sp; oldsp) |
Здесь легко заметить, что для формирования адреса, куда показывает стек, мы берем адрес начала стека и прибавляем к нему указатель стека. Старое значение указателя стека обновляется в случае когда оба сигнала: и на запись и на извлечение — нулевые. Пока все просто. Формула для sp же довольно сложна, поэтому я приведу ее с отступами, для лучшего понимания:
Указатель стека sp
=IF(s_reset = 1; // если сигнал сброса, то
0; // сбросить указатель в 0
IF(AND(sp = oldsp; c_clock = 1); // иначе проверяем равен ли стекпойнтер старому значению и взведен ли синхросигнал (то есть надо ли обновить стекпойнтер)
SUM(sp; IF(s_push = 1; // если обновление стекпойнтера требуется, значит к старому значению прибавляем некое смещение (-1, 0 или 1)
1; // прибавляем к стекпойнтеру 1, в случае если сигнал push
IF(s_pop=1; // в противном случае, если сигнал pop, то прибавляем либо 0 либо -1
IF(sp > 0; -1; 0); // -1 прибавляем в случае, когда sp > 0, иначе прибавляем 0, то есть оставляем старое значение
0))); // старое значение оставляем в случае когда ни push ни pop не взведены
sp)) // если стекпойнтер не равен старому значению, или синхросигнал невзведен то сохраняем старое значение
5 вложенных IF выглядят монстрообразно, в дальнейшем я такие длинные формулы разделял на несколько ячеек так, чтобы в каждой ячейке было не больше 2-х IF’ов.
Осталось привести формулу для ячеек, хранящих значение:
=IF (s_reset = 1; 0; IF (AND(s_push = 1; ROW([текущая_ячейка]) = sp_row; SUM(COLUMN([текущая_ячейка]); 1) = sp_column; oldsp <> sp); s_pushvalue; [текущая_ячейка]))
здесь в принципе можно «распарсить» без отступов, суть такова, что проверяется некоторое условие и в случае, когда это условие выполняется — в ячейку заносится s_pushvalue. Условие следующее: должен быть взведен сигнал s_push; ряд ячейки должен совпадать с рядом, куда указывает sp; колонка, куда показывает sp, должна быть на 1 больше, чем колонка нашей ячейки; ну и sp не должен равняться своему старому значению oldsp.
Картинка для наглядности, что у меня получилось:
![e03588c4cbb047d0a76a128eac6dc6d8[1]](http://waksoft.susu.ru/wp-content/uploads/2015/04/e03588c4cbb047d0a76a128eac6dc6d81.png)
Процессор
Ну вот, память есть, стек есть. Экран я сделал побольше чем 8х8, т.к. изначально думал про тетрис, то сделал 10х20, как на BrickGame из 90х. Первые 20 ячеек своей памяти я использовал в качестве видеопамяти, то есть подключил их к 20 строкам экрана (поэтому на картинке они темно-красного цвета), теперь я могу рисовать на экране что-то, путем занесения в память по нужному адресу нужных мне значений. Осталось реализовать главное: то, что будет пользоваться памятью, стеком, считывать команды и исполнять их.
Итак, центральный процессор у меня состоит из следующих частей:
Структуры CPU
Входы: c_reset - сигнал сброса (обнуляет состояние процессора) c_main - адрес начала программы, точка входа c_clock - синхроимпульс, подается извне pop_value - значение из стека, подключается к стеку =s_popvalue Внутренние структуры: command - команда на выполнение opA - первый операнд команды opB - второй операнд команды cur_col - текущий ряд (куда показывает ip) cur_row - текущая колонка ip - instruction pointer, указатель на команду oldip - старый ip, нужен для корректной работы ip ax - регистр общего назначения (РОН) bx - РОН cx - РОН rax - копия ax, нужна для того, чтобы корректно модифицировать значение ax rbx - копия bx rcx - копия cx Выходы: mem_addr - адрес памяти, подключено к памяти mem_value - значение для записи в память или считанное из памяти mem_set - сигнал для записи в память, подключен к памяти pop_value - значение из стека, или для записи в стек, подключено к стеку push_c - сигнал записи в стек pop_c - сигнал чтения из стека
Вкратце, как все работает: входы подключены к тактовому генератору и сбросу (который я повесил на кнопку для удобства, чистая формальность), точка входа настраивается вручную. Выходы подключены к памяти и стеку, на них, в зависимости от команд, будут появляться нужные сигналы. Команда и операнды заполняются, в зависимости от того, куда показывает указатель инструкций ip. Регистры меняют свое значение, в зависимости от команд, и операндов. ip тоже может менять свое значение, в зависимости от команды, но по-умолчанию он просто увеличивается на 1 на каждом шаге, а начинается все с точки входа, которую указывает человек. Т.о. программа может располагаться в произвольном месте листа, главное — адрес первой ячейки указать в c_main.
Список команд поддерживаемый процессором:
mov - поместить значение в регистр, первый операнд имя регистра, второй - значение, например mov ax 666 movm - поместить значение по адресу в памяти, первый операнд - адрес в памяти, второй операнд значение jmp - переход, один операнд - новое значение ip, второй операнд отсутствует (но в ячейке все-равно должно что-то быть! Магия Calc, которую я не разгадал...) push - достать значение из стека и положить в регистр общего назначения, единственный операнд - название регистра (ax, bx или cx), магия со вторым оператором такая же pop - положить значение в стек, операнд - значение mmov - достать значение из памяти и положить в регистр, первый операнд - адрес памяти, второй операнд - название регистра
В качестве операндов и команд, в программе можно указывать формулу, главное — чтобы в ячейке в результате получилось значение, именно значения будут попадать на обработку в процессор.
Начнем с простых внутренних структур: cur_col=COLUMN(INDIRECT(ip)) и cur_row=ROW(INDIRECT(ip)) это просто текущий ряд и текущая колонка. command=IFERROR(INDIRECT(ADDRESS(ROW(INDIRECT(ip));COLUMN(INDIRECT(ip)); 1;0); 0); null) здесь уже видно различие теории и практики. Во-первых, пришлось вставить проверку на ошибки. Во-вторых, в формуле пришлось отказаться от предыдущих значений cur_col и cur_row — это приводило к каким-то хитрым циклическим зависимостям и не давало корректно работать ip, впрочем речь об ip ниже. В-третьих, здесь я применил специальное значение null (в случае ошибки), для него выделена отдельная ячейка с «-1».
Значения операндов формируются из текущей строки и колонки со смещением:
opA=IFERROR(INDIRECT(ADDRESS(cur_row; cur_col + 1; 1;0); 0); null) opB=IFERROR(INDIRECT(ADDRESS(cur_row; cur_col + 2; 1;0); 0); null)
Формула для instruction pointer:
ip=IF(c_reset = 1; // проверка на сброс
c_main; // если был сброс, то возвращаемся на мейн
IF(AND(c_clock = 1;ip=oldip); // в противном случае проверяем надо ли обновлять значение (взведен клок и старое значение совпадает с текущим)
IF(command="jmp"; // если значение менять надо, то проверяем является ли ткущая команда переходом
opA; // если текущая команда jmp, тогда берем новое значение из операнда
ADDRESS(ROW(INDIRECT(ip))+1; // если текущая команда не jmp, тогда просто переходим на следующий ряд
COLUMN(INDIRECT(ip))));
ip)) // если значение обновлять не надо, то оставляем старое
Фактически, эта длинная формула у меня разнесена по нескольким ячейкам, но можно и все в одну записать.
opdip=IF(c_clock = 0; ip; oldip)
Формулы для регистров, также проверяют какая команда является текущей, но учитывается уже больше команд, поэтому уровень вложенности IF совсем нечитабельный. Здесь я приведу пример, как я разносил длинные формулы по нескольким ячейкам:
Регистры общего назначения
Адреса ячеек чисто условные, для примера.
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 1 | =IF(c_reset = 1; 0; B1) | =IF (c_clock = 1; C1; ax) | = IF(c_clock=1; IF (opA = «ax»; D1; IF(opB = «ax»; E1; ax));ax) | =IF(AND(opA = «ax»;c_clock=1);IF (command = «pop»; pop_value; IF (command = «mov»; opB; ax)); ax) | = IF(AND(opB=«ax»;command = «mmov»); mem_value; ax) |
Здесь A1 и является, собственно, регистром ax, а остальные это вспомогательные ячейки.
Копия регистра rax=IF(c_reset= 1; 0; IF(AND(rax<>ax; c_clock=0); ax; rax))
Думаю тут совсем не сложно догадаться что происходит. Остальные регистры bx и cx устроены аналогичным образом.
Осталось дело за малым — выходные сигналы процессора:
| push_value | =IFERROR(IF(command=«push»; opA; push_value);null) |
| push_c | =IF(command=«push»; c_clock; 0) |
| pop_c | =IF(AND(command=«pop»; c_clock = 1); 1; 0) |
| mem_addr | =IF(c_reset = 1; 0; IF(OR(command = «movm»; command = «mmov»); opA; mem_addr)) |
| mem_value | =IF(c_reset = 1; 0; IF(command = «movm»; opB; IF(command=«mmov»; m_value_out; mem_value))) |
| mem_set | =IF(c_reset = 1; 0; IF(command = «movm»; 1; 0)) |
Это сигналы для работы с памятью и стеком. На первый взгляд, сигналы push_c и pop_c, вроде бы, одинаковы по-сути, но формулы в них немножко разные. Могу лишь ответить, то, что они получены методом многочисленных проб и ошибок. В процессе отладки всей этой конструкции было много багов, и они еще остались, к сожалению процессор не всегда работает «как часы». По каким-то причинам, я остановился именно на таком варианте, значит «по-другому» что-то не работало. Сейчас уже не смогу точно вспомнить — что именно.
Картинка моего процессора:
![bd856de810d24284bf8f21fac1260bcd[1]](http://waksoft.susu.ru/wp-content/uploads/2015/04/bd856de810d24284bf8f21fac1260bcd1.png)
Здесь видно еще debug поля — в них выводятся не значения, а формулы в виде текста.
Программирование
Итак, компьютер готов, можно приступать к написанию программы. В процессе программирования обнаружилось несколько проблем, некоторые из которых были решены, некоторые все же остались:
- Иногда «компьютер» глючит и ведет себя непредсказуемо
- Надо чтобы на листе было видно почти все, включая программу, иначе ячейки, которые далеко за пределом видимости не обновляют свое содержимое
- «Компьютер» получился медленный, уменьшение задержки между тиками приводит к тому, что дисплей и некоторые формулы не успевают обновляться. Опытным путем я подобрал, более менее, оптимальную задержку для своего ноутбука: 150-200 мс
Так как каждая строчка «программы» выполняется за один «тик», то строчек должно быть как можно меньше, по возможности надо стараться запихать как можно больше в одну формулу. Главной проблемой оказалось, что код для «Тетриса» получается слишком большой и может совсем не поместится на лист, поэтому было решено (после того, как намучался с «Тетрисом») написать «Змейку» и постараться использовать минимальное число строк для этого.
Интерфейс ввода, т.е. кнопки управления, пришлось сделать на макросах: 4 кнопки со стрелками и 4 ячейки в которые помещается 1, если кнопка нажата, которые я назвал key_up, key_down, key_left и key_right. К ним был прикручен триггер key_trigger=IF(key_up; «U»; IF(key_down; «D»; IF(key_left; «L»; IF(key_right; «R»; key_trigger)))), в котором сохраняется последняя нажатая клавиша.
Также я сделал кнопку «Debug», для отладки программы, с помощью нее можно руками управлять тактовым генератором и смотреть как меняются состояния ячеек (она заносит попеременно 1 или 0 в ячейку clock). Это все за что отвечают макросы: тактовый генератор и органы управления. Больше макросов не будет.
Начал разработку «Змейки» с псевдокода:
Псевдокод ‘Змейки’
Для «Змейки» нужны следующие сущности: координаты головы; координаты хвоста; массив, где хранятся координаты всех точек змейки; координаты мячика.
HEAD // ядрес ячейки памяти с координатами головы TAIL // ядрес ячейки памяти с координатами хвоста BXBY = rand // координаты мячика HXHY = *HEAD // координаты головы TXTY = *TAIL // координаты хвоста loop: read DIRECTION // считываем направление (клавишу) HEAD++ // увеличиваем указатель головы на единицу HXHY += DIRECTION // векторно прибавляем направление к координатам головы [HEAD] = HXHY // сохраняем в память новые координаты головы BXBY <> HXHY ? JMP cltail // если координаты головы не совпали с координатами мячика, то прыгаем на "стирание хвоста" BXBY = rand // генерируем новые координаты мячика [BY] = OR([BY]; 9-2^BX) // рисуем мячик на экране (первые 20 ячеек памяти отображаются на экране 10х20) JMP svtail //перепрыгиваем стирание хвоста cltail: [TY] = AND([TY]; XOR(FFFF; (9-2^TX))) // стираем хвост с экрана TAIL++ // увеличиваем указатель хвоста TXTY = [TAIL] // берем новые координаты хвоста из памяти svtail: [HY] = OR([HY]; 9-2^HX) // рисуем голову на экране JMP loop // переходим на начало цикла
Вот такой несложный алгоритм получился.
Хранить данные я решил в аггрегированном виде в регистрах, например регистр ax хранит BXBYHHTT, то есть фактически 4 двузначных переменных: координаты мячика (BX и BY), номер ячейки с координатами головы (HH), номер ячейки с координатами хвоста (TT). Это усложняет доступ к переменным, но позволяет уменьшить число строк программы.
Далее нужно было этот алгоритм детализировать. Начнем с инициализации:
Инициализация
| Command | Operand 1 | Operand 2 | Comment |
| mov | ax | =RANDBETWEEN(0;9) * 1000000 + RANDBETWEEN(0;19)* 10000 + 2120 | BXBYHHTT |
| movm | 21 | 509 | Head: x — 5, y — 9 |
| movm | 20 | 409 | Tail: x — 4; y — 9 |
| mov | cx | R | direction init |
| mov | bx | 5090409 | HXHYTXTY |
| movm | =MOD(ROUNDDOWN(rax/10000);100) | =2^(9-ROUNDDOWN(rax/1000000)) | draw ball |
Дальше начинается основной цикл. Сначала я просто взял свой псевдокод и начал детализировать каждую его строчку с учетом формул Calc и архитектуры своего процессора. Вид у этого всего вышел страшный:
Псевдокод приближенный к рабочему
loop:
cx = IF(OR(AND(rcx="U";key_trigger="D");AND(rcx="D";key_trigger="U");AND(rcx="L";key_trigger="R");AND(rcx="R";key_trigger="L"));rcx;key_trigger)
ax = IF(ROUND(MOD(rax;10000)/100) < 89; ROUND(MOD(rax;10000)/100)+1; 20) * 100 + MOD(rax;100) + ROUND(rax/10000) * 10000
bx = IF(AND(rcx="U";MOD(ROUND(rbx/10000);100)>0);rbx-10000;IF(AND(rcx="D";MOD(ROUND(rbx/10000);100)<19);rbx+10000;IF(AND(rcx="R";ROUND(rbx/1000000)<9);rbx+1000000;IF(AND(rcx="L";ROUND(rbx/1000000)>0);rbx-1000000;"FAIL"))))
push cx
[ROUND(MOD(rax; 10000)/100)] = ROUND(rbx/10000)
jmp IF(ROUND(rax/10000) <> ROUND(rbx/10000); ctail; next)
ax = MOD(rax;10000) + MOD(MOD(ROUND(rax/10000);100)*11 + 3; 20) * 10000 + MOD(ROUND(rax/1000000)*3+2;10)*1000000 // ball generator
cx = [MOD(ROUND(rax/10000);100)] // get [BY]
[MOD(ROUND(rax/10000);100)] = BITOR(rcx; 2^(9-ROUND(rax/1000000))) // draw ball on scr
jmp svtail
ctail:
cx = [MOD(rbx;100)] // cx = [TY]
[MOD(rbx;100)] = BITAND(rcx; BITXOR(HEX2DEC("FFFF"); 2^(9-ROUND(MOD(rbx;10000)/100)))) // clear tail on scr
ax = IF(MOD(rax;100) < 89; rax + 1; ROUND(rax/100)*100 + 20)
cx = [MOD(rax;100)] // cx = [TT]
bx = ROUND(rbx/10000)*10000 + rcx
svtail:
cx = [MOD(ROUND(rbx/10000);100)] // cx = [HY]
[MOD(ROUND(rbx/10000);100)] = BITOR(rcx; 2^(9-ROUND(rbx/1000000))) // draw head on scr
pop cx
jmp loop
Здесь я заменил переменные псевдокода на регистры, в ax решил хранить 4 двузначных числа: BXBYHHTT, в bx HXHYTXTY, то есть координаты головы и хвоста, а в cx — направление, ну и использовать его для промежуточных нужд. Например, когда надо переложить из памяти в память, напрямую этого сделать нельзя, приходится делать через регистр.
Дальнейшим шагом было только заменить присваивания на команды mov, movm и mmov соответственно и перенести код в ячейки на листе.
Из интересных особенностей стоит отметить генератор случайных чисел. Функция табличного процессора нам не подходит, потому что на каждой генерации координат мячика в программе надо иметь новые случайные значения. А функция вычисляется лишь раз и потом лежит в ячейке, пока не обновишь лист. Поэтому здесь был прменен т.н. .
Для упрощения, проверок на то, что мячик появился посреди змеи не делается. Также не делается проверок на проход змеи сквозь себя.
Работает программа очень «слоупочно». Я записал видео в реальном времени и ускоренное в 16 раз. В конце видео я прохожу сквозь себя и врезаюсь в стену (в регистре bx появляестя «FAIL» и змейка больше никуда не ползет).
Ускоренное в 16 раз видео:
Реальное время
На видео можно видеть, что внизу листа есть код еще одной маленькой программы — вывод бегущей ползущей строки. Там применен некоторый «хак», а именно: в программе используются данные из соседних ячеек, но, в конце концов, почему бы и нет? Ведь никто этого и не запрещал.
Видео ускорено в 16 раз:
Проект доступен на , для работы требуется LIbreOffice Calc с установленным BeanShell.
Оригинал:
Глобальная значимость английского, немецкого, русского, китайского и других языков в Интернете (Data Mining)
![98fdf861bfb24fbbbfb1d0e45ffe9b67[1]](http://waksoft.susu.ru/wp-content/uploads/2015/04/98fdf861bfb24fbbbfb1d0e45ffe9b671.jpeg)
Центральные языки на этой карте могут и не иметь самого большого количества носителей, однако они служат «общими» языками для общения элит.
В молодом направлении Big Data есть свои восходящие звезды и многообещающие лидеры, один из самых ярких это — профессор MIT Media Lab, разработчик онлайн-платформы визуализации данных о торговых связях между разными странами мира , и один из по версии журнала Wired.
Несколько лет назад Цезарю и его боевым товарищам захотелось исследовать взаимосвязь языковых узлов в Интернете. Языки отличаются по значимости по куче причин: начиная от технических и заканчивая демографическими. Задачу ставили себе амбициозную — определить глобальную значимость языка, которая не зависит от простых демографических и экономических показателей. О том, что из этого получилось, читайте в посте ниже.
Основная информация в трех глобальных языковых сетях (GLN) содержится на английском языке — центральном, а также нескольких менее распространенных: испанском, немецком, французском, русском, португальском и китайском. Значимость языка находится в прямой зависимости от числа популярных людей, говорящих на нём. Положение языка в GLN также способствует привлечению внимания к его носителям и к производимому ими культурному содержанию.
Первый вопрос, конечно, в том, как измерить глобальное влияние языка. До этого исследования опирались на численность и благосостояние носителей языка. Однако исторически сложилось так, что распространение языка требовало серьезной политической поддержки, поэтому такие показатели не сильно влияют на глобальность языка, так как его носители и их богатство могут быть сосредоточены в относительно малом масштабе. Другой метод измерения глобального влияния языка состоит в определении того, кто является его носителем, а также на связь между носителями. Лингвист Дэвид Кристалл утверждает: «Популярность языка не имеет ничего общего с количеством его носителей. Намного важнее то, кем они являются». В прошлом латынь была общеевропейским языком не потому, что она была родным языком для большинства европейцев, а потому, что являлась языком Римской империи, а позже Католической церкви, ученых и педагогов. Использование латыни элитами и связь между ними, помогли ей продержаться в качестве универсального языка более 1000 лет.
При этом в современном мире языковая карта выглядит примерно вот так (ещё раз):
![fd8449587a8d42ef9f8d2e40db3e37bf[1]](http://waksoft.susu.ru/wp-content/uploads/2015/04/fd8449587a8d42ef9f8d2e40db3e37bf1.jpeg)
Для начала посмотрим на коллекцию более 2,2 миллионов книжных переводов, составленную по проекту ЮНЕСКО. Этот набор данных позволяет отобразить сеть книжных переводов от авторов и профессиональных переводчиков. Он строился на основе рыночного спроса на книги на разных языках. Каждый перевод с одного языка на другой формирует связь. Затем мы наносим на карту мультиязычную сеть, используемую редакторами Википедии. Здесь связь между языками образуется, когда пользователь редактирует статью в одной языковой версии Википедии и со значительной долей вероятности отредактирует ее в другой языковой версии. И наконец, мы наносим на карту сеть совместного использования языков в Твиттере. Здесь связь образуется, если пользователь пишет сообщение на одном языке и с большой долей вероятности напишет его на другом.
Языки имеют непропорциональную степень влияния, поскольку некоторые обеспечивают прямые и косвенные пути перевода между большинством других языков мира. Например, чтобы слова испанца мог понять англичанин, нужен двуязычный носитель английского и испанского. Однако носителю языка мапудунгун могут стать понятны слова вьетнамца только через обходные пути, например по схеме: вьетнамский — английский, английский — испанский, испанский — мапудунгун. В обоих случаях испанский и английский языки вовлечены в процесс связи и выступают в роли глобальных языков.
![422cb1319d5c4220bccd6b8593a5c16a[1]](http://waksoft.susu.ru/wp-content/uploads/2015/04/422cb1319d5c4220bccd6b8593a5c16a1.png)
На этих иллюстрациях — сходство трех независимых наборов данных, которые мы используем для отображения GLN. Верхний ряд показывает зависимость между числом выражений для каждого языка во всех трех наборах данных: (А) редактирование статей в Википедии на языке и перевод книг с языка; (В) сообщения в Твиттере на языке и перевод книг с языка; (С) пользователи в Твиттере и редакторы в Википедии. Нижний ряд показывает соотношение между количеством одинаковых фраз для языковых пар в различных наборах данных: (D) общее количество книжных переводов и редакторов Википедии; (Е) общее количество пользователей Твиттера и книжных переводов; (F) пользователи Твиттера и редакторы Википедии. В D и Е мы систематизировали среднее количество переводов с языка и на язык.
Влияние глобальных языков
По логике, англичанину, как находящемуся на одном из узлов, легче влиять на языковую сеть, чем жителю Непала. Чем глобальнее язык, тем больше стимулов создавать на нем контент и переводить на него информацию с менее популярных языков. Например, репортер, желающий распространить новость о крупном мероприятии по всему миру, будет делать это на глобальном языке.
![68dae5cd4f754fd69c4e8f600e8b6370[1]](http://waksoft.susu.ru/wp-content/uploads/2015/04/68dae5cd4f754fd69c4e8f600e8b63701.png)
На иллюстрации положение языка в GLN и глобальное влияние его носителей. Верхний ряд показывает количество носителей языка (годы рождения 1800-1950), о которых написаны статьи по крайней мере в 26 языковых версиях Википедии, как функции центральности собственного вектора языка в (А) GLN Твиттера, (В) GLN Википедии и (С) GLN книжных переводов. Нижний ряд показывает количество носителей языка (годы рождения 1800-1950), о которых есть упоминания в «Human Accomplishmentas», как функции центральности собственного вектора языка в (D) GLN Твиттера, (E) GLN Википедии и (F) GLN книжных переводов. Размер зависит от количества носителей каждого языка, а интенсивность цвета — от ВВП на душу населения.
Затем Цезарь собрал данные Твиттеру из более чем одного миллиарда твитов, опубликованных между 6 декабря 2011 и 13 февраля 2012. Язык каждого твита был обнаружен с помощью Chromium Compact Language Detector после очистки от хештегов, ссылок и смайликов. Использовались только те сообщения, где шанс ложного срабатывания был менее 10%. Конечный набор данных состоит почти из 550 миллионов твитов на 73 языках, созданных более 17 миллионами уникальных пользователей. Два языка считаются связанными, если пользователь написал твит на одном языке и с большой долей вероятности напишет его на другом.
Набор данных из Википедии был составлен при редактировании истории всех языковых разделов Википедии, написанных в конце 2011 года. После удаления информации от ботов и применения фильтров, получилось 382 миллиона правок на 238 языках от 2,5 миллионов уникальных редакторов. Здесь два языка оказались связанными, если пользователь отредактировал статью на одном языке и с большой долей вероятности сделал это же на другом.
Набор данных индекса переводов (ИП) состоит из 2,2 миллионов переведенных книг, изданных между 1979 и 2011 в 150 странах более чем на тысяче языков. Набор данных содержит список переводов, а не список переведенных книг. Каждый перевод в нем учитывается отдельно, например, 22 независимых перевода «Анны Карениной» Толстого с русского на английский. В отображении сети мы учитываем каждый перевод отдельно, и в этом случае учитывались 22 перевода, а не один. Также отметим, что источник перевода может отличаться от языка оригинала книги. Например, в ИП содержатся данные о 15 переводах «Тома Сойера», причем 13 из них были сделаны непосредственно с английского, а 2 — с испанского и галисийского. Эта характеристика набора данных позволяет определить промежуточные языки для перевода.
Во всех трех случаях мы изобразили похожие языки в соответствии со стандартом ISO 639-3(10). Например, индонезийский и малазийский языки закодированы как малайский, а все диалекты арабского языка — как арабский.
Результаты
![5df521f648bb499290214de3d662c8dd[1]](http://waksoft.susu.ru/wp-content/uploads/2015/04/5df521f648bb499290214de3d662c8dd1.png)
На иллюстрации сосредоточенность и количество известных людей в GLN для каждого языка согласно Википедии. (A) Количество человек(рожденных в 1800-1950) для каждого языка, о которых есть статьи в по крайней мере 26 языковых вариантах Википедии в зависимости от ВВП на душу населения, численности населения и центральности собственного вектора для каждой GLN. Рейтинг культурного производства: (B) страны и (С) языки с наибольшим количеством людей, о которых есть статьи минимум в 26 языковых версиях Википедии. Собственный рейтинг значения языков в GLN: лучшие семь языков в (D) Твиттере, (E) Википедии и (F) сети книжных переводов.
Как видно из результатов, язык с большим количеством связей в одной GLN будет иметь много связей и в другой сети. Положительные корреляции выражений и связь в языковых парах говорят о том, что все три GLN подобны с точки зрения силы связей и количества представителей той или иной группы. Интересно, что общие черты, наблюдаемые в трех GLN, определяются, судя по всему, необходимостью наличия определенных литературных навыков для участия в каждой из этих сетей. Сеть книжных переводов является самой требовательной к этому фактору(поскольку в ней находятся авторы и профессиональные переводчики), Твиттер же наименее требователен(так как состоит из коротких сообщений, которые может публиковать любой человек с доступом в Интернет). Википедия является серединой между книжными переводами и Твиттером с точки зрения необходимых литературных навыков, а ее GLN также занимает середину с точки зрения подобия.
Есть гипотеза о том, что человек переводит информацию с центрального языка на свой родной, так как она больше заслуживает внимания, или гипотеза о том, что человек, родившийся в стране с центральным языком имеет больше шансов для достижения мировой известности.
Можно утверждать, что периферийное расположение языков хинди, китайского и арабского в GLN происходит из-за недостаточного представления в мире этих и некоторых других языков, которые к ним подключаются. Эти языки могут быть центральными в различных СМИ, однако их слабая роль в трех глобальных сетях — Твиттер, Википедия и сеть книжных переводов, ослабляет их претензии на глобальное влияние. Кроме того, китайский, арабский и хинди не могли бы быть центральными языками, даже если бы в базах данных была бы лучше указана их связь с различными региональными языками, так как центральный язык должен соединять даже очень отдаленные языки, а не только местные.
Лекция
Цезарь Хидальго может много рассказать про важность работы с большими данными. Он считает, что любой экономический рост — это частный случай роста информации во Вселенной. При этом рост информации в экономиках ограничивается способностью людей формировать социальные сети.
Цезарь будет выступать у нас в Digital October 22 апреля с (телемост) «Почему объем информации все время растет?». Язык – английский, плюс каждый участник получает радиоустройство синхронного перевода на русский, поэтому проблем с пониманием не будет. Регистрируйтесь на мероприятие и заходите в гости, будет интересно.
Оригинал:
Вести с полей или зачем нужна Бизнес-информатика

Оригинал:
Как и почему горожане конфликтуют на работе
Звоню подруге, секретарю в торговой фирме, и слышу, что в ее офисе идет бой. Мужские голоса стреляют друг в друга витиеватыми нецензурными тирадами, как громовержец Зевс молниями. Раздаются нервные шаги, потом оглушительный, как взрыв, грохот захлопнувшейся двери…
— Это начальник отдела продаж с логистами лается, — равнодушно комментирует подруга. — Каждый день одно и то же. То товар вовремя не привезли, то с позициями напутали…
Читать далее «Вести с полей или зачем нужна Бизнес-информатика»
